一、概况:
Elastic Search 是一个基于Apache Lucene™工具包的开源搜索引擎。无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene 只是一个库。想要使用它,你必须使用 Java 来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene 非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elastic Search 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTFul API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。Elastic Search 不仅仅是 Lucene 和全文搜索,它还具有以下特性:
① 分布式的实时文件存储,每个字段都被索引并可被搜索
② 分布式的实时分析搜索引擎
③ 可以扩展到上百台服务器,处理 PB 级结构化和非结构化数据
由于 Elastic Search 具有能够实时搜索、开源、稳定、快速、支持分布式等众多优点,所以许多国外著名的公司都在使用 Elastic Search。维基百科(Wikipedia)、StackOverflow、Github 等公司的全文检索、关键词高亮、实时键入搜索、自动纠错、相关内容推荐等功能都是基于 ElasticSearch 实现的。除此之外,ElasticSearch 也备受创业公司的青睐,它对机器的性能没有较严苛的要求,即使在普通 PC 机组成的集群中也可以正常运行。
二、原理简介:
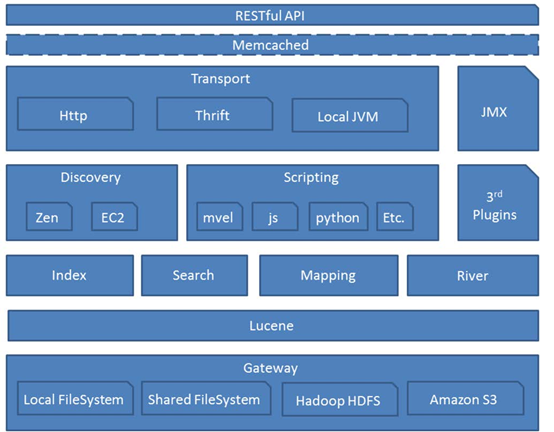
Elastic Search 结构示意图
在一个分布式Elastic Search集群中,有一个主节点(master),但是Elastic Search 是去中心化的,也就是说主节点是动态选举出来的,不存在单点故障的问题。节点与节点之间的通讯及节点之间的数据分配和平衡全部由Elastic Search 自动管理。Elastic Search 就是一个整体,主要有以下几个概念需要介绍一下。
Cluster:代表一个集群,集群中有多个节点。
节点(node):每一个运行实例都称为一个节点。所谓运行实例,也即是一个服务器进程。
Shards:索引分片,当面对海量数据时,其索引也会很大,因此我们需要把索引拆分成多个分片并将其分布在不同的节点上。这时我们在搜索海量数据时就可以实现分布式快速搜索了。
Replicas:索引副本,其作用是一方面提高系统的容错性,如果某个node 或者 Shards 不能工作了,Replicas 就可以快速恢复数据。另一方面,索引副本的存在还可以提高系统查询速度,因为 Elastic Search 具有负载均衡的功能,而索引副本可以代替索引分片进行搜索。
Recovery:代表数据恢复或者叫做数据重新分布,Elastic Search 可以重新分配索引分片以保证负载均衡。同时 Recovery 还可以自动恢复节点数据。
Gateway:代表着 Elastic Search索引快照存储方式,Elastic Search 默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway 对索引快照进行存储,当这个 Elastic Search 集群关闭再重新启动时就会从 gateway 中读取索引备份数据。
Transport:代表内部节点或集群与客户端交互的方式。
如上文所述,Elastic Search 内容检索集群还有如下几点优势:便捷的分布式安装部署,快速而强大的实时全文检索,能很好地融合 Hadoop 开发平台的存储集群。因此,这一分布式开源全文检索引擎框架成为许多大公司构建搜索引擎的首选。