概述
虽然现在都在说大内存时代,不过内存的发展怎么也跟不上数据的步伐吧。所以,我们就要想办法减小数据量。这里说的减小可不是真的减小数据量,而是让数据分散开来。分开存储、分开计算。这就是 MapReduce 分布式的核心。
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Q-WHai
发表日期: 2016年5月10日
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/51367732
来源:CSDN
更多内容:分类 >> 大数据之 Hadoop
目录
MapReduce 简介
要了解 MapReduce,首先要了解 MapReduce 的载体是什么。在 Hadoop 中,用于执行 MapReduce 任务的机器有两个角色:一个是 JobTracker,另一个是 TaskTracker。JobTracker 是用于管理和调度工作的,TaskTracker 是用于执行工作的。一个 Hadoop 集群中只有一台 JobTracker(当然在 Hadoop 2.x 中,一个 Hadoop 集群中可能有多个 JobTracker)。
MapReduce 原理
MapReduce 模型的精髓在于它的算法思想——分治。对于分治的过程可以参见我之前的一篇博客《大数据算法:对5亿数据进行排序》。还有就是可以去学习一下排序算法中的归并排序,在这个排序算法中就是基于分治思想的。
回归正题,在 MapReduce 模型中,可以把分治的这一概念表现得淋漓尽致。在处理大量数据的时候(比如说 1 TB,你别说没有这么多的数据,大公司这点数据也不算啥的),如果只是单纯地依赖我们的硬件,就显得有些力不从心了。首先我们的内存没有那么大,如放在磁盘上处理,那么过多的 IO 操作无疑是一个死穴。聪明的 Google 工程师总是给我们这些渣渣带来惊喜,他们想把了把这些数据分散到许多机器上,在这些机器上完成一些初步的计算,再经过一系列的汇总,最后在我们的机器上(Master/Namenode)统计结果。
要知道我们不可能把我们的数据分散到随意的 N 台机器上。那么我们就必须让这些机器之间建立一种可靠的关联,这样的关联形成了一个计算机集群。这样我们的数据就可以分发到集群中的各个计算机上了。在 Hadoop 里这一操作可以通过 -put 这一指令实现,关于这一点在下面的操作过程中也有体现。
当数据被上传到 Hadoop 的 HDFS 文件系统上之后,就可以通过 MapReduce 模型中的 Mapper 先将数据读进内存,过程像下面这样:
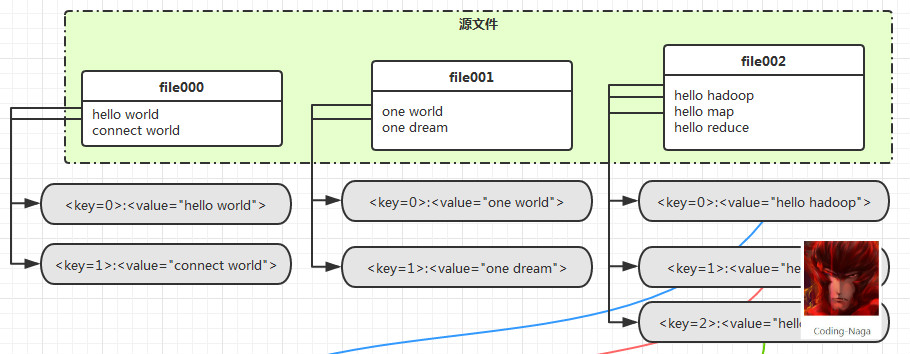
经过 Mapper 的处理,数据会变成这样
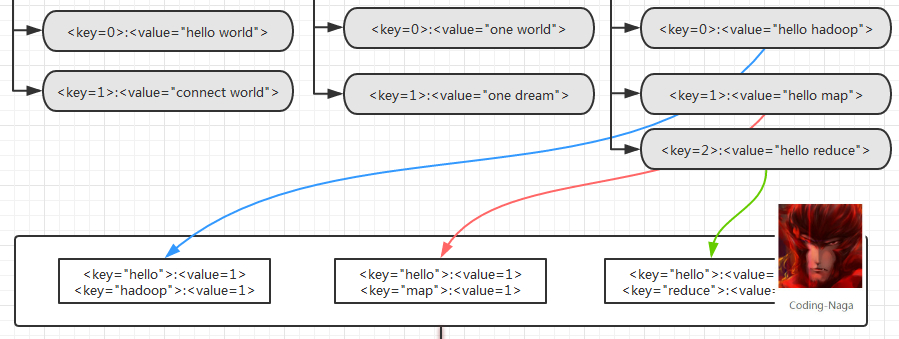
