一、迭代:
1.迭代的概念:
使用for循环便利的过程叫做迭代。比如:使用for循环遍历列表取值的过程
2.可迭代对象:
可使用for循环便利取值的对象叫做可迭代对象。比如:列表、元组、字典、集合、字符串、range
3.判断对象是否为可迭代对象:
使用isinstance(obj, type):内建方法
from collections import Iterable
var = isinstance([1, 5, 6, 7], Iterable) # ==> bool
# 如果obj是type一个实例,返回True;否则,返回False代码:
#!/usr/bin/env python
# coding=utf-8
# 导包
from collections import Iterable # Iterable:可迭代对象
# 判断列表是否为可迭代对象
ret = isinstance([1,2,3,'haha','哈哈'], Iterable)
print("列表是否为可迭代对象:", ret)
# 判断元组是否为可迭代对象
ret = isinstance(("你好", 666, 3.14), Iterable)
print("元组是否为可迭代对象:", ret)
# 判断字典是否为可迭代对象
ret = isinstance({"name":"张三","age":18}, Iterable)
print("字典是否为可迭代对象:", ret)
# 判断集合是否为可迭代对象
ret = isinstance({"你好", 666, 3.14}, Iterable)
print("集合是否为可迭代对象:", ret)
# 判断字符串是否为可迭代对象
ret = isinstance("好好学习,good good study", Iterable)
print("字符串是否为可迭代对象:", ret)
# 判断range是否为可迭代对象
ret = isinstance(range(5), Iterable)
print("range是否为可迭代对象:", ret)4.自定义可迭代对象:
在类里面定义__iter__方法创建的对象就是可迭代对象
代码:
#!/usr/bin/env python
# coding=utf-8
from collections import Iterable
class MyList(object):
def __init__(self):
# 定义列表容器保存用户数据
self.my_list = list()
# 定义添加数据方法
def add_data(self, data):
self.my_list.append(data)
# 在类中提供__iter__方法,保证创建的对象是可迭代对象
def __iter__(self):
pass
if __name__ == '__main__':
# 通过自定义的可迭代类型创建自定义的可迭代对象
my_iterable = MyList()
my_iterable.add_data(1)
my_iterable.add_data(2)
ret = isinstance(my_iterable, Iterable)
print(ret)
for value in my_iterable:
print(value)运行结果:
自定义类是否为可迭代对象: True
Traceback (most recent call last):
File "xxx/xxx/代码/02_自定义可迭代对象.py", line 32, in <module>
for value in my_iterable:
TypeError: iter() returned non-iterator of type 'NoneType'
分析:程序执行到32行,for循环遍历出报错,“类型错误:iter()返回类型为“NoneType”的非迭代器”,原因是因为在__iter__方法中需要返回一个迭代器。可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器,然后通过迭代器获取对象中的数据。
二、迭代器:
1.自定义迭代器对象:
自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
代码:
#!/usr/bin/env python
# coding=utf-8
from collections import Iterable
from collections import Iterator
# 自定义可迭代类型: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
my_iterator = MyIterator(self.my_list)
# 判一下
ret = isinstance(my_iterator, Iterator)
print("my_iterator是迭代器对象:", ret)
return my_iterator
# 自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
class MyIterator(object):
def __init__(self, my_list):
self.my_list = my_list
# 记录当前获取数据的下标
self.current_index = 0
# 判断当前对象是否是迭代器
result = isinstance(self, Iterator)
print("MyIterator创建的对象是否是迭代器:", result)
def __iter__(self):
return self
# 获取迭代器中下一个值
def __next__(self):
if self.current_index < len(self.my_list):
self.current_index += 1
return self.my_list[self.current_index - 1]
else:
# 数据取完了,需要抛出一个停止迭代的异常
raise StopIteration
if __name__ == '__main__':
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
result = isinstance(my_list, Iterable)
print("my_list是可迭代对象:", result)
