1.准备工作
1.1 jdk下载安装
1.2 官网下载:
scala-2.10.4.tgz(支持spark)
hadoop-2.6.0.tar.gz
spark-1.6.0-bin-hadoop2.6.tgz
1.3 准备三台虚拟机
centos6.3
地址:172.16.100.01,172.16.100.02,172.16.100.03,新建用户:
useradd cluster
passwd cluster
修改三台机器的hosts,添加内容:
[root@master home]# vim /etc/hosts172.16.100.01 master
172.16.100.02 slave1
172.16.100.03 slave22.实现ssh无密登录
ssh-keygen -t rsa(一路回车,图形输出表示成功)
cd /home/cluster/.ssh下面多出两个文件:
私钥文件:id_raa
公钥文件:id_rsa.pub
将三台虚拟机的公钥id_rsa_pub的内容放到authorized_key中:
在/home/cluster/.shh目录下执行:
cat id_rsa.put >> authorized_keys
将authorized_keys放到另外两台虚拟机下执行相同命令,最后将存入了三台虚拟机公钥的authorized_keys文件存入到三台虚拟机中。
修改三台虚拟机的authorized_keys文件权限,chmod 644 authorized_keys
测试ssh之间是否互通,(相互测试是否通的,很重要)
# ssh 172.16.100.02
3.hadoop集群搭建
先在master主机上配置
1)把下载的hadoop-2.6.0.tar.gz解压到hadoop目录下
2)建立目录:
mkdir -p /home/cluster/hadoop/{pids,storage}
mkdir -p /home/cluster/hadoop/storage/{hdfs,tmp}
mkdir -p /home/cluster/hadoop/storage/hdfs/{name,data}3)配置环境变量:vim /etc/profile (也可以修改当前用户的环境变量/home/cluster/.bashrc)
export HADOOP_HOME=/home/cluster/hadoop/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH source /etc/profile4)修改配置文件core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/cluster/hadoop/storage/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
</property>
<configuration> <configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/cluster/hadoop/storage/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/cluster/hadoop/storage/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration> <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration> <configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value> master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value> master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value> master:8088</value>
</property>
</configuration> export JAVA_HOME=jdk路径
9)配置slave
master
slave1
slave2scp -r hadoop 127.16.100.02:/home/cluster
scp -r hadoop 127.16.100.03:/home/cluster11)验证
在hadoop目录下执行
bin/hdfs namenode –format (只执行一次)
sbin/start-dfs.sh #启动HDFS
sbin/stop-dfs.sh #停止HDFS
sbin/start-all.sh或者stop-all.sh
jps命令验证
HDFS管理页面http://10.10.4.124:500704.scala安装
3)验证,直接输入scala

5.spark安装
1)解压将解压的spark-1.6.0-bin-hadoop2.6.tgz解压在/home/cluster/spark中(tar命令)
修改名字:mv spark-1.6.0-bin-hadoop2.6 spark
2)添加环境变量export SPARK_HOME=/home/cluster/spark/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin3)修改/home/cluster/spark/spark/conf目录下:spark-env.sh
mv spark-env.sh.template spark-env.sh
添加环境变量:
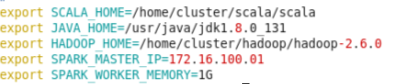
4) mv log4j.properties.template log4j.properties
5)mv slaves.template slaves编辑内容:
master
slave01
slave026)修改相关目录权限,否则无法启动
chmod -R 777 spark
7)其他两台虚拟机重复操作
8)启动spark和关闭集群
/home/cluster/spark/spark/sbin/start-all.sh
/home/cluster/spark/spark/sbin/stop-all.sh
jps命令查看启动进程情况
监控页面:主机ip:8080
