AMQP即高级消息队列协议,接下来从三个方面来浅析该协议。
一、协议
AMQP协议分层类似于OSI或TCP/IP协议分层。从图中可以看出分三层:

图1 AMQP协议分层图
规范服务器端Broker的行为。
2、Session Layer
定义客户端与服务器端Broker的Context。
3、Transport Layer
传输二进制数据流。
二、模型
AMQP服务器Broker主要由Exchange和Message Queue组成,主要功能是Message的路由Routing和缓存Buffering。

图2 AMPQ服务器模型图
Message Queue会在Message不能被正常消费时将其缓存起来,但是当Consumer与Message Queue之间的连接通畅时,Message Queue将Message转发给Consumer。
Message由Header和Body组成,Header是由Producer添加的各种属性的集合,包括Message是否客被缓存、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。
Exchange与Message Queue之间的关联通过Binding来实现。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue,流程如下图:

图3 Messag处理流程图
Exchange Type分为Direct(单播)、Topic(组播)、Fanout(广播)。当为Direct(单播)时,Routing Key必须与Binding Key相等时才能匹配成功,当为Topic(组播)时,Routing Key与Binding Key符合一种模式关系即算匹配成功,当为Fanout(广播)时,不受限制。默认Exchange Type是Direct(单播)。
Virtual Host是个虚拟概念,可以持有一些Exchange和Message Queue。一个Virtual Host可以是一台服务器,也可以是由多台服务器组成的集群。Exchange和Message Queue可以分别部署在一台或者多台服务器上。
三、通信
在AMQP中,Client通过与Broker之间建立Connection来通信,而Connection建立在Client与Virtual Host之间。而在每个Connection上可以运行多个Channel,每个Channel执行与Broker的通信,Session依附于Channel之上。Channel是Client与Broker之间传输Message的实体。在通信的时候,会为每个Command分配一个唯一的标示符即UUID,用于Command做校验和重传。
Client默认使用guest/guest访问权限和访问虚拟主机的根目录,这些默认项也是RabbitMQ的默认安装选项。
AMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现。它主要包括以下组件:

AMQP 里主要要说两个组件:Exchange 和 Queue (在 AMQP 1.0 里还会有变动),如下图所示,绿色的 X 就是 Exchange ,红色的是 Queue ,这两者都在 Server 端,又称作 Broker ,这部分是 RabbitMQ 实现的,而蓝色的则是客户端,通常有 Producer 和 Consumer 两种类型:

1. Server(broker): 接受客户端连接,实现AMQP消息队列和路由功能的进程。
2. Virtual Host:其实是一个虚拟概念,类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Virtual Host
3.Exchange:接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,例如,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。
4.Message Queue:消息队列,用于存储还未被消费者消费的消息。
5.Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。
6.Binding:Binding联系了Exchange与Message Queue。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。
7.Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。
