一.Kafka 简介
Kafka是一种分布式的发布(producer)/订阅(consumer)的消息系统,并支持实时和离线的数据处理、可扩展、持久的。Kafka Server 是分布式部署(Broker),Kafka 的消息(Topic)存储在Kafka Server上并以Topic进行分类的,而且可以设置消息(Topic)分区(partition),不会造成消息都存储在同一个磁盘从而导致磁盘空间慢的问题,同个partition里的数据是有顺序的(FIFO先进先出)。
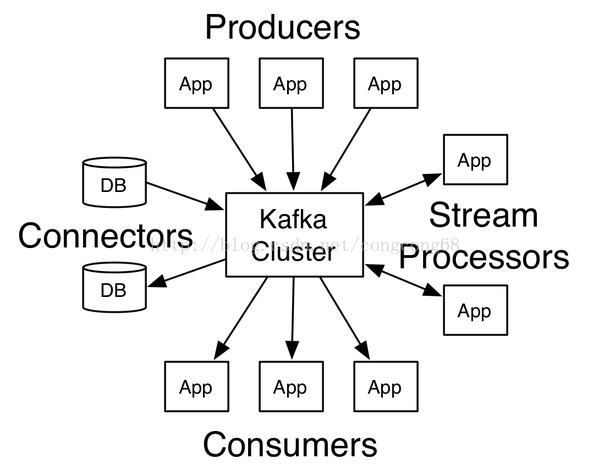
---来自官方
Kafka的producer使用 push模式发布消息到对应Topic,consumer主动pull模式从Broker订阅消息,在这过程中producer 与consumer都需要zookeeper来保证消息的可靠性,zookeeper存储了一下meta信息。
二、Broker
Kafka 集群包含一个或者多个服务器,每个服务器都会标示为Broker。
通过Server.properties中的broker.id 标识的。消息都会存储在这上面的。所以Broker数量(服务器)越多,集群的吞吐率就越高。
二、Topics and Logs
不同的 producer生产的不同类的消费,Kafka通过Topics 区分不同类的消息,不同的Topics 的消息是分开存储的,存储在不同的Broker,每个Topics还可以进行分区存储(partition),分区数量可以一个或者多个组成的,在Server.properties配置log.dirs(kafka持久化数据存储的路径)数据目录下有对应的topic_name-partition_id文件。
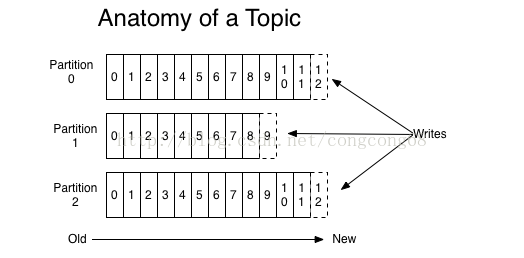
1)消息被append到对应的partition中,每个partition的消息是有顺序的,Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,offset是partition中Message的id,partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件。
2) Kafka中Topics的消息,默认保留2天,两天过后会被删除,可以通过Server.properties配置log.retention.{ms,minutes,hours},也可以配置消息达到多大时被删除(log.retention.check.interval.ms)。默认保留2天,在这2天里,消息有没有被消费者消费,这个消息都存在,即使被消费了,这个消息也还是存在的,可以更改offset,重新消费消息。
3)Kafka中Topic的存储消息,可以是分区的,并分布式的存储在不同的Broker上,Kafka的吞吐率可以水平扩展。
4)Producer 和Consumer分开的处理,解耦
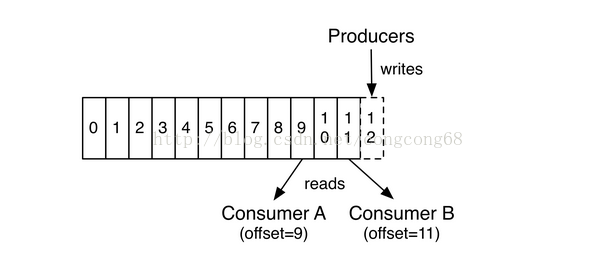
三、Producer 发布
Producer 将消息发布到指定的Topic中。
1)Topic多个分区时,消息根据SimplePartitioner的规则,采用hashcode的做模运算,把消息保存到对应的分区。
2)可以指定相同的key,发送到相同的分区,并保证消息有顺序性。
四、Consumer
消息者,每个consumer属于一个特定的consuer group(消费者组),如果一个消费者不指定group,则默认一个group,同一个topic的一个消息只能被同一个consuer group内的一个consuer 消费,但多个consuer group可同时消息同一个消息。consuer 在消费消息时,保存了offset,会记录在zookeeper上,顺序的读取时offset会增大。
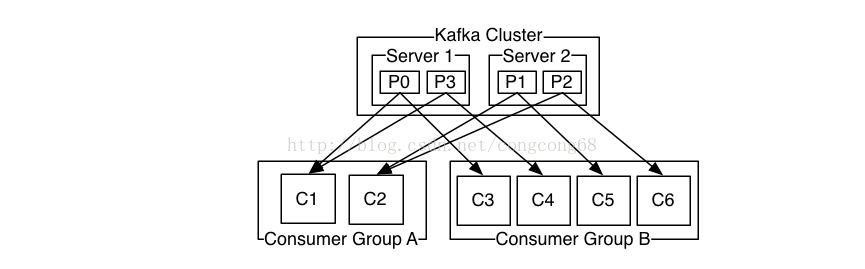
五、Replication
每个partition有对应的leader,leader负责了消息的读写操作,leader分布在broker。
我们在创建Topics时会指定每个partition的副本数(default.replication.factor 配置),一个消息leader 和follower都有保存才算成功,leader如果挂了,Kafka保证读写可靠性,采用了ISR(in-sync replicas),新的Leader从ISR中选举出来,ISR所有副本能够及时的复制Leader日志的节点,follower如果采用同步复制,follower都复制完这条消息才会commit,极大的影响了Kafka的吞吐率,Kafka采用了异步的批量的复制Leader日志,每个partition保Leader计算每个副本和它相对落后的数量和在规定时间内不会向Leader获取消息的会更新ISR并移除这些follower:
1)request.required.acks (0:代表不需要任何确认; 1:代表需要leader replica确认 ;-1:代表需要ISR中所有进行确的。
2)replica.lag.max.messages:数量 只要follower相对Leader落后的数量,就会从ISR移除。
3)replica.lag.time.max.ms:时间 规定时间内不会向Leader获取消息就会从ISR移除。