由于最近入手NLP任务,需要看一些paper,本文对最近两周看的paper做个总结,适用于有deep learning背景,希望了解NLP应用的同学,主要针对NLP方向: 问答系统(QA)和翻译(Machine Translation)。本文提到的12篇paper比较有代表性,这里感谢总理和江哥提供部分参考paper和指导帮助。
论文列表:(其中QA为Question Answer的缩写)
Neural Machine Translation by Jointly Learning to Align and Translate
任务: 机器翻译
关键词:attention BiRNN
中心思想: English -> encoder -> decoder -> Chinese。其中encoder一般是一个RNN,读入一个词序列,输出一个表示该句话的vector;decoder一般也是一个RNN,输入该句话的表示vector,再以序列输出,每个时刻预测下一个词yt 。常用优化目标:令
p(y) 最大,其中
c是encoder输出的原句vector表示,
st 是decoder RNN的 hidden state,
yt−1 是t−1 时刻预测的翻译词,
g 是非线性函数。i.e., 基于{上一时刻预测词,当前decoder状态,输入句子(待翻译句子)的encoder vector表示} 确定当前时刻输出词。
方法:本文中,
encoder: 一个双向RNN,从前到后,从后往前各读一遍输入序列
decoder: encoder的c变成了ci , 即每个时刻(相对于输出序列)都有一个encoder的表示,它可以表示输入序列的所有词与输出序列中第i个词的关系。
其中,
αij 为alignment weight(学出来的), 表示位置j的input和位置i的output对应的score。 这样的好处是可以自动找出来每个输出词和输入序列中各词的关系,而不是对输入序列进行硬分割。
Applying Deep Learning to Answer Selection: A study and and open Task
任务:QA
关键词:answer selection, CNN
中心思想:计算QA之间的距离,选出最好的那个answer方法结论:
Q,A共享隐层CNN参数,good
CNN后接CNN, good
CNN后接hidden层(mixed),bad
layer-wise supervision(两层CNN,其输出都接入loss层),略好
度量距离时cos不一定是最好的,可以用metric learning学一个度量
Memory Networks
任务: 提出了一个长期记忆框架
关键词:Memory Network
中心思想: 用一个{I, G, O, R} framework表示memory。
I:input feature map
G:generalization 用来在指定位置更新memory
O:output feature map 寻找相关 memory
R:response 得到最终结果方法:I 和 G没啥好说的,主要inference部分在O和R。文中提出,O module通过找到与x相关的k个memory输出,这可以通过找与x最近的k个memory完成。最终输出r:
r=argmaxw∈WsR([x,mo1,mo2],w)
其中mo1,mo2 是O module输出的两个最相关的memory。
Large-scale Simple QA with Memory Networks
任务: 用MM进行大规模QA(MM是FB提的,所以基本上follow的都是FB的人)
关键词:Memory Network,metric learning,multi-task
中心思想: Memory Network进行简单QA. 基本上可以看做为MM做的一个pr… multi-task是说本文用了两个loss,一个是QA之间,一个是QQ之间,每个都是一个metric learning,使得(QA+/QQ+)pair 距离小于(QA-/QQ-)pair距离。
Answer Sequence Learning with Neural Networks for Answer Selection in Community Question Answering
任务:CQA问题(Community Question Answering)就是在一个社区data(每页是一个question和下面很多回复answer)中得到对每个question真正有用的answer。关键词:answer selection,CNN, LSTM, quality分类
中心思想: answer selection, 即选出几个有效的answers。本文用CNN feature表示QA pair,过一个LSTM得到每个answer的quality(共三档做分类)。方法:分两步,第一步生成QA-CNN-representation。第二步把这个question对应的所有answers的QA-CNN-representation形成一个sequence输入LSTM,每个时刻的输出为{good, bad, potential}分类of each answer。
Attentive Pooling Networks
任务:answer selection
关键词:answer selection,BiLSTM, attention, metric learning
