第九天 - MapReduce计算模型 - 案例
一、概念
- MapReduce是一种编程模型,用于大规模数据集的并行运算。能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果。
- 在函数式语言里,map表示对一个列表中的每个元素做计算,reduce表示对一个列表中的每个元素做迭代计算。
- 在MapReduce里,Map处理的是原始数据,可能是杂乱无章的,Reduce处理的是分组后的数据。
二、流程
- MapReduce结构
- MRAppMaster:负责整个程序的过程调度及状态协调
- MapTask:负责Map阶段的整个数据处理流程
- ReduceTask:负责Reduce阶段的整个数据处理流程
运行流程
- 最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的MapTask实例数量,然后向集群申请机器启动相应数量的MapTask进程
- MapTask进程启动之后,根据给定的数据切片范围进行数据处理
- MRAppMaster监控到所有MapTask进程任务完成之后,会根据客户指定的参数启动相应数量的ReduceTask进程,并告知ReduceTask进程要处理的数据范围(数据分区)
- ReduceTask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台MapTask运行所在机器上获取到若干个MapTask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用用户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用用户指定的outputformat将结果数据输出到外部存储
三、案例一 - WordCount
准备工作
新建java项目,导包
导包是在第七天-编写代码前的准备的基础上再导入以下内容:
$HADOOP_HOME\share\hadoop\mapreduce下非test和非source的jar包
$HADOOP_HOME\share\hadoop\mapreduce\lib下非test和非source的jar包
$HADOOP_HOME\share\hadoop\yarn下非test和非source的jar包
$HADOOP_HOME\share\hadoop\yarn\lib下非test和非source的jar包
导入的包与之前的包会重复,覆盖即可
导包后将lib添加至构建路径。
在src下建包org.apache.hadoop.io.nativeio,下载NativeIO.java将其复制到org.apache.hadoop.io.nativeio
将Hadoop配置文件中的log4j.properties复制到工程src目录下
建立三个包mapper、reducer、master对应放Mapper、Reducer、Master代码程序
最终包结构:
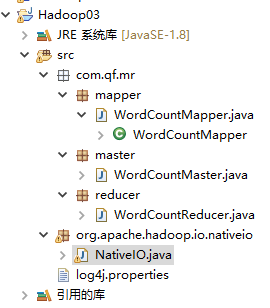
编写代码
WordCountMapper.java:
在mapper包中新建此类,并继承Mapper类
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; //KEYIN -> 代表数据偏移量,传入的是数据类型 //VALUE -> 每一行的数据,Text类型 //KEYOUT -> 每个拆分得到的单词,作为Map阶段输出的key类型 //VALUEOUT -> 单词出现次数:1,作为Map阶段输出的value类型 public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO 自动生成的方法存根 String line = value.toString(); String[] words = line.split(" "); for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } }WordCountReducer.java:
在reducer包中建立此类,并继承Reducer类
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; // 前两个为Reducer阶段输入类型,与Mapper中的输出类型相一致 public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> value, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO 自动生成的方法存根 int count = 0; // 迭代器获取值 for(IntWritable intWritable : value) { count += intWritable.get(); } context.write(new Text(key), new IntWritable(count)); } }WordCountMaster.java:
在master包中建立此类,此类作为程序入口,有main方法
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.qf.mr.mapper.WordCountMapper; import com.qf.mr.reducer.WordCountReducer; public class WordCountMaster { public static void main(String[] args) throws Exception { // 初始化配置 Configuration conf = new Configuration(); // 初始化job参数,指定job名称 Job job = Job.getInstance(conf, "wordCount"); // 设置运行job的类 job.setJarByClass(WordCountMaster.class); // 设置Mapper类 job.setMapperClass(WordCountMapper.class); // 设置Reducer类 job.setReducerClass(WordCountReducer.class); // 设置Map的输出数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置Reducer的输出数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入的路径,此路径必须存在,否则报错,此路径中存放数据文件,无论多少个文件,都会进行 // 数据计算 FileInputFormat.setInputPaths(job, new Path("hdfs://SZ01:8020/input/user1")); // 设置输出的路径,程序运行后会自动创建 FileOutputFormat.setOutputPath(job, new Path("hdfs://SZ01:8020/output/wordCount")); // 提交job boolean result = job.waitForCompletion(true); // 执行成功后进行后续操作 if (result) { System.out.println("Congratulations!"); } } }
运行程序
两种运行方式:
直接在eclipse中运行WordCountMaster.java
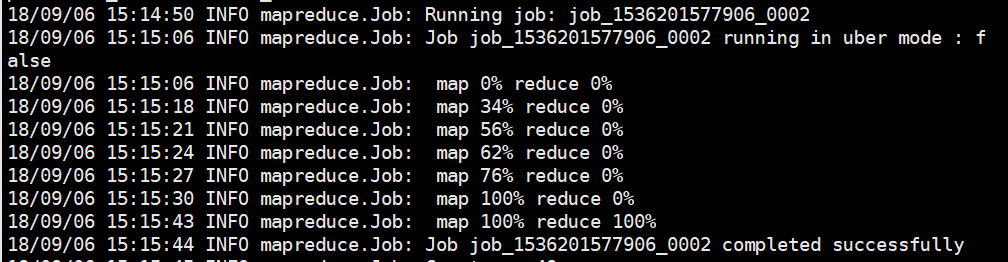
