转载自龙果学院的视频http://www.roncoo.com/course/view/1af3e9867cb84263a2a1873880205ae1。
有这样一份log日志记录了某时间戳下某个设备访问网站时产生的上行流量、下行流量。
时间戳/设备号/上行流量/下行流量
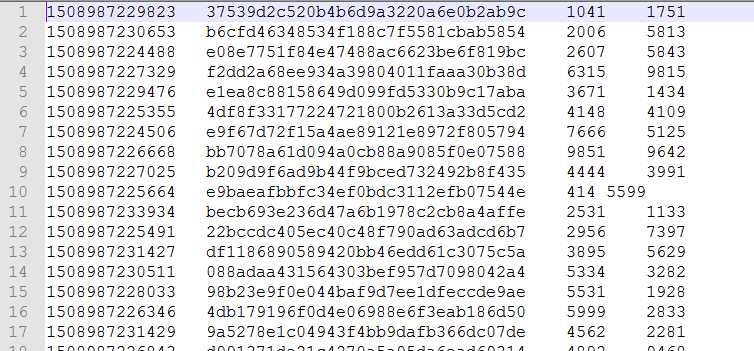
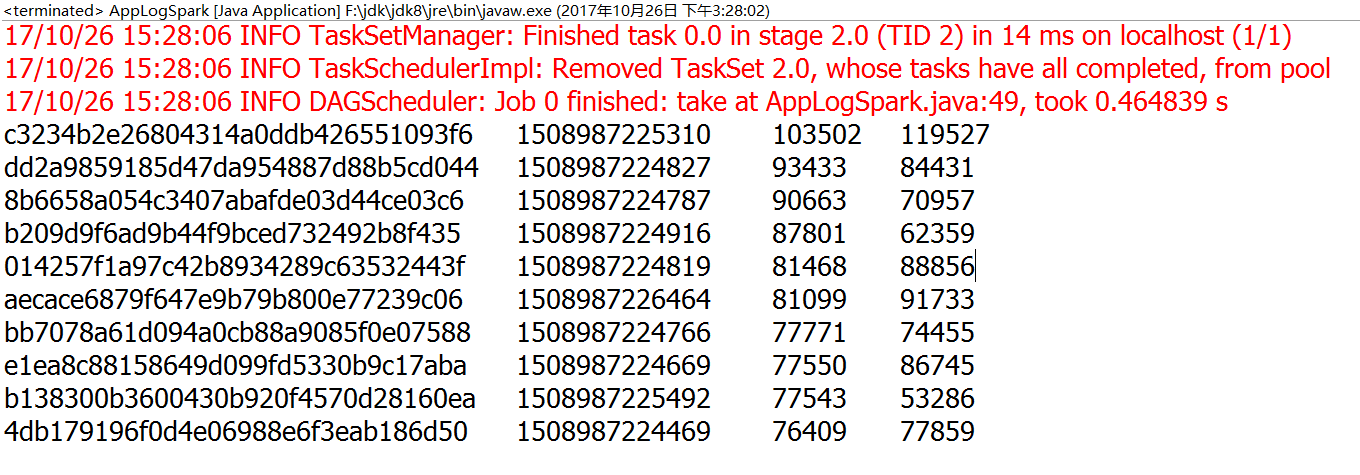
现在想统计出每个设备号的最早访问时间及总的上行流量、下行流量,最后打印出10个按上行流量、下行流量排序的最多的10个记录。
创建个普通的maven项目。
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fei</groupId>
<artifactId>spark-appTrafficCount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.3.0</version>
</dependency>
</dependencies>
</project>
package com.fei;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.UUID;
/**
* 模拟生成数据,并把数据写到文件中
* 文件内容:
* 时间戳 \t设备号\t上行流量\t下行流量
* @author Jfei
*
*/
public class DataFileGenerator {
public static void main(String[] args) {
//1.生成100个设备号
List<String> deviceIds = new ArrayList<String>();
for(int i=0;i<100;i++){
deviceIds.add(getDeviceId());
}
//2.生成1000个时间戳,该时间戳对应的设备号及上行流量、下行流量
Random random = new Random();
StringBuffer sb = new StringBuffer();
for(int i=0;i<1000;i++){
long timestamp = System.currentTimeMillis() - random.nextInt(10000);
//随机获取一个设备号
String deviceId = deviceIds.get(random.nextInt(100));
//上行流量
long upTraffic = random.nextInt(10000);
//下行流量
long downTraffic = random.nextInt(10000);
sb.append(timestamp).append("\t").append(deviceId).append("\t").append(upTraffic)
.append("\t").append(downTraffic).append("\n");
}
//将数据写到文件
PrintWriter pw = null;
try {
pw = new PrintWriter(new OutputStreamWriter(new FileOutputStream("e:\\app-log.txt")));
pw.write(sb.toString());
} catch (Exception e) {
e.printStackTrace();
}finally{
if(pw != null){
pw.close();
}
}
}
private static String getDeviceId(){
return UUID.randomUUID().toString().replace("-", "");
}
}
package com.fei;
import java.io.Serializable;
/**
* 设备(deviceId)访问日志信息对象,对应app-log.txt里面的内容
*
* 因为后面是要将这对象放到spark中处理的,所以必须序列化
* @author Jfei
*
*/
public class AccessLogInfo implements Serializable{
private static final long serialVersionUID = 1L;
//没有设备号,是因为这对象是站在设备角度看的,k-v形式<设备号,AccessLogInfo>
private long timestamp;//时间戳
private long upTraffic;//上行流量
private long downTraffic;//下行流量
public AccessLogInfo(){
}
public AccessLogInfo(long timestamp, long upTraffic, long downTraffic) {
this.timestamp = timestamp;
this.upTraffic = upTraffic;
this.downTraffic = downTraffic;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
public long getUpTraffic() {
return upTraffic;
}
public void setUpTraffic(long upTraffic) {
this.upTraffic = upTraffic;
}
public long getDownTraffic() {
return downTraffic;
}
public void setDownTraffic(long downTraffic) {
this.downTraffic = downTraffic;
}
public static long getSerialversionuid() {
return serialVersionUID;
}
}
因为有排序要求,而上面的AccessLogInfo.java是没有定义排序比较的,所以定义个AccessLogSortKey.java
package com.fei;
import java.io.Serializable;
import scala.math.Ordered;
/**
* 可排序的对象,上行流量、下行流量、时间戳来排序,降序
* @author Jfei
*
*/
public class AccessLogSortKey implements Ordered<AccessLogSortKey>,Serializable{
private static final long serialVersionUID = 1L;
private long timestamp;//时间戳
private long upTraffic;//上行流量
private long downTraffic;//下行流量
public AccessLogSortKey(){
}
public AccessLogSortKey(long timestamp, long upTraffic, long downTraffic) {
this.timestamp = timestamp;
this.upTraffic = upTraffic;
this.downTraffic = downTraffic;