8.Channel:信道,仅仅创建了客户端到Broker之间的连接后,客户端还是不能发送消息的。需要为每一个Connection创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令。一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都需要与Broker交互,如果每一个线程都建立一个TCP连接,暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection。
9.Command:AMQP的命令,客户端通过Command完成与AMQP服务器的交互来实现自身的逻辑。例如在RabbitMQ中,客户端可以通过publish命令发送消息,txSelect开启一个事务,txCommit提交一个事务。

消息队列的使用过程大概如下:
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。
exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
exchange也有几个类型,完全根据key进行投递的叫做Direct交换机,例如,绑定时设置了routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。对key进行模式匹配后进行投递的叫做Topic交换机,符号”#”匹配一个或多个词,符号”*”匹配正好一个词。例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。还有一种不需要key的,叫做Fanout交换机,它采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列。
RabbitMQ支持消息的持久化,也就是数据写在磁盘上,为了数据安全考虑,我想大多数用户都会选择持久化。消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode=> 2(1是非持久化)
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
在了解了AMQP模型以后,需要简单介绍一下AMQP的协议栈,AMQP协议本身包括三层:

1. Modle Layer,位于协议最高层,主要定义了一些供客户端调用的命令,客户端可以利用这些命令实现自己的业务逻辑,例如,客户端可以通过queue.declare声明一个队列,利用consume命令获取一个队列中的消息。
2. Session Layer,主要负责将客户端的命令发送给服务器,在将服务器端的应答返回给客户端,主要为客户端与服务器之间通信提供可靠性、同步机制和错误处理。
3. Transport Layer,主要传输二进制数据流,提供帧的处理、信道复用、错误检测和数据表示。
AMQP所提供的域模型。
消息中间件的主要功能是消息的路由(Routing)和缓存(Buffering)。在AMQP中提供类似功能的两种域模型:Exchange 和 Message queue。 ")
Exchange接收消息生产者(Message Producer)发送的消息根据不同的路由算法将消息发送往Message queue。Message queue会在消息不能被正常消费时缓存这些消息,具体的缓存策略由实现者决定,当message queue与消息消费者(Message consumer)之间的连接通畅时,Message queue有将消息转发到consumer的责任。
Message是当前模型中所操纵的基本单位,它由Producer产生,经过Broker被Consumer所消费。它的基本结构有两部分: Header和Body。Header是由Producer添加上的各种属性的集合,这些属性有控制Message是否可被缓存,接收的queue是哪个,优先级是多少等。Body是真正需要传送的数据,它是对Broker不可见的二进制数据流,在传输过程中不应该受到影响。
一个broker中会存在多个Message queue,Exchange怎样知道它要把消息发送到哪个Message queue中去呢? 这就是上图中所展示Binding的作用。Message queue的创建是由client application控制的,在创建Message queue后需要确定它来接收并保存哪个Exchange路由的结果。Binding是用来关联Exchange与Message queue的域模型。Client application控制Exchange与某个特定Message queue关联,并将这个queue接受哪种消息的条件绑定到Exchange,这个条件也叫Binding key 或是 Criteria。