好了,到了这里,Map 的过程就已经结束了。接下来就是 Reduce 的过程了。
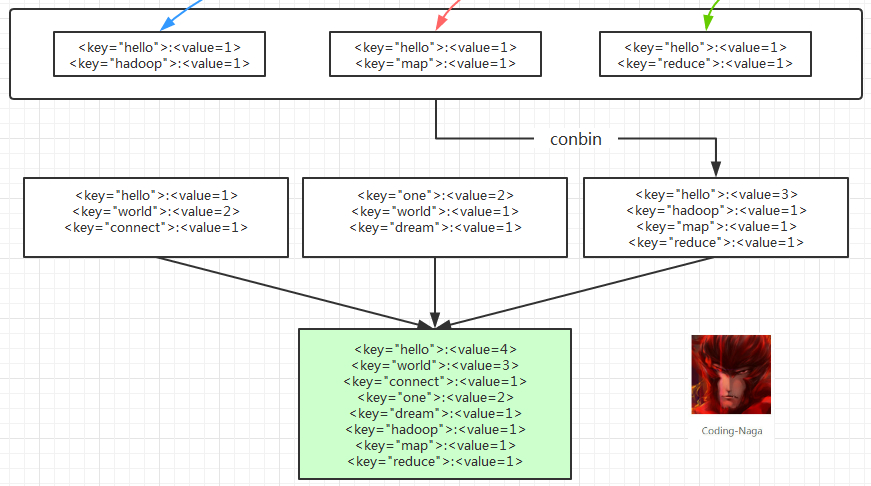
可以看到这里有一个 conbin 的过程,这个过程,也可以没有的。而有的时候是一定不能有的,在后面我们可以会单独来说说这里的 conbin,不过不是本文的内容,就不详述了。
这样整个 MapReduce 过程就已经 over 了,下面看看具体的实现及测试结果吧。
WordCount 程序
关于 WordCount 的 MapReduce 计算模型可参见本人的在线绘图工具:https://www.processon.com/view/572bf161e4b0739b929916ea
需求分析
- 现在有大量的文件
- 每个文件又有大量的单词
- 要求统计每个单词的词频
逻辑实现
Mapper
public static class CoreMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private static Text label = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
while(tokenizer.hasMoreTokens()) {
label.set(tokenizer.nextToken());
context.write(label, one);
}
}
}Reducer
public static class CoreReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable count = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
if (null == values) {
return;
}
int sum = 0;
for (IntWritable intWritable : values) {
sum += intWritable.get();
}
count.set(sum);
context.write(key, count);
}
}Client
public class ComputerClient extends Configuration implements Tool {
public static void main(String[] args) {
ComputerClient client = new ComputerClient();
args = new String[] {
AppConstant.INPUT,
AppConstant.OUTPUT
};
try {
ToolRunner.run(client, args);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public Configuration getConf() {