}
public boolean $greater(AccessLogSortKey other) {
if(upTraffic > other.upTraffic){
return true;
}else if(upTraffic == other.upTraffic && downTraffic > other.downTraffic ){
return true;
}else if(upTraffic == other.upTraffic && downTraffic == other.downTraffic && timestamp > other.timestamp ){
return true;
}
return false;
}
public boolean $greater$eq(AccessLogSortKey other) {
if($greater(other)){
return true;
}else if(upTraffic == other.upTraffic && downTraffic == other.downTraffic && timestamp == other.timestamp){
return true;
}
return false;
}
public boolean $less(AccessLogSortKey other) {
if(upTraffic < other.upTraffic){
return true;
}else if(upTraffic == other.upTraffic && downTraffic < other.downTraffic ){
return true;
}else if(upTraffic == other.upTraffic && downTraffic == other.downTraffic && timestamp < other.timestamp ){
return true;
}
return false;
}
public boolean $less$eq(AccessLogSortKey other) {
if($less(other)){
return true;
}else if(upTraffic == other.upTraffic && downTraffic == other.downTraffic && timestamp == other.timestamp){
return true;
}
return false;
}
public int compare(AccessLogSortKey other) {
if(upTraffic - other.upTraffic != 0){
return (int)(upTraffic - other.upTraffic);
}
if(downTraffic - other.downTraffic != 0){
return (int)(downTraffic - other.downTraffic);
}
if(timestamp - other.timestamp != 0){
return (int)(timestamp - other.timestamp);
}
return 0;
}
public int compareTo(AccessLogSortKey other) {
if(upTraffic - other.upTraffic != 0){
return (int)(upTraffic - other.upTraffic);
}
if(downTraffic - other.downTraffic != 0){
return (int)(downTraffic - other.downTraffic);
}
if(timestamp - other.timestamp != 0){
return (int)(timestamp - other.timestamp);
}
return 0;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + (int) (downTraffic ^ (downTraffic >>> 32));
result = prime * result + (int) (timestamp ^ (timestamp >>> 32));
result = prime * result + (int) (upTraffic ^ (upTraffic >>> 32));
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
AccessLogSortKey other = (AccessLogSortKey) obj;
if (downTraffic != other.downTraffic)
return false;
if (timestamp != other.timestamp)
return false;
if (upTraffic != other.upTraffic)
return false;
return true;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
public long getUpTraffic() {
return upTraffic;
}
public void setUpTraffic(long upTraffic) {
this.upTraffic = upTraffic;
}
public long getDownTraffic() {
return downTraffic;
}
public void setDownTraffic(long downTraffic) {
this.downTraffic = downTraffic;
}
public static long getSerialversionuid() {
return serialVersionUID;
}
}
好了,可以使用spark了
AppLogSpark.java
package com.fei;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/**
* 读取app-log.txt中的内容,然后按设备号统计出每个设备号总的上行流量/总的下行流量,
* 然后挑出前10个上行流量最大的设备号,打印出来
* @author Jfei
*
*/
public class AppLogSpark {
public static void main(String[] args) {
//1.创建spark配置文件及上下文对象
SparkConf conf = new SparkConf().setAppName("appLogSpark").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//2.读取日志文件,并创建一个RDD,使用sparkContext方法textFile()可以读取本地文件或
//HDFS文件,创建的RDD会包含文件中的所有内容数据
JavaRDD<String> appLogRDD = sc.textFile("e:\\app-log.txt");
//3.将appLogRDD映射成k-v形式<设备号,AccessLogInfo>的RDD
//可以这样理解为List<deviceId,AccessLogInfo>,deviceId是可以对应多个AcessLogInfo的