for value in my_list:
print(value)运行结果:
my_list是可迭代对象: True
MyIterator创建的对象是否是迭代器: True
my_iterator是迭代器对象: True
1
2分析:迭代器和可迭代对象是两个类;
检查是否为迭代器:需要导入迭代器类
from collections import Iterator # 迭代器类可迭代类型(MyList)中的__iter__实例化一个迭代器并返回,这是可迭代类型就具备了 MyIterator类型的迭代器,这时就可以进行遍历操作。迭代器在数据取完的时候需要抛出一个停止迭代异常
raise StopIteration2.iter()函数与next()函数:
iter()函数: 获取可迭代对象的迭代器,会调用可迭代对象的__iter__方法
next()函数:获取迭代器中下一个值,会调用迭代器对象的__next__方法
3. for循环的本质:
<1>当使用for循环遍历的是可迭代对象,那么for循环内部会通过iter函数获取迭代器,然后循环调用next函数获取迭代器中下一个值。
<2>当使用for循环遍历的是迭代器对象,那么直接循环使用next函数获取迭代器中的下一个值。
<3>for循环内部自动捕获停止迭代的异常,而while循环内部没有自己捕获。
<4>最终取值操作都是通过迭代器完成的。
4. 迭代器的应用场景:斐波那契数列--不死神兔:
迭代器完成斐波那契的好处:
1. 节省内存空间,因为每次根据算法只生成一个值
2.生成数列的个数没有上限控制
代码:
#!/usr/bin/env python
# coding=utf-8
class Fibonacci(object):
def __init__(self, num):
# num: 表示根据个数生成fibonacci数列
self.num = num
# 保存fib数列的前两个数
self.first = 0
self.second = 1
# 记录fib数列的下标
self.current_index = 0
def __iter__(self):
return self
def __next__(self):
if self.current_index < self.num:
ret = self.first
self.first, self.second = self.second, self.first + self.second
# 生成数据完成以后下标加1
self.current_index += 1
return ret
else:
# 表示数列生成完成
raise StopIteration
if __name__ == '__main__':
# 创建生成100个fib数列对象(迭代器)
fib = Fibonacci(100)
for _ in range(10):
# 使用for循环,使用next()函数打印前10个
print(next(fib))运行结果:
三、生成器:
1.生成器的概念:
生成器是一类特殊的迭代器,他不需要再向上面的类一样写__iter__()和__next__()方法。使用更加的方便,但是依然可以使用next函数和for循环取值。
2.创建生成器:
方法一:
#!/usr/bin/env python
# coding=utf-8
# 列表推导式
my_list = [i + 2 for i in range(5)]
print("列表推导式:", my_list)
# 创建一个简单的生成器
my_generator = (i + 2 for i in range(5))
print("简单的生成器:")
for _ in range(5):
print(next(my_generator), end=" ")小结:由代码可以看出,简单的生成器的定义方法跟列表推导式类似,是将列表推导式的“[]”换成了“()”,获得的返回值由列表(list)实例对象变成了生成器(generater)对象。
方法二:使用yield关键字
代码:使用yield关键字创建生成器,完成斐波那契数列
#!/usr/bin/env python
# coding=utf-8
# 定义生成器
def fibonacci(num):
# num: 表示生成器根据个数创建指定个数的fib数列
first = 0
second = 1
# 记录生成数列的下标
current_index = 0
# 验证yield执行过程
print("===1===")
# 循环判断条件是否成立
while current_index < num:
ret = first
# 根据公式
first, second = second, first + second
current_index += 1
print("===2===")
yield ret # 在函数里面使用yield表示是一个生成器
print("===3===")
if __name__ == '__main__':
fib = Fibonacci(10)
# 循环遍历
for _ in range(2):
print(next(fib))
print("======华丽的分割线======")
for _ in range(5):
print(next(fib))运行结果:
===1===
===2===
0
===3===
===2===
1
======华丽的分割线======
===3===
===2===
1
===3===
===2===
2
===3===
===2===
3
===3===
===2===
5
===3===
===2===
8小结:当前代码执行到yield关键字的时候代码会暂停,然后把结果返回给外界;
当再次启动生成器的时候会在暂停的位置继续往下执行;
在函数里面使用yield表示是一个生成器
3.生成器使用return关键字:
代码:
#!/usr/bin/env python
# coding=utf-8
# 定义生成器
def fibonacci(num):
# num: 表示生成器根据个数创建指定个数的fib数列
first = 0
second = 1
# 记录生成数列的下标
current_index = 0
# 验证yield执行过程
print("===1===")
# 循环判断条件是否成立
while current_index < num:
ret = first
# 根据公式
first, second = second, first + second