中心思想: conv/BiLSTM + pooling + nonlinear + attention/alignment model => QA embedding space =>cosine distance方法:如中心思想所说,将Question和Answer分别embedding, conv或者biLSTM后得到其representation vector。之前有方法对这两个表示分别进行column-wise pooling得到
rq 和ra ,然后将cosine distance作为他们的相关性。本文中,将Question和Answer的representation vectorQ 和A 进行alignment,G=QTUA ,得到的G就是alignment matrix。然后对G分别进行column-wise和column-wise pooling 得到rq 和ra 再计算cosine distance。这样有attention module会更有针对性。
Towards AI-Complete QA: A set of Prerequisite Toy Tasks
任务:把问题按形式分类
方法:用了N-gram, LSTM, MemNN作比较,最后说MemNN最好(本文FB写的,哈哈)不过数据是模拟数据。。。分类倒是分得不错
Modeling Relational Information in QA Pairs with CNN
任务: answer selction
关键词:CNN, classify {q,a} pair
中心思想:学一个qa representation(conv),用label{0, 1}分类。
Teaching Machines to Read and Comprehend
DeepMind的工作
任务: 让机器做阅读理解,给机器一段document和一个question,让机器从document中找到能够回答这个question的answer关键词:attention,LSTM
中心思想:生成一个document和question的embedding space,然后用
p(a|d,q)=exp(W(a)emb(d,q)) 得到answera 。文中提出了三种得到embedding space的方法。方法:
1. Deep LSTM Reader: input是doc”||”q(doc后面连着question,中间隔着一个“||”), 输入到一个LSTM里,embedding就是那个LSTM输出的空间。
2. Attentive Reader: 对question 从前到后,从后向前各读一遍,得到representationu ,对doc也从前到后,从后向前各读一遍,然后用attentive model做alignment,得到representationr ,最后embedding是r 和u 的非线性组合空间。 PS:其中alignment weights和question encoder 和 doc encoder相关。(具体可参考原文和第1篇paper,有同曲异工之效)
3. Impatient Reader: 读question和document的方法和attentive reader都相同,但是每读question中一个word都重新更新一次r 。
Ask Me Anything: Dynamic Memory Networks for NLP
任务:阅读理解关键词:GRU, Dynamic Memory Network, Multilayer NN
中心思想:input为所有evidence组成的sequence(document的每句话为一个evidence),input hidden state 和 question representation 输入memory,memory输出到answer, 其中都走GRU, answer用分类。memory module内部走n遍,每遍内有attention机制,attention weight指各input hidden sequence(evidence)的权重。
方法:提出了一个Dynamic Memory Network,
Input:所有evidence句子作为sequence过GRU,有几个句子就生成几个hidden state;
Question:一句话,过GRU;
Episode: 以question output作为初始化,每次(共TM 次)过一轮GRU;
Answer:用mTM 作为初始化,根据具体情况决定输出y1...yn 还是yn 。
Sequence to Sequence Learning with NN
任务:翻译
关键词:多层LSTM,input reverse
方法:encoder,decoder均用LSTM;用多层LSTM(文中4层);reverse input sequence
A Neural Probabilistic Language Model
任务:学language model
关键词:统计语言模型
中心思想:通过最大化输出词概率(基于一个神经网络)学习word vector表示。方法:我们在之前将word2vec时就讲过这篇的工作,见word2vec——高效word特征求取
输入: n个之前的word在词库V中的index
映射: 通过|V|*D的矩阵C映射到D维
隐层: 映射层连接大小为H的隐层
输出: |V|个词语的概率
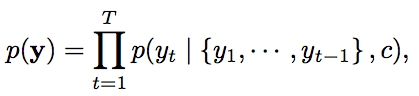
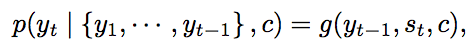

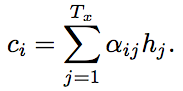
欢迎同学们推荐好文。