JavaPairRDD<String, AccessLogInfo> appLogPairRDD = mapAppLogRDD2Pair(appLogRDD);
//4.将appLogPairRDD根据key进行聚合,并统计
//可以这样理解List<deviceId,AccessLogInfo>聚合后,deviceId只有对应一个AccessLogInfo了,
//AccessLogInfo里面的数据就是某个deviceId的总上行流量/总下行流量了
JavaPairRDD<String, AccessLogInfo> aggregateLogPairRDD = aggregateByDevice(appLogPairRDD);
//5.排序,按上行流量、上行流量、时间戳排序
//因为JavaPairRDD中排序只有sortByKey(XX),而我们这是根据value排序的,所以需要
//将JavaPairRDD<String, AccessLogInfo>转为JavaPairRDD<AccessLogInfo, String>的RDD,
//而AccessLogInfo只是个普通的POJO,为了便于比较排序,定义个AccessLogSortKey对象
JavaPairRDD<AccessLogSortKey, String > logSortRDD = mapRDDKey2SortKey(aggregateLogPairRDD);
//6.实现排序
JavaPairRDD<AccessLogSortKey, String > sortRDD = logSortRDD.sortByKey(false);//降序
//7.取前10个
List<Tuple2<AccessLogSortKey, String>> list = sortRDD.take(10);
//打印
for(Tuple2<AccessLogSortKey, String> t : list){
System.out.println(t._2 + "\t" + t._1.getTimestamp() + "\t" + t._1.getUpTraffic()+ "\t" + t._1.getDownTraffic());
}
//关闭
sc.close();
}
/**
* 将appLogRDD映射成key-value形式的JavaPairRDD<String, AccessLogInfo>的RDD
* @param appLogRDD
* @return
*/
private static JavaPairRDD<String, AccessLogInfo> mapAppLogRDD2Pair(JavaRDD<String> appLogRDD){
return appLogRDD.mapToPair(new PairFunction<String, String, AccessLogInfo>() {
private static final long serialVersionUID = 1L;
//accessLog是对应文件中的一行数据
public Tuple2<String, AccessLogInfo> call(String accessLog) throws Exception {
//根据\t对一行的数据进行分割
String[] data = accessLog.split("\t");
long timestamp = Long.parseLong(data[0]);
String deviceId = data[1];
long upTraffic = Long.parseLong(data[2]);
long downTraffic = Long.parseLong(data[3]);
AccessLogInfo info = new AccessLogInfo(timestamp,upTraffic,downTraffic);
return new Tuple2<String, AccessLogInfo>(deviceId,info);
}
});
}
/**
* 将JavaPairRDD<String, AccessLogInfo>进行聚合
* @param appLogPairRDD
* @return
*/
private static JavaPairRDD<String, AccessLogInfo> aggregateByDevice(JavaPairRDD<String, AccessLogInfo> appLogPairRDD){
return appLogPairRDD.reduceByKey(new Function2<AccessLogInfo, AccessLogInfo, AccessLogInfo>() {
private static final long serialVersionUID = 1L;
public AccessLogInfo call(AccessLogInfo v1, AccessLogInfo v2) throws Exception {
//最早的访问时间
long timestamp = v1.getTimestamp() < v2.getTimestamp() ? v1.getTimestamp() : v2.getTimestamp();
long upTraffic = v1.getUpTraffic() + v2.getUpTraffic();//总上行流量
long downTraffic = v1.getDownTraffic() + v2.getDownTraffic();//总下行流量
return new AccessLogInfo(timestamp,upTraffic,downTraffic);
}
});
}
/**
* 将JavaPairRDD<String, AccessLogInfo>转为JavaPairRDD<AccessLogSortKey, String >便于后面的排序
*/
private static JavaPairRDD<AccessLogSortKey, String > mapRDDKey2SortKey(JavaPairRDD<String, AccessLogInfo> aggregateRDD){
return aggregateRDD.mapToPair(new PairFunction<Tuple2<String,AccessLogInfo>,AccessLogSortKey, String >() {
private static final long serialVersionUID = 1L;
public Tuple2<AccessLogSortKey, String> call(Tuple2<String, AccessLogInfo> t) throws Exception {
String deviceId = t._1;
AccessLogInfo info = t._2;
AccessLogSortKey sortKey = new AccessLogSortKey(info.getTimestamp(),info.getUpTraffic(),info.getDownTraffic() );
return new Tuple2<AccessLogSortKey, String>(sortKey,deviceId);
}
});
}
}
执行后,打印出的日志