current_index += 1
print("===2===")
yield ret
print("===3===")
# 当再次启动生成器执行return代码的时候,生成器生成数据结束,抛出停止迭代异常
return "ok"
if __name__ == '__main__':
fib = fibonacci(10)
value = next(fib)
print(value)
value = next(fib)
print(value)
运行结果:
===1===
===2===
0
===3===
Traceback (most recent call last):
File "G:/xxx/代码/07_使用return关键字.py", line 31, in <module>
value = next(fib)
StopIteration: ok小结:
生成器里面使用return关键字语法上没有问题,但是代码执行到return语句会停止迭代,会携带信息抛出停止迭代异常。
4.yield和return的对比:
<1>使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
<2>代码执行到yield会暂停,然后把结果返回出去,下次启动
生成器会在暂停的位置继续往下执行
<3>每次启动生成器都会返回一个值,多次启动可以返回多个值,也就是yield可以返回多个值
<4>return只能返回一次值,代码执行到return语句就停止迭代,抛出停止迭代异常
5.使用send方法启动生成器并传参:
代码:
#!/usr/bin/env python
# coding=utf-8
# 定义生成器
def fibonacci(num):
# num: 表示生成器根据个数创建指定个数的fib数列
first = 0
second = 1
# 记录生成数列的下标
current_index = 0
# 验证yield执行过程
print("===1===")
# 循环判断条件是否成立
while current_index < num:
ret = first
# 根据公式
first, second = second, first + second
current_index += 1
print("===2===")
params = yield ret
print(params)
print("===3===")
if __name__ == '__main__':
fib = fibonacci(10)
value = fib.send(None)
print(value)
value = fib.send("哈哈哈")
print(value)
运行结果:
===1===
===2===
0
哈哈哈
===3===
===2===
1小结:
next和send的区别:
next函数启动生成器不能传入参数;
send方法启动生成器可以传入参数,但第一次只能传None。
四、协程-yield
1.协程的概念:
协程,又称微线程,纤程,也称为用户级线程,在不开辟线程的基础上完成多任务,也就是在单线程的情况下完成多任务,多个任务按照一定顺序交替执行。
通俗理解只要在def里面只看到一个yield关键字表示就是协程
2.协程yield的代码实现:
代码:
#!/usr/bin/env python
# coding=utf-8
import time
# 跳舞任务
def dance():
for i in range(3):
print("跳舞中...")
time.sleep(0.2)
yield
# 唱歌任务
def sing():
for i in range(3):
print("唱歌中...")
time.sleep(0.2)
yield
if __name__ == '__main__':
g1 = dance()
g2 = sing()
# yield本质上就是一个生成器
# print(g1, g2)
for i in range(3):
next(g1)
next(g2)运行结果:
跳舞中...
唱歌中...
跳舞中...
唱歌中...
跳舞中...
唱歌中...小结:协程之间执行任务按照一定顺序交替执行
五、协程-greenlet:
1.greentlet的介绍:
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单。
使用如下命令安装greenlet模块:
pip3 install greenletgreenlet的使用:
<1>创建协程:
# 导包
import greenlet
# 创建协程
g1 = greenlet.greenlet(任务名, 参数)<2>切换到指定协程执行对应的任务:
g1.switch()<3>获取当前的协程对象:
ret = greenlet.getcurrent()代码:
#!/usr/bin/env python
# coding=utf-8
import greenlet
import time
def work1():
# 获取当前的协程对象
result = greenlet.getcurrent()
print(result)
for i in range(3):
print("work1工作中...")
time.sleep(0.2)
# 切换到第二个协程执行对应的任务
g2.switch()
def work2():
# 获取当前的协程对象
result = greenlet.getcurrent()
print(result)
for i in range(3):
print("work2工作中...")
time.sleep(0.2)
# 切换到第一个协程执行对应的任务
g1.switch()
if __name__ == '__main__':
# 创建协程1指定完成对应的任务
g1 = greenlet.greenlet(work1)
# 创建协程2指定完成对应的任务
g2 = greenlet.greenlet(work2)
print(g1, g2)
# 切换到指定协程执行对应的任务
g1.switch()
运行结果:
<greenlet.greenlet object at 0x00000200A9B2EA60> <greenlet.greenlet object at 0x00000200A9B2EAF8>
<greenlet.greenlet object at 0x00000200A9B2EA60>
work1工作中...