return this;
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] args) throws Exception {
Job job = new Job(getConf(), "ComputerClient-job");
job.setJarByClass(CoreComputer.class);
job.setMapperClass(CoreComputer.CoreMapper.class);
job.setCombinerClass(CoreComputer.CoreReducer.class);
job.setReducerClass(CoreComputer.CoreReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
}本地运行
关于本地运行没什么好说的,就是在 Eclipse 里配置好运行参数或是直接在代码里指定输入输出路径。然后 Run As 一个 Hadoop 程序即可。
分布式运行
在分布式运行 MapReduce 的过程中,主要有以下几个步骤:
1. 打包
2. 上传源数据
3. 分布式运行
打包
在打包的过程中,可以使用命令行打包,也可以使用 Eclipse 自带的 Export。在 Eclipse 的打包导出过程中,与打包导出一个 Java 的 jar 过程是一样的。这里就不多说了。假设我们打成的 jar 包为: job.jar
上传源数据
上传源数据是指将本地的数据上传到 HDFS 文件系统上。
在上传源数据之前我们需要在 HDFS 上新建你需要上传的目标路径,然后使用下面的这条指令即可完成数据的上传。
$ hadoop fs -mkdir <hdfs_input_path>
$ hadoop fs -put <local_path> <hdfs_input_path>如果这里之前你不进行创建目录,上传过程会因为找不到目录而出现异常情况。
数据上传完成后,这些数据会分布在你整个集群的 DataNode 上,而不只是在你的本地机器上了。
分布式运行
等上面的所有事情已经就绪,那么就可以使用下面的 hadoop 指令运行我们的 hadoop 程序。
$ hadoop jar job.jar <hdfs_input_path> <hdfs_output_path>结果视窗
打开浏览器
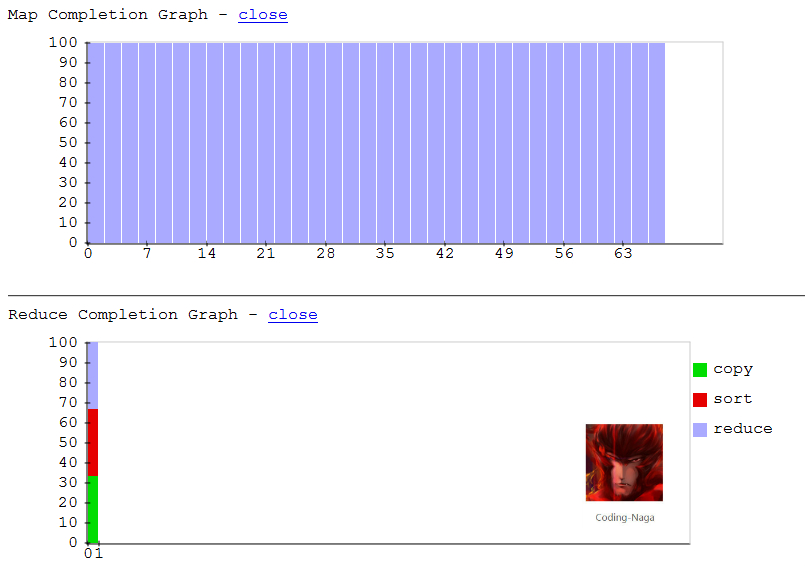
这里是程序中执行的过程中,进度的变化情况
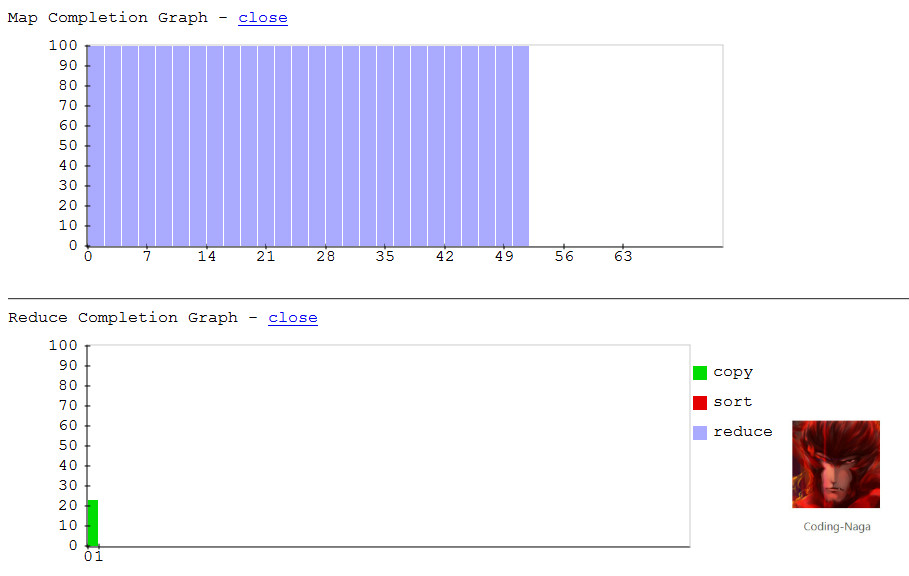
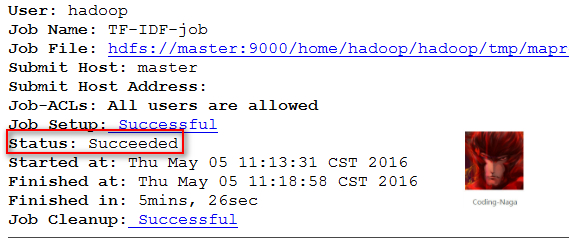
下面是程序执行完成时的网页截图
Ref
- 《Hadoop 实战》