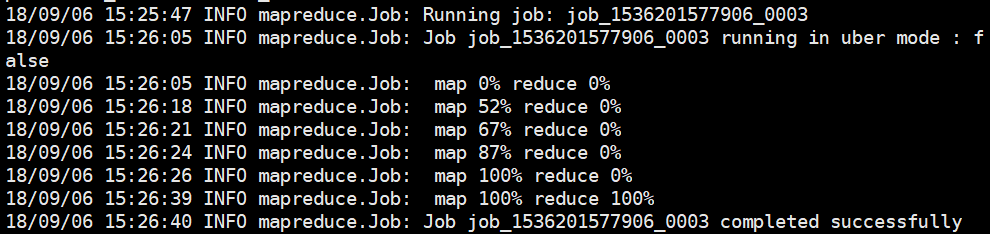
通过查看运行日志,可以得出,每运行一个job都会分配一个唯一的job_id,在运行过程控制台会显示运行过程:map xx% reduce xx% 显示程序运行的完成度。

程序运行结束后,控制台输出如下信息:
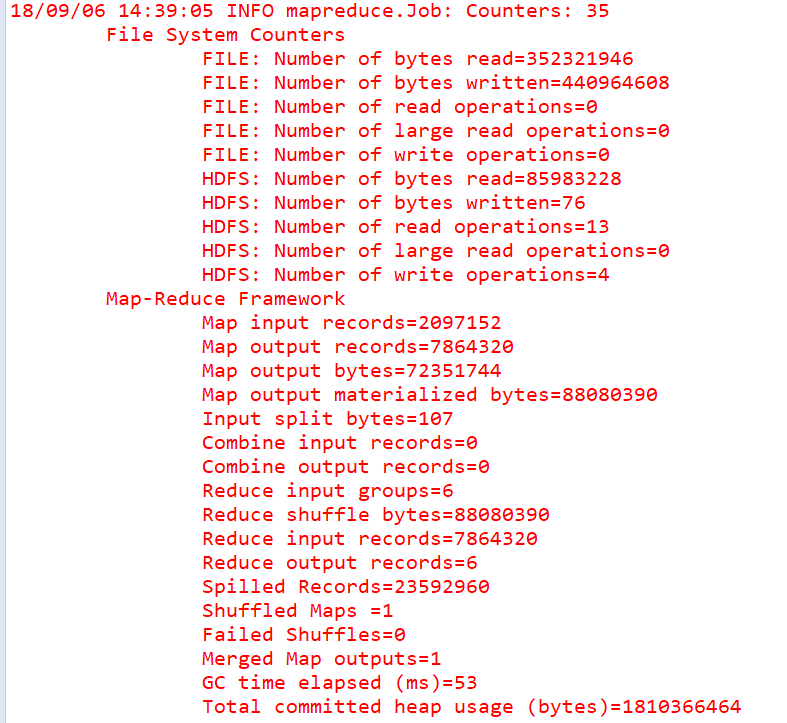
运行成功后,可在hdfs的/output/wordCount中查看到结果
hdfs dfs -ls /output/wordCount

_SUCCESS代表成功,输出结果在part-r-00000中
hdfs dfs -cat /output/wordCount/part-r-00000
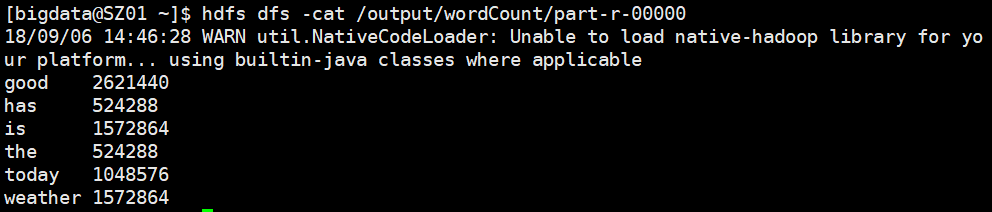
在CentOS中运行
由于输出结果的目录不能重复,所以改动Master中的输出结果目录

将项目打包成jar:
右键项目 -> export -> JAR file -> 选中src下的全部内容,去掉lib文件夹 -> 选择导出目录
使用Xftp将jar文件上传至CentOS中
输入命令运行
hadoop jar test.jar com.qf.mr.master.WordCountMaster
hadoop jar {jar包所在位置} {运行主类的全路径}
运行状态
可以通过yarn的http端口进行查看任务状态
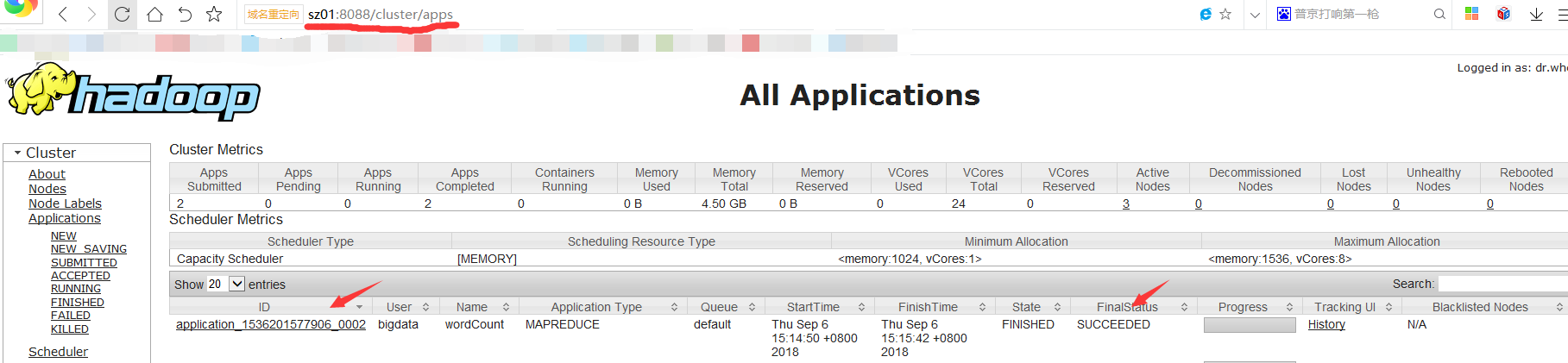
在此页面,可以点击ID,在新页面中点击logs可以查看运行日志

可以在hdfs中查看结果文件
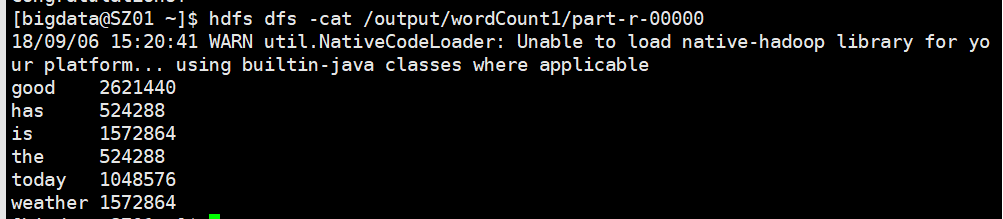
四、WordCount优化
第三中的WordCount中输入输出路径固定了,可以将其作为可变参数,在运行时进行传参
修改WordCountMaster代码
// 设置输入的路径 FileInputFormat.setInputPaths(job, new Path(args[0])); // 设置输出的路径 FileOutputFormat.setOutputPath(job, new Path(args[1]));
打包后通过Xftp传入到CentOS中
执行运行命令时加上输入、输出路径参数
hadoop jar test.jar com.qf.mr.master.WordCountMaster /input/user1 /output/wordCount2

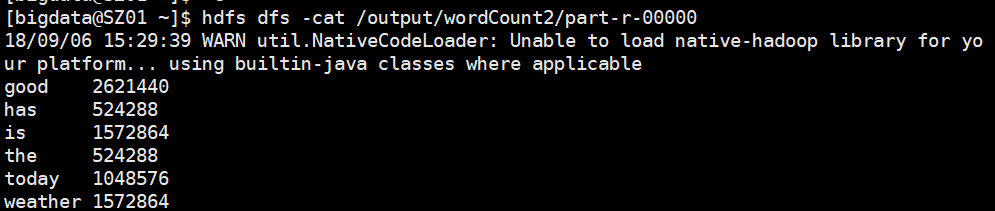
运行成功,查看结果
五、案例二 - 计算每一行中多个数值的平均值
数据文件
Line1 8 5 8
Line2 10 66 32 54
Line3 25 30 35 40 45AvgMaster.java
import java.io.IOException;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 输入数据如下:
// 8 5 8
// 10 66 32 54
// 25 30 35 40 45
public class AvgMapper extends Mapper<LongWritable, Text, Text, FloatWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FloatWritable>.Context context)
throws IOException, InterruptedException {
// 获得每一行的值
String line = value.toString();
// 分割数据,获得每一个数字的值
String[] words = line.split(" ");