在与多个Message queue关联后,Exchange中就会存在一个路由表,这个表中存储着每个Message queue所需要消息的限制条件。Exchange就会检查它接受到的每个Message的Header及Body信息,来决定将Message路由到哪个queue中去。Message的Header中应该有个属性叫Routing Key,它由Message发送者产生,提供给Exchange路由这条Message的标准。Exchange根据不同路由算法有不同有Exchange Type。比如有Direct类似,需要Binding key 等于Routing key;也有Binding key与Routing key符合一个模式关系;也有根据Message包含的某些属性来判断。一些基础的路由算法由AMQP所提供,client application也可以自定义各种自己的扩展路由算法。
那么一个Message的处理流程类似于这样: ")
在这里有个新名词需要介绍: Virtual Host。一个Virtual Host可持有一些Exchange和Message queue。它是一个虚拟概念,一个Virtual Host可以是一台服务器,也可以是由多台服务器组成的集群。同步扩展下,Exchange与Message queue的部署也可以是一台或是多台服务器上。
Message的产生者和消费者可能是同一个应用。整个AMQP定义的就是Client application与Broker之间的交互。在粗略介绍完AMQP的域模型后,可以关注下Client是怎样与Broker建立起连接的。
在AMQP中,Client application想要与Broker沟通,就需要建立起与Broker的connection,这种connection其实是与Virtual Host相关联的,也就是说,connection是建立在client与Virtual Host之间。可以在一个connection上并发运行多个channel,每个channel执行与Broker的通信,我们前面提供的session就是依附于channel上的。
这里的Session可以有多种定义,既可以表示AMQP内部提供的command分发机制,也可以说是在宏观上区别与域模型的接口。正常理解就是我们平时所说的交互context,主要作用就是在网络上可靠地传递每一个command。在AMQP的设计中,应当是借鉴了TCP的各种设计,用于保证这种可靠性。
在Session层,为上层所需要交互的每个command分配一个惟一标识符(可以是一个UUID),是为了在传输过程中可以对command做校验和重传。Command发送端也需要记录每个发送出去的command到Replay Buffer,以期得到接收方的回馈,保证 这个command被接收方明确地接收或是已执行这个command。对于超时没有收到反馈的command,发送方再次重传。如果接收方已明确地回馈信息想要告知command发送方但这条信息在中途丢失或是其它问题发送方没有收到,那么发送方不断重传会对接收方产生影响,为了降低这种影响,command接收方设置一个过滤器Idempotency Barrier,来拦截那些已接收过的command。
NOVA是OpenStack系统的核心模块,主要负责虚拟机实例的生命周期管理、网络管理(前几个版本)、存储卷管理(前几个版本)、用户管理以及其他相关云平台管理功能,在能力上类似于Amazon EC2和Rackspace Cloud Servers。
消息队列(Queue)与数据库(Database)作为Nova总体架构中的两个重要组成部分,二者通过系统内消息传递和信息共享的方式实现任务之间、模块之间、接口之间的异步部署,在系统层面大大简化了复杂任务的调度流程与模式,是整个OpenStack Nova系统的核心功能模块。终端用户(DevOps、Developers和其他OpenStack组件)主要通过Nova API实现与OpenStack系统的互动,同时Nova守护进程之间通过消息队列和数据库来交换信息以执行API请求,完成终端用户的云服务请求。
Nova采用无共享、基于消息的灵活架构,意味着Nova的组件有多种安装方式,可以将每个Nova-Service模块单独安装在一台服务器上,同时也可以根据业务需求将多个模块组合安装在多台服务器上。
1.RabbitMQ
OpenStack Nova系统目前主要采用RabbitMQ作为信息交换中枢。
RabbitMQ是一种处理消息验证、消息转换和消息路由的架构模式,它协调应用程序之间的信息通信,并使得应用程序或者软件模块之间的相互意识最小化,有效实现解耦。
