场景:当我们以未登录身份使用浏览器访问一个看书的相关网址时,只显示了亚马逊的购买链接。隐藏了书籍的下载链接。
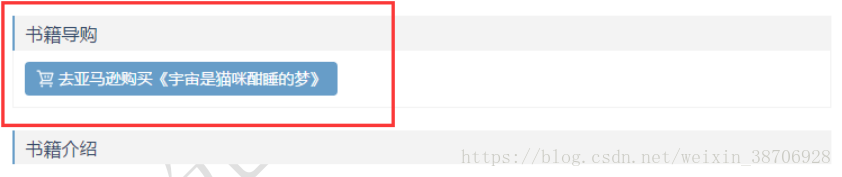
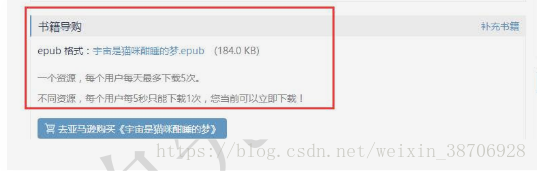
但是当我们登录以后,下载链接会显示出来,这样在爬虫的时候,可以把下载链接解析出来使用。
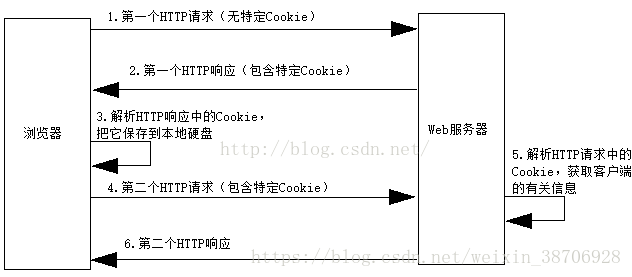
登录前后网页Headers-Request Headers显示的Cookie不同。下图为浏览器和Web服务器之间的交互,也显示了Cookie的信息。
Cookie的引文原意是“点心”,它是在客户端访问Web服务器时,服务器在客户端硬盘上存放的信息,好像是服务器发送给客户的“点心”。服务器可以根据Cookie来跟踪客户状态,这对于需要区别客户的场合(如电子商务)特别有用。
当客户端首次请求访问服务器时,服务器先在客户端存放包含该客户的相关信息的Cookie,以后客户端每次请求访问服务器时,都会在HTTP请求数据中包含Cookie,服务器解析HTTP请求中的Cookie,就能由此获得关于客户的相关信息。
因此我们使用登录以后的Cookie。自己编辑Cookie访问Web服务器。网络爬虫中Cookie的两种使用方式,代码中网页已经不存在,但是可以自己在其他网页中尝试。我们使用的是登录之后的Cookie。
1、直接将Cookie写在header头部
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=181584
6425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a2
37a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=14839
26368'''
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Geck
o) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/view/22353.html'
wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)2、使用requests插入Cookie
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {
"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483
922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"
}
url = 'https://kankandou.com/book/view/22353.html'
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)这样我们就轻松的使用Cookie获取到了需要登录验证后才能浏览的网页和资源了。上面的Cookie是从自己浏览的网页中复制粘贴得到的。
参考自:《python爬虫实战入门教程》