<greenlet.greenlet object at 0x00000200A9B2EAF8>
work2工作中...
work1工作中...
work2工作中...
work1工作中...
work2工作中...2.使用greenlet的优点:
明确了当前运行的协程。
六、协程-gevent:
1.gevent的介绍:
greenlet已经实现了协程,但是这个还要人工切换,这里介绍一个比greenlet更强大而且能够自动切换任务的第三方库,那就是gevent。
gevent内部封装的greenlet,其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
2.gevent的使用:
下载安装:
pip3 install geventgevent的使用:
<1>创建协程:
# 导包
import gevent
# 创建协程
g1 = gevent.spawn(任务名, 参数1, 参数2, ...)
# spawn(function, *args, **kwargs) -> Greenlet<2>主进程等待协程执行完成:
# 主进程等待协程
g1.join()代码:
#!/usr/bin/env python
# coding=utf-8
import gevent
import time
# 定义跳舞任务
def dance():
# 打印当前协程
print("跳舞:", gevent.getcurrent())
for i in range(3):
print("跳舞中...")
time.sleep(0.2)
# 定义唱歌任务
def sing():
# 打印当前协程
print("唱歌:", gevent.getcurrent())
for i in range(3):
print("唱歌中...")
time.sleep(0.2)
if __name__ == '__main__':
# 创建协程
g1 = gevent.spawn(dance)
g2 = gevent.spawn(sing)
print("main:", g1, g2)
g1.join()
g2.join()运行结果:
main: <Greenlet "Greenlet-0" at 0x29d3d448d48: dance> <Greenlet "Greenlet-1" at 0x29d3d8ab248: sing>
跳舞: <Greenlet "Greenlet-0" at 0x29d3d448d48: dance>
跳舞中...
跳舞中...
跳舞中...
唱歌: <Greenlet "Greenlet-1" at 0x29d3d8ab248: sing>
唱歌中...
唱歌中...
唱歌中...从运行结果中可以看出,程序的运行是按照协程的创建顺序执行的,执行完g1协程之后,再开始执行g2协程,这不是多任务执行的结果,,问题出在哪了呢?注意:默认系统耗时(time.sleep(n))在geven包中不认为是耗时操作,gevent有自带的耗时方法(gevent.sleeo(n))。但是如果一个完成了功能的代码,或者遇到无法使用gevent自带耗时方法表示的系统耗时怎么办呢??
3.给程序打补丁:
3.1 为什么要打补丁?
让gevent框架识别耗时操作,比如:time.sleep,网络请求延时
3.2 monkey.patch_all():猴子补丁
用来在运行时动态修改已有的代码,而不需要修改原始代码
#!/usr/bin/env python
# coding=utf-8
from gevent import monkey
import gevent
import time
# 定义跳舞任务
def dance():
# 打印当前协程
print("跳舞:", gevent.getcurrent())
for i in range(3):
print("跳舞中...")
time.sleep(0.2)
# 定义唱歌任务
def sing():
# 打印当前协程
print("唱歌:", gevent.getcurrent())
for i in range(3):
print("唱歌中...")
time.sleep(0.2)
if __name__ == '__main__':
# 猴子补丁
monkey.patch_all()
# 创建协程
g1 = gevent.spawn(dance)
g2 = gevent.spawn(sing)
print("main:", g1, g2)
# g1.join()
# g2.join()
while True:
# 模拟循环等待接收客户端的连接请求
time.sleep(0.2)运行结果:
main: <Greenlet "Greenlet-0" at 0x1adf918db48: dance> <Greenlet "Greenlet-1" at 0x1adf918dc48: sing>
跳舞: <Greenlet "Greenlet-0" at 0x1adf918db48: dance>
跳舞中...
唱歌: <Greenlet "Greenlet-1" at 0x1adf918dc48: sing>
唱歌中...
跳舞中...
唱歌中...
跳舞中...