RabbitMQ适合部署在一个拓扑灵活易扩展的规模化系统环境中,有效保证不同模块、不同节点、不同进程之间消息通信的时效性;而且,RabbitMQ特有的集群HA安全保障能力可以实现信息枢纽中心的系统级备份,同时单节点具备消息恢复能力,当系统进程崩溃或者节点宕机时,RabbitMQ正在处理的消息队列不会丢失,待节点重启之后可根据消息队列的状态数据以及信息数据及时恢复通信。
RabbitMQ在功能性、时效性、安全可靠性以及SLA方面的出色能力可有效支持OpenStack云平台系统的规模化部署、弹性扩展、灵活架构以及信息安全的需求。
2.AMQP
AMQP是应用层协议的一个开放标准,为面向消息的中间件而设计,其中RabbitMQ是AMQP协议的一个开源实现,OpenStack Nova各软件模块通过AMQP协议实现信息通信。AMQP协议的设计理念与数据通信网络中的路由协议非常类似,可归纳为基于状态的面向无连接通信系统模式。不同的是,数据通信网络是基于通信链路的状态决定客户端与服务端之间的链接,而AMQP是基于消息队列的状态决定消息生产者与消息消费者之间的链接。对于AMQP来讲,消息队列的状态信息决定通信系统的转发路径,链接两端之间的链路并不是专用且永久的,而是根据消息队列的状态与属性实现信息在RabbitMQ服务器上的存储与转发,正如数据通信网络的IP数据包转发机制,所有的路由器是基于通信链路的状态而形成路由表,IP数据包根据路由表实现报文的本地存储与逐级转发,二者在实现机制上具有异曲同工之妙。
AMQP的目标是实现端到端的信息通信,那么必然涉及两个基本的概念:AMQP实现通信的因素是什么以及AMQP实现通信的实体以及机制是什么。
AMQP是面向消息的一种应用程序之间的通信方法,也就是说,“消息”是AMQP实现通信的基本因素。AMQP有两个核心要素——交换器(Exchange)与队列(Queue)通过消息的绑定与转发机制实现信息通信。其中,交换器是由消费者应用程序创建,并且可与其他应用程序实现共享服务,其功能与数据通信网络中的路由器非常相似,即接收消息之后通过路由表将消息准确且安全的转发至相应的消息队列。一台RabbitMQ服务器或者由多台RabbitMQ服务器组成的集群可以存在多个交换器,每个交换器通过唯一的Exchange ID进行识别。
交换器根据不同的应用程序的需求,在生命周期方面也是灵活可变的,主要分为三种:持久交换器、临时交换器与自动删除交换器。持久交换器是在RabbitMQ服务器中长久存在的,并不会因为系统重启或者应用程序终止而消除,其相关数据长期驻留在硬盘之上;临时交换器驻留在内存中,随着系统的关闭而消失;自动删除交换器随着宿主应用程序的中止而自动消亡,可有效释放服务器资源。
队列也是由消费者应用程序创建,主要用于实现存储与转发交换器发送来的消息,队列同时也具备灵活的生命周期属性配置,可实现队列的持久保存、临时驻留与自动删除。
由以上可以看出,消息、队列和交换器是构成AMQP的三个关键组件,任何一个组件的实效都会导致信息通信的中断,因此鉴于三个关键组件的重要性,系统在创建三个组件的同时会打上“Durable”标签,表明在系统重启之后立即恢复业务功能。
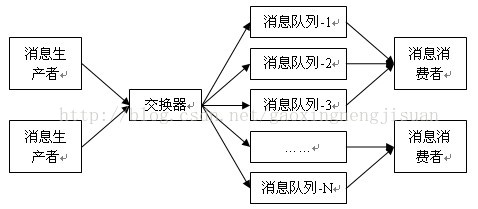
由图中可以看出,交换器接收发送端应用程序的消息,通过设定的路由转发表与绑定规则将消息转发至相匹配的消息队列,消息队列继而将接收到的消息转发至对应的接收端应用程序。数据通信网络通过IP地址形成的路由表实现IP报文的转发,在AMQP环境中的通信机制也非常类似,交换器通过AMQP消息头(Header)中的路由选择关键字(Routing Key)而形成的绑定规则(Binding)来实现消息的转发,也就是说,“绑定”即连接交换机与消息队列的路由表。消息生产者发送的消息中所带有的Routing Key是交换器转发的判断因素,也就是AMQP中的“IP地址”,交换器获取消息之后提取Routing Key触发路由,通过绑定规则将消息转发至相应队列,消息消费者最后从队列中获取消息。AMQP定义三种不同类型的交换器:广播式交换器(Fanout Exchange)、直接式交换器(Direct Exchange)和主题式交换器(Topic Exchange),三种交换器实现的绑定规则也有所不同。
3.Nova中的RabbitMQ应用
3.1RabbitMQ在Nova中的实现
RabbitMQ是OpenStackNova系统的信息中枢,目前Nova中的各个模块通过RabbitMQ服务器以RPC(远程过程调用)的方式实现通信,而且各模块之间形成松耦合关联关系,在扩展性、安全性以及性能方面均体现优势。由前文可知,AMQP的交换器有三种类型:Direct、Fanout和Topic,而且消息队列是由消息消费者根据自身的功能与业务需求而生成。
首先说说三个比较重要的概念:
交换器:
