典型的数据分析系统,要分析的数据种类其实是比较丰富的。依据来源可大体分为以下几个部分:
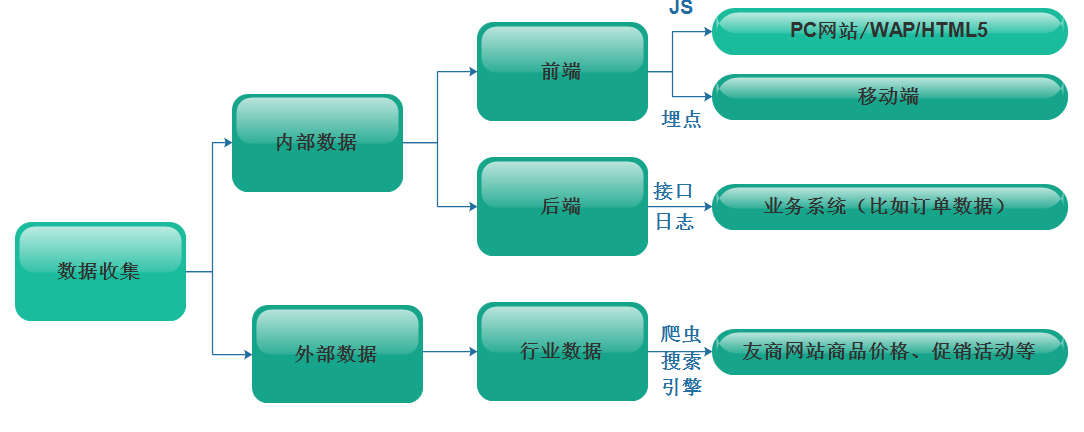
图:数据分析系统数据来源
1. 业务系统数据
业务系统产生的数据是不可忽视的,比如电商网站,大量的订单数据看似杂乱无章,实则蕴含潜在的商业价值,可以从中分析进而进行商业推广,产品推荐等。
另一角度来看,业务系统数据获取成本低、方式容易,属于公司内部范畴。业务系统的数据一般保存在关系型数据库当中。获取形式有:
接口调用:直接获取业务系统数据库的数据,但是要注意不能影响业务系统数据库的性能,比如大量获取数据增大数据库读数据压力。
数据库dump:非高峰时段,或者在数据库从库上dump出全部数据。一般企业中会定时进行数据库的备份、导出工作,那么就可以共享使用这些数据。
比如MySQL数据库,使用mysqldump工具就可以进行数据库的导出。
mysqldump -uroot -pPassword [database name] [dump file]
mysqldump命令将数据库中的数据备份成一个文本文件。表的结构和表中的数据将存储在生成的文本文件中。
2. 爬虫数据

在进行网站数据分析的时候,除了内部数据之外,还有一部分数据是我们不能够忽视的。那就是所谓的外部数据。当然这是相对公司网站来说的。拥有了外部数据可以更好的帮助我们进行数据分析。
爬虫(Web crawler),是指一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
电子商务行业最初的爬虫需求来源于比价。这是某些电商网站的核心业务。大家如果买商品的时候,是一个价格敏感型用户的话,很可能会使用比价功能。毫无悬念,会使用爬虫技术来爬取所有相关电商的价格。
当然,这并不意味着大家喜欢被爬取。于是需要通过技术手段来做反爬虫。