Linux下配置Python Spark 集成开发环境Pycharm
Pycharm下载:JetBrain官网http://www.jetbrains.com/pycharm/download/#section=linux
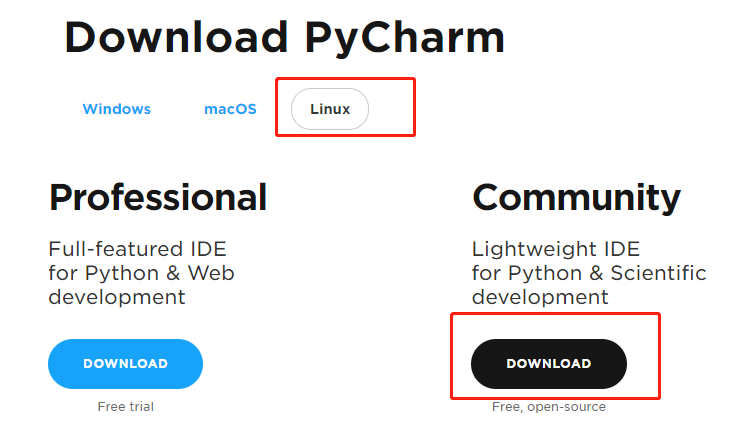
将下载之后的文件pycharm-community-2018.2.3.tar.gz移至主文件夹下进行解压安装:
tar xvf pycharm-community-2018.2.3.tar.gz
将Pycharm添加桌面快捷方式
- 终端输入命令(创建Pycharm.desktop):
sudo gedit /usr/share/applications/Pycharm.desktop - gedit编辑Pycharm.desktop键入以下内容:
[Desktop Entry]
Type=Application
Name=Pycharm
GenericName=Pycharm3
Comment=Pycharm3:The Python IDE
Exec=sh /home/我的用户名/pycharm-community-2018.2.3/bin/pycharm.sh
Icon=/home/我的用户名/pycharm-community-2018.2.3/bin/pycharm.png
Terminal=pycharm
Categories=Pycharm;
上述内容Exec指定pycharm.sh所在绝对路径,Icon指定pycharm.png所在绝对路径)。
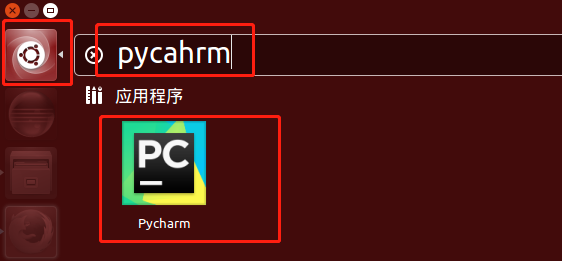
桌面菜单栏搜索拖拽即可。
在Pycharm中配置pyspark环境
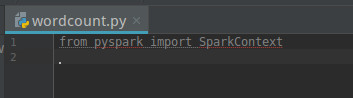
首先,不进行配置时,导入pyspark会出错(出现红线):
下面开始相关配置:
第一步,配置spark和pyspark环境变量:
点击pycharm右上角的“Add Configuration”或通过菜单栏“run”下拉点击选择“Add Configuration”,在新弹出的窗口左上角点击”+”号(“+ Python”),命名为Spark。勾选右边的“shared”选项。
接着在“Environment variables”一栏点击右边按钮进行环境变量配置。
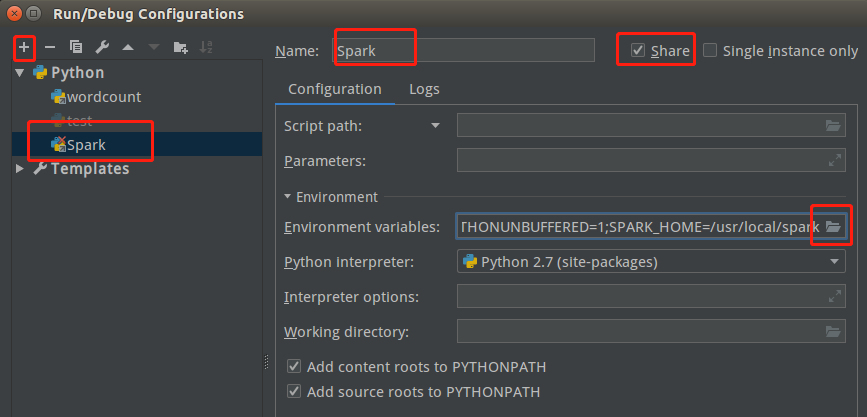
开始配置spark和pyspark环境变量,命名为SPARK_HOME和SPARKPYTHON,值分别为Spark安装的路径以及pyspark的路径
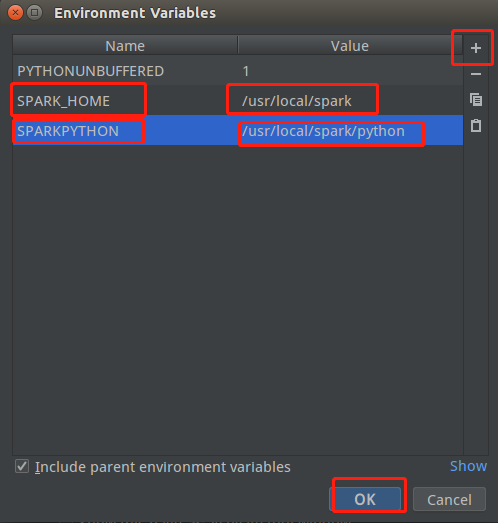
点击OK,完成环境配置。
第二步,导入相关的库(pyspark模块)
点击菜单栏”File”–>”Setting”–>”Project Structure”中点击右上角”Add Content Root”
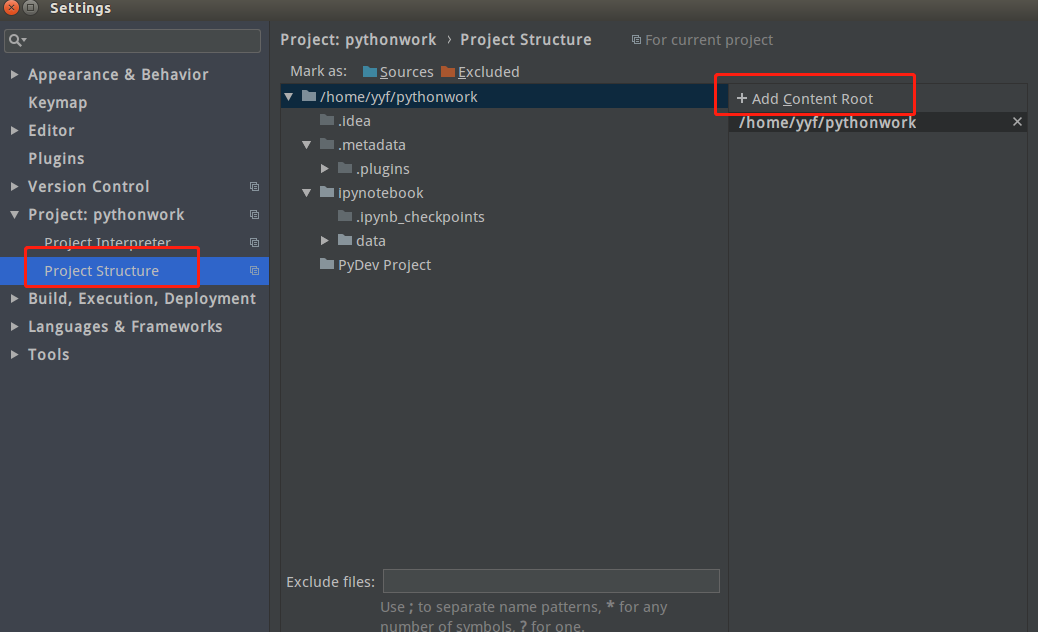
进入spark安装目录下的python中导入两个压缩包