接受消息并且将消息转发给队列。在每个寻你主机的内部,交换器有唯一对应的名字。应用程序在他的权限范围之内可以创建、删除、使用 和共享交换器实例。交换器可以是持久的,临时的或者自动删除的。持久的交换器会一直存在于Server端直到他被显示的删除;临时交换器在服务器关闭时停 止工作;自动删除的交换器在没有应用程序使用它的时候被服务器删除。
队列:
“消息队列”,它是一个具名缓冲区,它代表一组消费者应用程序保存消息。这些应用程序在它们的权限范围内可以创建、使用、共享消息队列。类似于交换器,消息队列也可以是持久的,临时的或者自动删除的。临时消息队列在服务器被关闭时停止工作;自动删除队列在没有应用程序使用它的时候被服务器自动删 除。消息队列将消息保存在内存、硬盘或两者的组合之中。消息队列保存消息,并将消息发给一个或多个客户端,特别的消息队列会跟踪消息的获取情况,消息要出对就必须被获取,这样可以阻止多个客户端同时消费同一条消息的情况发生,同时也可以被用来做单个队列多个消费者之间的负载均衡。
绑定:
可以理解为交换器和消息队列之间的一种关系,绑定之后交换器会知道应该把消息发给那个队列,绑定的关键字称为binding_key。在程序中我们这样使用:
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key=binding_key)
Exchange和Queue的绑定可以是多对多的关系,每个发送给Exchange的消息都会有一个叫做routing_key的关键字,交换器要想把消息发送给某个特定的队列,那么该队列与交换器的binding_key必须和消息的routing_key相匹配才OK。
介绍一下RabbitMQ的三种类型的交换器:
广播式交换器类型(fanout)
该类交换器不分析所接收到消息中的Routing Key,默认将消息转发到所有与该交换器绑定的队列中去。广播式交换器转发效率最高,但是安全性较低,消费者应用程序可获取本不属于自己的消息。
广播交换器是最简单的一种类型,就像我们从字面上理解到的一样,它把所有接受到的消息广播到所有它所知道的队列中去,不论消息的关键字是什么,消息都会被路由到和该交换器绑定的队列中去。
它的工作方式如下图所示:

在程序中申明一个广播式交换器的代码如下:
channel.exchange_declare(exchange='fanout',type='fanout')
直接式交换器类型(direct)
该类交换器需要精确匹配Routing Key与BindingKey,如消息的Routing Key = Cloud,那么该条消息只能被转发至Binding Key = Cloud的消息队列中去。直接式交换器的转发效率较高,安全性较好,但是缺乏灵活性,系统配置量较大。
相对广播交换器来说,直接交换器可以给我们带来更多的灵活性。直接交换器的路由算法很简单——一个消息的routing_key完全匹配一个队列的 binding_key,就将这个消息路由到该队列。绑定的关键字将队列和交换器绑定到一起。当消息的routing_key和多个绑定关键字匹配时消息 可能会被发送到多个队列中。
我们通过下图来说明直接交换器的工作方式:

主题式交换器(Topic Exchange)
该类交换器通过消息的Routing Key与Binding Key的模式匹配,将消息转发至所有符合绑定规则的队列中。Binding Key支持通配符,其中“*”匹配一个词组,“#”匹配多个词组(包括零个)。例如,Binding Key=“*.Cloud.#”可转发Routing Key=“OpenStack.Cloud.GD.GZ”、“OpenStack.Cloud.Beijing”以及“OpenStack.Cloud”的消息,但是对于Routing Key=“Cloud.GZ”的消息是无法匹配的。
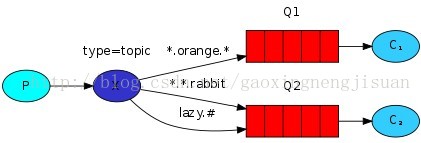
这里的routing_key可以使用一种类似正则表达式的形式,但是特殊字符只能是“*”和“#”,“*”代表一个单词,“#”代表0个或是多个单词。这样发送过来的消息如果符合某个queue的routing_key定义的规则,那么就会转发给这个queue。
在Nova中主要实现Direct和Topic两种交换器的应用,在系统初始化的过程中,各个模块基于Direct交换器针对每一条系统消息自动生成多个队列注入RabbitMQ服务器中,依据Direct交换器的特性要求,Binding Key=“MSG-ID”的消息队列只会存储与转发Routing Key=“MSG-ID”的消息。同时,各个模块作为消息消费者基于Topic交换器自动生成两个队列注入RabbitMQ服务器中。
Nova各个模块之间基于AMQP消息实现通信,但是真正实现消息调用的应用流程主要是RPC机制。Nova基于RabbitMQ实现两种RPC调用:RPC.CALL和RPC.CAST,其中RPC.CALL基于请求与响应方式,RPC.CAST只是提供单向请求,两种RPC调用方式在Nova中均有不同的应用场景。