String lineName = words[0];
float sum = 0;
float avg = 0;
for(int i = 1; i < words.length; i++) {
sum += Integer.parseInt(words[i]);
}
avg = sum / (words.length - 1);
context.write(new Text(lineName), new FloatWritable(avg));
}
}AvgReducer.java
import java.io.IOException;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class AvgReducer extends Reducer<Text, FloatWritable, Text, FloatWritable> {
@Override
protected void reduce(Text key, Iterable<FloatWritable> values,
Reducer<Text, FloatWritable, Text, FloatWritable>.Context context) throws IOException, InterruptedException {
// 迭代器获取值
context.write(key, new FloatWritable(values.iterator().next().get()));
}
}AvgMaster.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.qf.mr.mapper.AvgMapper;
import com.qf.mr.reducer.AvgReducer;
public class AvgMaster {
public static void main(String[] args) throws Exception{
// 初始化配置
Configuration conf = new Configuration();
// 初始化job参数,指定job名称
Job job = Job.getInstance(conf, "avg");
// Job job = Job.getInstance(conf, "wordCount");
// 设置运行job的类
job.setJarByClass(AvgMaster.class);
// 设置Mapper类
job.setMapperClass(AvgMapper.class);
// 设置Reducer类
job.setReducerClass(AvgReducer.class);
// 设置Map的输出数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FloatWritable.class);
// 设置Reducer的输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
// 设置输入的路径
FileInputFormat.setInputPaths(job, new Path("hdfs://SZ01:8020/input/avgData"));
// 设置输出的路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://SZ01:8020/output/avgOut"));
// 提交job
boolean result = job.waitForCompletion(true);
// 执行成功后进行后续操作
if (result) {
System.out.println("Congratulations!");
}
}
}执行成功,结果如下:
