- 集合的由来
- 数组长度是固定,当添加的元素超过了数组的长度时需要对数组重新定义,太麻烦,java内部给我们提供了集合类,能存储任意对象,长度是可以改变的,随着元素的增加而增加,随着元素的减少而减少
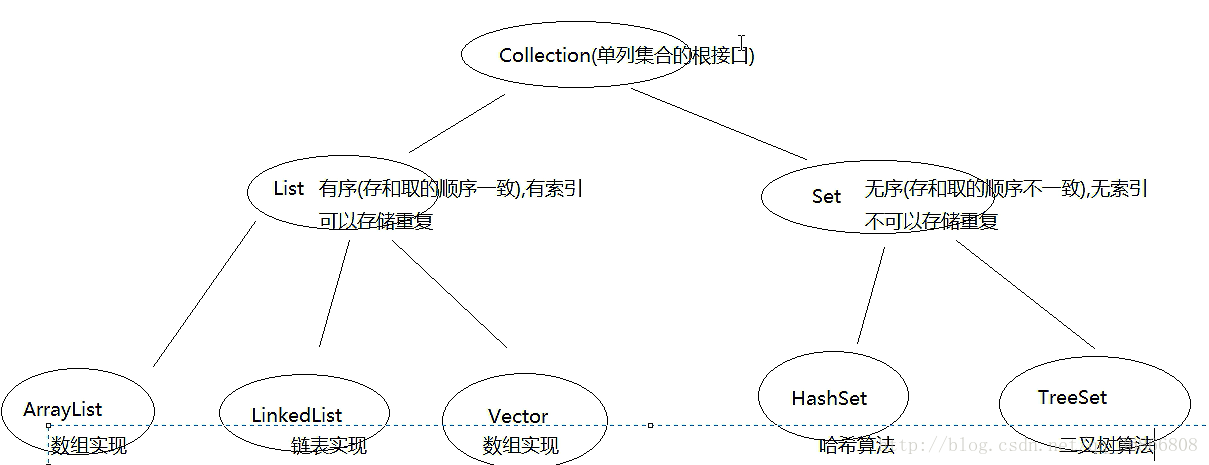
- 数组和集合的区别
- 区别1 :
- 数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值
- 集合只能存储引用数据类型(对象)集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象
- 区别2:
- 数组长度是固定的,不能自动增长
- 集合的长度的是可变的,可以根据元素的增加而增长
- 区别1 :
- C:数组和集合什么时候用
* 1,如果元素个数是固定的推荐用数组
* 2,如果元素个数不是固定的推荐用集合 - A:迭代器原理
- 迭代器原理:迭代器是对集合进行遍历,而每一个集合内部的存储结构都是不同的,所以每一个集合存和取都是不一样,那么就需要在每一个类中定义hasNext()和next()方法,这样做是可以的,但是会让整个集合体系过于臃肿,迭代器是将这样的方法向上抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做的好处有二,第一规定了整个集合体系的遍历方式都是hasNext()和next()方法,第二,代码有底层内部实现,使用者不用管怎么实现的,会用即可
- B:迭代器源码解析
- 查找iterator()方法
- 查看返回值类型是内部类new Itr(),说明Itr这个类实现Iterator接口
- 查找Itr这个内部类,发现重写了Iterator中的所有抽象方法
Iterator接口部分源码:
* @author Josh Bloch
* @see Collection
* @see ListIterator
* @see Iterable
* @since 1.2
*/
public interface Iterator<E> {
/**
* Returns {@code true} if the iteration has more elements.
* (In other words, returns {@code true} if {@link #next} would
* return an element rather than throwing an exception.)
*
* @return {@code true} if the iteration has more elements
*/
boolean hasNext();
/**
* Returns the next element in the iteration.
*
* @return the next element in the iteration
* @throws NoSuchElementException if the iteration has no more elements
*/
E next();Arraylist内部类
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* <p>The returned iterator is <a href="#fail-fast"><i>fail-fast</i></a>.