唱歌中...分析:分析运行结果,代码不再是执行完g1之后在执行g2了,而是交替执行,如此就完成了多任务。
注意:在代码中将g.join()换成了while True死循环,目的是模拟服务端循环等待客户端的请求。不需要加join操作的前提是:主线程需要一直运行,比如死循环;循环的代码中必须有耗时操作。
七、进程、线程、协程的对比:
1.进程、线程、协程的关系:
一个进程至少有一个线程,一个线程里可以有多个协程。
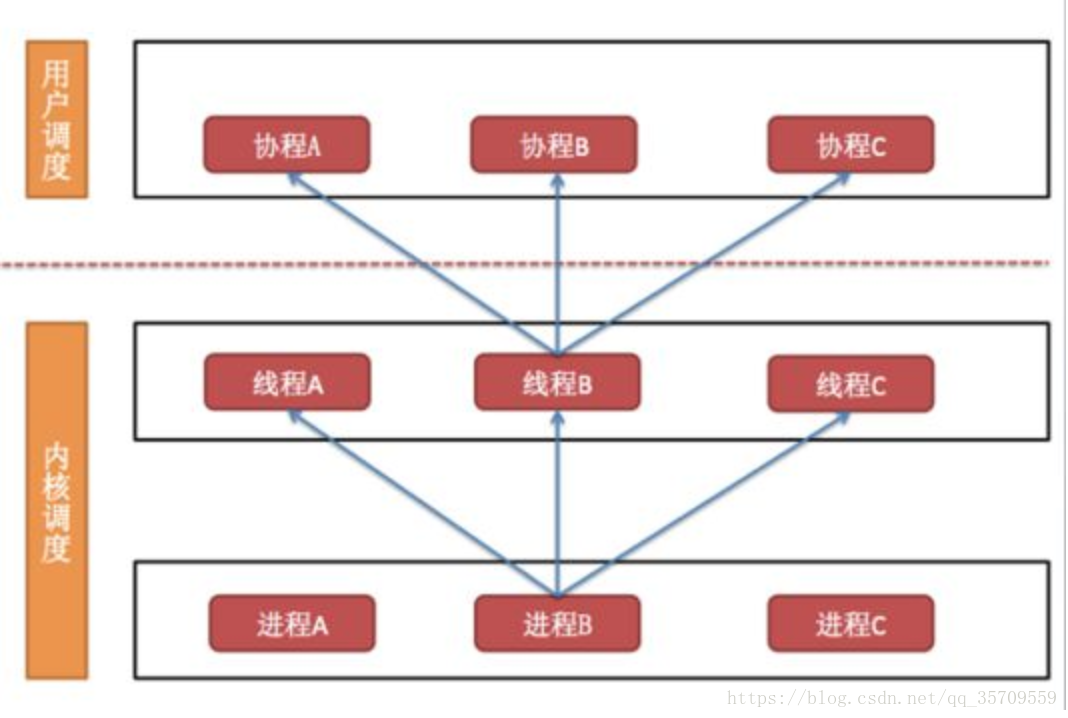
2.进程、线程、协程的关系:
进程是系统分配资源的基本单位;线程是CPU调度的基本单位
先有进程, 进程里面可以有多个线程,线程里面可以有多个协程
进程、线程、协程都是可以完成多任务的,但是进程和线程完成多任务是无序的,协程是按照一定顺序交替执行
从资源开销来说,进程需要的资源最多,线程次之(512k),协程最少(5k)
多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
八、使用gevent完成图片的下载:
代码:
#!/usr/bin/env python
# coding=utf-8
# 导包
import gevent
from gevent import monkey
import urllib.request # 网络请求模块
import time
# 打补丁:让gevent使用网络请求的耗时操作,让协程自动完成下载任务
monkey.patch_all()
# 定义文件下载功能,下载对应的网路文件
def download_file(file_url, file_name):
try:
print(file_url)
# 根据url向网络发起请求
response = urllib.request.urlopen(file_url)
# 把文件写入本地
with open(file_name, 'wb') as file:
while True:
file_data = response.read(1024)
if file_data:
file.write(file_data)
file.flush()
else:
break
except Exception as e:
print("文件下载异常:", e)
else:
print("文件下载完成:",file_name)
if __name__ == '__main__':
# 准备文件的url
file1_url = ""
file2_url = ""
file3_url = ""
# 创建协程并指派任务
g1 = gevent.spawn(download_file, file1_url, "./2b.jpg")
g2 = gevent.spawn(download_file, file2_url, "./hh.jpg")
g3 = gevent.spawn(download_file, file3_url, "./aaa.jpg")
# 主线程等待所有的协程执行完以后再退出
gevent.joinall([g1, g2, g3])