NTU-RGBD CVPR2016
总共大约有56000个视频,60类动作,50类是单人动作,10类是双人交互动作。每个人捕捉了25个关节点。数据集有两种分割方式,cross subject 和cross view ,这也是目前最大最全的一个数据集。很多动作识别的论文都是以这个数据集作为检测标准。
包含四种类型的数据,RGB videos、 depth map sequences 、3D skeletal data、infrared videos
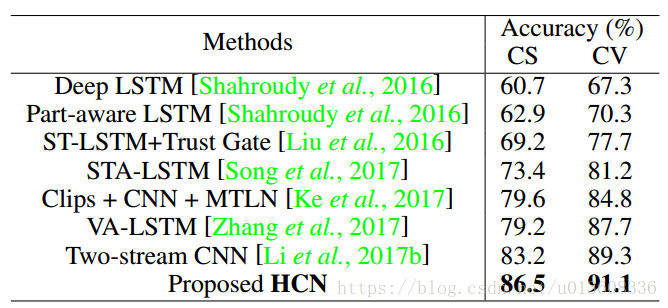
精度:
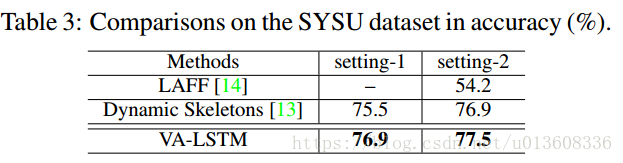
MSR-Action3D
20类动作,10个人,重复2到3次。总共有567个sequence,depth和skeleton 数据,没有RGB数据,其中有10个sequence有错误,skeleton丢失掉了,帧率15fps
SBU
共284个视频,8类动作,7个人,用5折交叉验证,最长46frame,本数据集的动作全是双人交互动作,有RGB、skeleton、depth图片。骨架关节点有15个
动作分类:靠近, 远离, 踢 ,推,握手,拥抱,递书本,拳击
x and y are normalized as [0,1] while z is normalized as [0,7.8125]

SYSU
kinect捕捉的数据集,包含12类动作,由40个人出演的。总共有480个sequence,每个人有20个关节点。40人,12个动作,480个video clip,6种object。手机,椅子,包,钱包,拖把,扫把。
0.9s-12s,但是背景非常杂乱。
这12个动作分别是:喝水,从一个杯子往另一个杯子倒水 ,打电话,玩手机,背书包,收拾书包,坐在椅子上,移动椅子,从口袋掏出钱包,从钱包里拿钱,拖地,扫地
1.拖把和扫把非常像
2.实验者40人远超于之前的人数
setting 1 :一半样本用来训练,一半用来测试
setting 2 :一般人物用来训练,一半人物用来测试
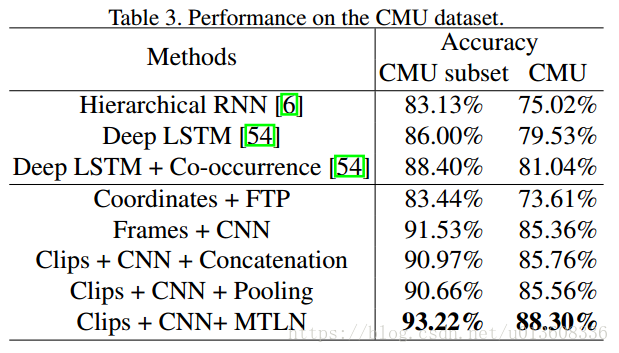
CMU dataset
总共有2235个sequence,其中subset有664个sequence
包括8个动作类别,在NTU-RGBD出现以前,这是最大的一个数据集,比较有挑战性,主要是因为1, 视频长度变化比较大,2,类内差距比较大,不同的人走路的姿势和速度都不同 3,包含了比较复杂的动作比如跳舞和瑜伽。
没有RGB视频
UTKinect
是由一个静止的kinect相机捕捉的,10个人物,10类动作
每个动作由同一个人表演两次。
10人,(每人做10个动作,这10个sequences 是连在一起的),每个人2个视频,总共20个sequence.
长度:5-120frames
本数据集有20个样本,所以要计算20次

HMDB05
2,337 skeleton sequences performed by 5 actors (184,046 frames after down-sampling
以下结果是2016年AAAI的一篇文章,结果比较老了
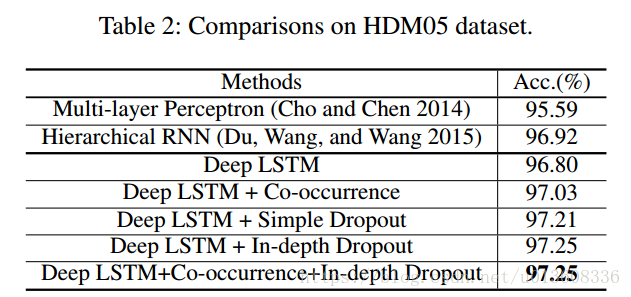
Berkeley MHAD
已经达到100%
参考文献
NTURGBD ,SBU 【Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation】
SYSU 【View Adaptive Recurrent Neural Networks for High Performance Human Action Recognition from Skeleton Data】
CMU 【A New Representation of Skeleton Sequences for 3D Action Recognition】
HMDB05 【Co-Occurrence Feature Learning for Skeleton Based
Action Recognition Using Regularized Deep LSTM Networks】