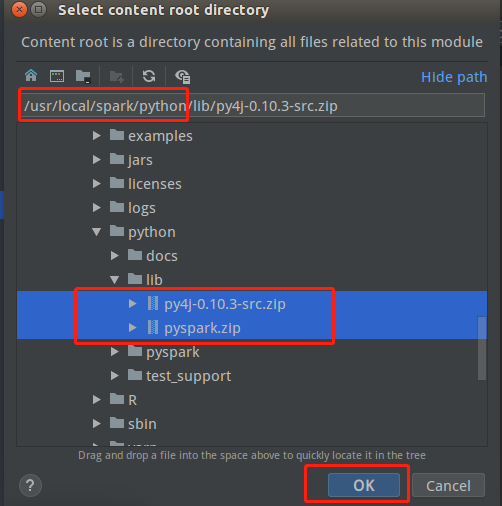
点击OK,完成配置。
此时,错误提示消失,说明环境配置成功。
使用Pycharm运行pyspark程序
创建wordcount.py程序文件输入以下代码:
# -*-coding: utf-8 -*-
from pyspark import SparkContext
from pyspark import SparkConf
def SetPath(sc):
"""定义全局变量Path,配置文件读取"""
global Path
if sc.master[0:5] == "local": # 当前为本地路径,读取本地文件
Path = "file:/home/yyf/pythonwork/PythonProject/"
else: # 不是本地路径,有可能是YARN Client或Spark Stand Alone必须读取HDFS文件
Path = "hdfs://master:9000/user/yyf/"
def CreateSparkContext():
"""定义CreateSparkContext函数便于创建SparkContext实例"""
sparkConf = SparkConf() \
.setAppName("WordCounts") \
.set("spark.ui.showConsoleProgress","false")
sc = SparkContext(conf=sparkConf)
SetPath(sc)
print("master="+sc.master)
return sc
if __name__ == "__main__":
print("开始执行WordCount")
sc = CreateSparkContext() # 创建SparkContext实例
print("开始读取文本文件...")
textFile = sc.textFile(Path+"README.md")
print("文本文件共 "+str(textFile.count())+" 行")
## 执行Map/Reduce运算
countsRDD = textFile.flatMap(lambda line: line.split(' ')) \
.map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y)
print("文字统计共 "+str(countsRDD.count())+" 项数据")
print("开始保存至文本文件...")
try:
countsRDD.saveAsTextFile(Path+"output")
except Exception as e:
print("输出目录已存在,先删除原有目录")
sc.stop()
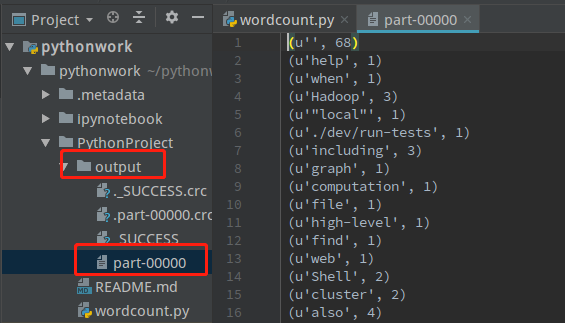
运行结果:
开始执行WordCount
开始读取文本文件...
文本文件共 99 行
文字统计共 275 项数据
开始保存至文本文件...在output文件中打开part-00000查看wordcount结果