版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/gang950502/article/details/73350948
hardoop 入门
标签(空格分隔): hardoop
hadoop 计算框架
- MapReduce
- 离线型计算框架
- 分布式计算框架
- 易编程,高容错,高拓展
- JStorm
- 使用JAVA实现的storm流式计算框架
- Spark
- 内存计算框架,并行计算框架
- 参考资料少,成熟框架但发行晚,因此使用量较少
- 发展趋势(计算速度快,不写入HDFS直接写入内存)
HDFS
优点
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动恢复
- 适合批处理(对各种计算框架兼容性好)
- 移动计算而非数据
- 数据位置暴露给计算框架
- 适合大数据处理
- GB 、TB 、甚至PB 级数据
- 百万规模以上的文件数量
- 10K+ 节点
- 可构建在廉价机器上
- 通过多副本提高可靠性
- 提供了容错和恢复 机制
缺点
- 低延迟数据访问
- 比如毫秒级
- 低延迟与高吞吐率
- 小文件存取
- 占用NameNode 大量内存
- 寻道时间超过读取时间
- 并发写入、文件随机修改(一般不支持修改,修改成本最高)
- 一个文件只能有一个写者
- 仅支持append(一般情况对内也不开放,追加成本高)
框架图

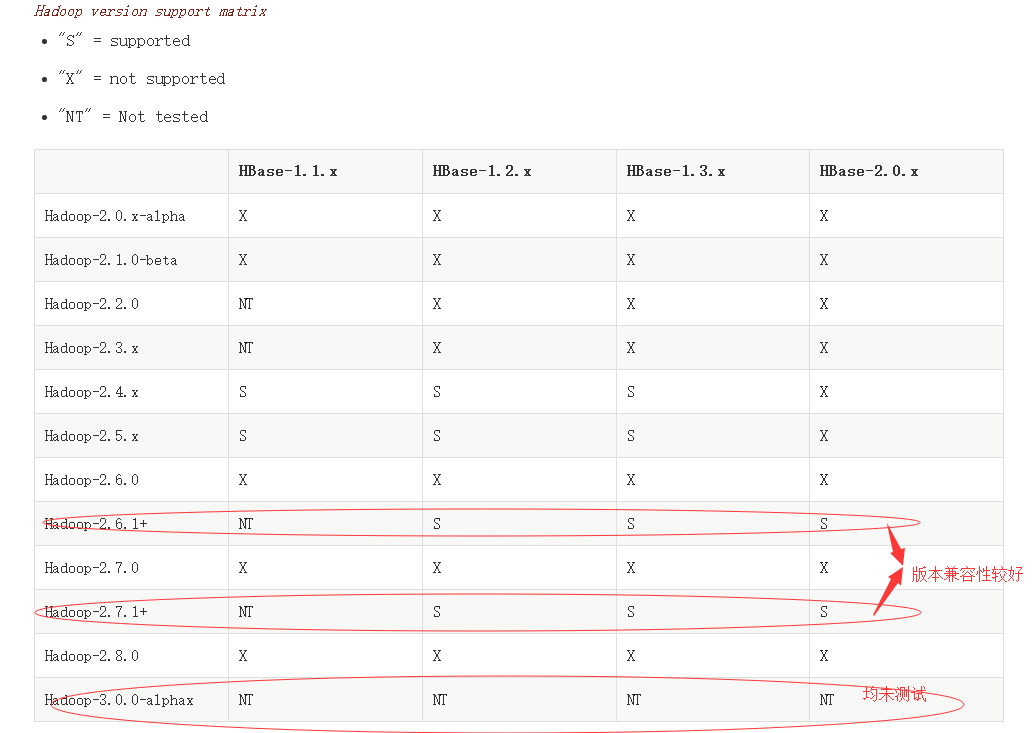
关于hadoop 版本选择
目前一般采用2.X 版本
0.23X 为开发版
3.X目前目前兼容性差
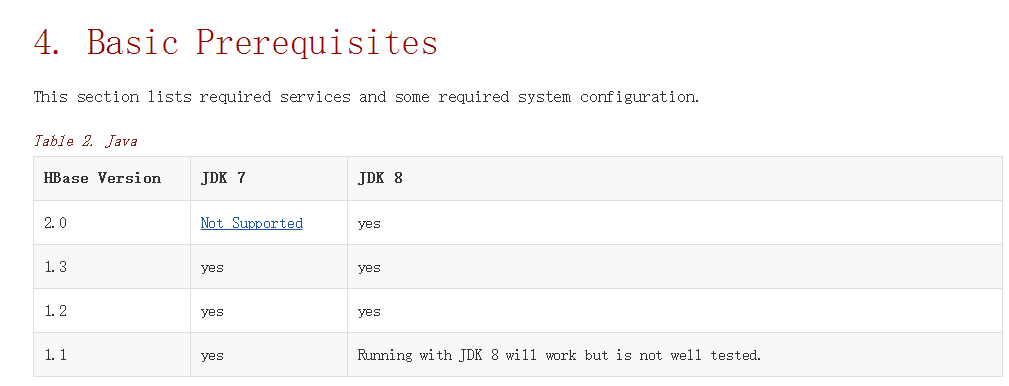
1. 首先要求查看hbase 的版本要求
2. 系统要求
* 各个机器要求时间差小于30S
* 各个机器要求主节点可以远程登录