Nova的各个模块在逻辑功能是可以划分为两种:Invoker和Worker,其中Invoker模块主要功能是向消息队列中发送系统请求消息,如Nova-API和Nova-Scheduler;Worker模块则从消息队列中获取Invoker模块发送的系统请求消息以及向Invoker模块回复系统响应消息,如Nova-Compute、Nova-Volume和Nova-Network。Invoker通过RPC.CALL和RPC.CAST两个进程发送系统请求消息;Worker从消息队列中接收消息,并对RPC.CALL做出响应。Invoker、Worker与RabbitMQ中不同类型的交换器和队列之间的通信关系如图所示。

Nova根据Invoker和Worker之间的通信关系可逻辑划分为两个交换域:Topic交换域与Direct交换域,两个交换域之间并不是严格割裂,在信息通信的流程上是深度嵌入的关系。Topic交换域中的Topic消息生产者(Nova-API或者Nova-Scheduler)与Topic交换器生成逻辑连接,通过PRC.CALL或者RPC.CAST进程将系统请求消息发往Topic交换器。Topic交换器根据系统请求消息的Routing Key分别送入不同的消息队列进行转发,如果消息的Routing Key=“NODE-TYPE.NODE-ID”,则将被转发至点对点消息队列;如果消息的Routing Key=“NODE-TYPE”,则将被转发至共享消息队列。Topic消息消费者探测到新消息已进入响应队列,立即从队列中接收消息并调用执行系统消息所请求的应用程序。每一个Worker都具有两个Topic消息消费者程序,对应点对点消息队列和共享消息队列,链接点对点消息队列的Topic消息消费者应用程序接收RPC.CALL的远程调用请求,并在执行相关计算任务之后将结果以系统响应消息的方式通过Direct交换器反馈给Direct消息消费者;同时链接共享消息队列的Topic消息消费者应用程序只是接收RPC.CAST的远程调用请求来执行相关的计算任务,并没有响应消息反馈。因此,Direct交换域并不是独立运作,而是受限于Topic交换域中RPC.CALL的远程调用流程与结果,每一个RPC.CALL激活一次Direct消息交换的运作,针对每一条系统响应消息会生成一组相应的消息队列与交换器组合。因此,对于规模化的OpenStack云平台系统来讲,Direct交换域会因大量的消息处理而形成整个系统的性能瓶颈点。
3.2Nova系统RPC.CALL以及RPC.CAST调用流程
由前文可以看出,RPC.CALL是一种双向通信流程,即Worker程序接收消息生产者生成的系统请求消息,消息消费者经过处理之后将系统相应结果反馈给Invoker程序。
例如,一个用户通过外部系统将“启动虚拟机”的需求发送给NOVA-API,此时NOVA-API作为消息生产者,将该消息包装为AMQP信息以RPC.CALL方式通过Topic交换器转发至点对点消息队列,此时,Nova-Compute作为消息消费者,接收该信息并通过底层虚拟化软件执行相应虚拟机的启动进程;待用户虚拟机成功启动之后,Nova-Compute作为消息生产者通过Direct交换器和响应的消息队列将“虚拟机启动成功”响应消息反馈给Nova-API,此时Nova-API作为消息消费者接收该消息并通知用户虚拟机启动成功,一次完整的虚拟机启动的RPC.CALL调用流程结束。其具体流程如图所示:
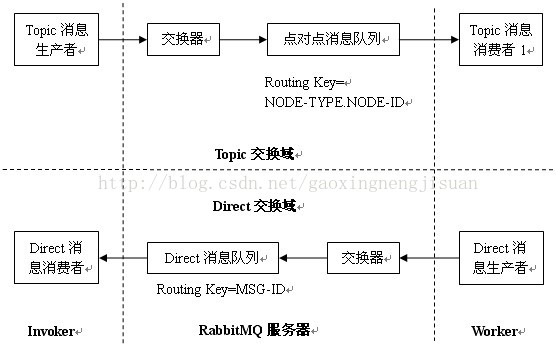
(1)Invoker端生成一个Topic消息生产者和一个Direct消息消费者。其中,Topic消息生产者发送系统请求消息到Topic交换器;Direct消息消费者等待响应消息。
(3)Worker根据请求消息执行完任务之后,分配一个Direct消息生产者,Direct消息生产者将响应消息发送到Direct交换器。
(4)Direct交换器根据响应消息的Routing Key转发至相应的消息队列,Direct消费者接收并把它传递给Invoker。
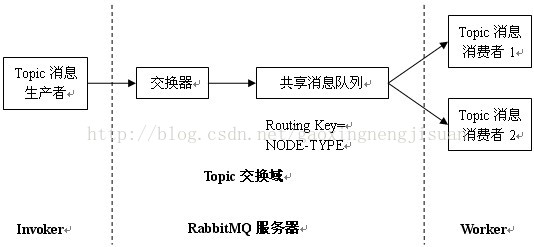
RPC.CAST的远程调用流程与RPC.CALL类似,只是缺少了系统消息响应流程。一个Topic消息生产者发送系统请求消息到Topic交换器,Topic交换器根据消息的Routing Key将消息转发至共享消息队列,与共享消息队列相连的所有Topic消费者接收该系统请求消息,并把它传递给响应的Worker进行处理,其调用流程如图所示:
AMQP协议:

Producer产生消息,将消息赋予路由信息,发送给exchange。