*
* @return an iterator over the elements in this list in proper sequence
*/
public Iterator<E> iterator() {
return new Itr();
}
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
内部类实现了iterator接口,重写了next,hassNext方法,扩展性贼鸡儿强,针对不同的集合,都有自己的实现。
- A:Vector类概述
B:Vector类特有功能
- public void addElement(E obj)
- public E elementAt(int index)
public Enumeration elements()
Vector的迭代
Vector v = new Vector(); //创建集合对象,List的子类
v.addElement("a");
v.addElement("b");
v.addElement("c");
v.addElement("d");
//Vector迭代
Enumeration en = v.elements(); //获取枚举
while(en.hasMoreElements()) { //判断集合中是否有元素
System.out.println(en.nextElement());//获取集合中的元素
}*去除ArrayList中重复自定义对象元素
* :案例演示
* 需求:ArrayList去除集合中自定义对象元素的重复值(对象的成员变量值相同)
* :注意事项
* 重写equals()方法的
List总结:
* A:List的三个子类的特点
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构)
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
Vector和ArrayList的区别
Vector是线程安全的,效率低
ArrayList是线程不安全的,效率高
共同点:都是数组实现的
ArrayList和LinkedList的区别
ArrayList底层是数组结果,查询和修改快
LinkedList底层是链表结构的,增和删比较快,查询和修改比较慢
共同点:都是线程不安全的
* B:List有三个儿子,我们到底使用谁呢?
查询多用ArrayList
增删多用LinkedList
如果都多ArrayList
- A:Set集合概述及特点
*此类实现Set接口,由哈希表(实际为HashMap实例)支持。 对集合的迭代次序不作任何保证; 特别是,它不能保证订单在一段时间内保持不变。 这个类允许null元素。不存在索引
*17.04_集合框架(HashSet如何保证元素唯一性的原理)
* 1.HashSet原理
* 我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
* 当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象
* 如果没有哈希值相同的对象就直接存入集合
* 如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
* 2.将自定义类的对象存入HashSet去重复
* 类中必须重写hashCode()和equals()方法
* hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)
* equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储
* A:LinkedHashSet的特点
* B:案例演示
* LinkedHashSet的特点
* 可以保证怎么存就怎么取
*TreeSet原理
* 1.特点
* TreeSet是用来排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列
* 2.使用方式
* a.自然顺序(Comparable)
* TreeSet类的add()方法中会把存入的对象提升为Comparable类型
* 调用对象的compareTo()方法和集合中的对象比较
* 根据compareTo()方法返回的结果进行存储
* b.比较器顺序(Comparator)
* 创建TreeSet的时候可以制定 一个Comparator
* 如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
* add()方法内部会自动调用Comparator接口中compare()方法排序
* 调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
* c.两种方式的区别
* TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
* TreeSet如果传入Comparator, 就优先按照Comparator
- A:Map接口概述
- 查看API可以知道:
- 将键映射到值的对象
- 一个映射不能包含重复的键
- 每个键最多只能映射到一个值
- 查看API可以知道:
- B:Map接口和Collection接口的不同
- Map是双列的,Collection是单列的
- Map的键唯一,Collection的子体系Set是唯一的
- Map集合的数据结构值针对键有效,跟值无关;Collection集合的数据结构是针对元素有效
- HashMap和Hashtable的区别
- Hashtable是JDK1.0版本出现的,是线程安全的,效率低,HashMap是JDK1.2版本出现的,是线程不安全的,效率高
- Hashtable不可以存储null键和null值,HashMap可以存储null键和null值
- B:Collections成员方法 *
public static <T> void sort(List<T> list)
public static <T> int binarySearch(List<?> list,T key)
public static <T> T max(Collection<?> coll)
public static void reverse(List<?> list) //翻转集合
public static void shuffle(List<?> list) //随机置换基本大致等同于Set Set底层实现依赖的是Map!