queue存储消息,并将消息发送Consumer
bindings queues与exchange通过路由信息进行绑定。发送过来的消息带有路由信息,exchange提取路由信息和queues与exchange绑定的路由信息匹配,
匹配成功后,将消息发给相应队列。
consumer 从queues中提取信息,并消耗。
exchange 接收消息,并路由到相应队列。
Kombu代码示例:
producer.py
- #!/usr/bin/python
- from kombu.entity import Exchange
- from kombu.messaging import Producer
- from kombu.connection import Connection
- connection = Connection('amqp://guest:[email protected]:5672//')
- channel = connection.channel()
- media_exchange = Exchange('media', 'direct', channel)
- producer = Producer(channel, exchange=media_exchange, routing_key='video')
- producer.publish({'name': '/tmp/lolcat1.avi', 'size': 1301013})
1. 创建连接
2. 获得一个channel
3. 创建一个exchange,名字为‘media’,类型为‘direct’。
4. 创建一个Producer,指定exchange与routing_key,这样,发送信息的时候填充路由信息,发送到指定exchange。也可以在publish的时候指定。
5. 发送消息。
consumer.py
- #!/usr/bin/python
- from kombu.entity import Exchange, Queue
- from kombu.messaging import Consumer
- from kombu.connection import Connection
- def process_media(body, message):
- print body
- message.ack()
- connection = Connection('amqp://guest:[email protected]:5672//')
- channel = connection.channel()
- media_exchange = Exchange('media', 'direct', channel)
- video_queue = Queue('video', exchange=media_exchange, routing_key='video', channel=channel)
- consumer = Consumer(channel, queues=[video_queue], callbacks=[process_media])
- consumer.consume()
- while True:
- connection.drain_events()
- consumer.cancel()
思路很明确:
1. 创建连接
2. 获得channel
3. 创建exchange
4. 创建队列并与exchange绑定
5. 创建Consumer
6. consume() 向server注册,表明现在可以接收信息啦。server可以向该consumer发送消息。
7. drain_events阻塞程序,等待消息到来。当消息到来时,会执行回调函数process_media
8. cancel()通知server不要向该consumer发送任何消息啦。
疑惑:
1. channel是什么
When producers and consumers connects to the broker using a TCP socket after authenticating the connection they establish a channel where AMQP commands are sent. The channel is a virtual path inside a TCP connection between this is very useful because there can be multiple channels inside the TCP connection each channels is identified using an unique ID.
2. process_media的参数message是什么?为什么要调用message.ack()?
打印message,输出kombu.transport.pyamqplib.Message object at 0x28d2b90。于是定位到Message类。
- class Message(base.Message):
- """A message received by the broker.
- .. attribute:: body The message body.
- .. attribute:: channel The channel instance the message was received on.
- """
- def __init__(self, channel, msg, **kwargs):
- props = msg.properties
- super(Message, self).__init__(channel,
- body=msg.body,
- delivery_tag=msg.delivery_tag,
- content_type=props.get("content_type"),
- content_encoding=props.get("content_encoding"),
- delivery_info=msg.delivery_info,
- properties=msg.properties,
- headers=props.get("application_headers"),
- **kwargs)
如果队列要求回复确认信息,那么只有当用户返回一个确认信息,表明该message已经收到,message才会从队列中消失,否则,message一直存放在队列中。
3. drain_events做了些什么?
kombu.transport.pyamqlib.Connection.drain_events
- def drain_events(self, allowed_methods=None, timeout=None):
- """Wait for an event on any channel."""
- return self.wait_multi(self.channels.values(), timeout=timeout)
- def wait_multi(self, channels, allowed_methods=None, timeout=None):
- """Wait for an event on a channel."""
- chanmap = dict((chan.channel_id, chan) for chan in channels)
- chanid, method_sig, args, content = self._wait_multiple(
- chanmap.keys(), allowed_methods, timeout=timeout)
- channel = chanmap[chanid]
- amqp_method = self._method_override.get(method_sig) or \
- channel._METHOD_MAP.get(method_sig, None)
- return amqp_method(channel, args)
ampqlib.client_0_8.channel.py.Channel.
- _METHOD_MAP = {
- (60, 60): _basic_deliver,
- (60, 71): _basic_get_ok,
- }
- def _basic_deliver(self, args, msg):
- consumer_tag = args.read_shortstr()
- func = self.callbacks.get(consumer_tag, None)
- if func is not None:
- func(msg)
Comsumer类的comsume函数:
- def consume(self, no_ack=None):
- self._basic_consume(T, no_ack=no_ack, nowait=False)
- def _basic_consume(self, queue, consumer_tag=None,
- no_ack=no_ack, nowait=True):
- queue.consume(tag, self._receive_callback,
- no_ack=no_ack, nowait=nowait)
- def _receive_callback(self, message):
- self.receive(decoded, message)
- def receive(self, body, message):
- callbacks = self.callbacks
- if not callbacks:
- raise NotImplementedError("Consumer does not have any callback")
- [callback(body, message) for callback in callbacks]
- def consume(self, consumer_tag='', callback=None, no_ack=None,
- nowait=False):
- return self.channel.basic_consume(queue=self.name,
- no_ack=no_ack,
- consumer_tag=consumer_tag or '',
- callback=callback,
- nowait=nowait)
总结一下:drain_events等待队列中的消息,当取得消息后,会调用回调函数进行相应处理。
4. 从connection获得Producer与Consumer
有一个简便方法,可以直接从connection中获得Producer或者Consumer。
- consumer = connection.Consumer(queues=[video_queue], callbacks=[process_media])