版权声明:未经本人允许请勿转载 https://blog.csdn.net/m0_37606346/article/details/82799994
文章目录
对数据库/表的操作
- 创建数据库
create database dbname
- 创建数据表
create table tb_name();
- 显示数据库/数据表
show databases;
show tables;
- 查看表结构
desc tb_name;
- 切换到指定数据库
use dbname;
- 删除数据库
drop database dbname;
插入数据
下例插入多行数据:
insert into tb_tiger(ID,Name,Kind,Number,Address) VALUES(1808,'华南虎','猫科',0,'中国'),(1809,'熊猫','熊科',1668,'中国'),(1810,'孟加拉虎','猫科',5102,'孟加拉'),(1811,'东北虎','猫科',21,'中国');
insert into tb_tiger VALUES(1808,'华南虎','猫科',0,'中国'),(1809,'熊猫','熊科',1668,'中国'),(1810,'孟加拉虎','猫科',5102,'孟加拉'),(1811,'东北虎','猫科',21,'中国');
修改数据
- 下例修改ID=1806这行多个属性的数据
update tb_tiger set Address='美国',Name='美洲狮01' where ID=1806;
删除数据
- 下例删除Number>10000的所有行
delete from tb_tiger where Number>10000;
查询
条件查询
- 查询所有猫科动物的信息
select * from tb_tiger where Kind='猫科';
- 查询现存数量少于5000的动物信息
select * from tb_tiger where Number<5000;
- 带between and的范围查询
select * from tb_tiger where Number between 1000 and 10000;
select * from tb_tiger where Number>=1000 and Number<=10000;
- 查询产地在中国、孟加拉和阿富汗的动物信息
select * from tb_tiger where Address='中国' or Address='阿富汗' or Address='孟加拉';
模糊查询 like
- 模糊查询(‘%’代表任意个任意字符; ‘_’代表一个任意字符):(查询名称中包含‘熊’的动物信息)
select * from tb_tiger where Name like '%熊%';
select * from tb_tiger where Name like '_熊';
分组查询group by
- –单独查询(单独使用group by查询的是每组中的一条数据,意义不大)
- 下例按照动物种类进行分组
select * from tb_tiger group by Kind;
- 分组查询–与函数一起使用(统计每组数量,最大值,平均值等)
//查询每组有几行
select count(*) from tb_tiger group by Kind ;
//查询每组动物数量最大的数量
select Max(Number) from tb_tiger group by Kind ;
- 分组查询–与having关键字一起用
- HAVING关键字和WHERE关键字的作用相同,都是用于设置条件表达式,对查询结果进行过滤。
- 两者的区别,HAVING关键字后,可以跟聚合函数,而WHERE关键字不能,通常情况下,HAVING关键字,都是和GROUP BY一起使用,用于对分组后的结果进行过滤
select * from tb_tiger group by Kind having Number>30000;
联合查询 union
- 使用union关键字连接两个查询语句,查询结果合成一个表
聚合函数 sum;count;max;min;avg
- sum(求和)、count(*)(记录数)、max(最大值)、min(最小值)、avg(平均数)
order by 排序
- asc升序
- desc降序
select * from tb_tiger order by Number desc;
limit 控制查询条目
- limit x,y
- limit x
//查询表前5行
select * from tb_tiger limit 5,6;
//从数据表第5行往后数6行
select * from tb_tiger limit 5,6;
去掉重复distinct
- distinct关键字
select distinct Kind from tb_tiger;
多表查询
- 内连接(join / inner join)
- 外连接(left join / left outer join;right join / right outer join)
- 内连接使用比较运算符根据每个表共有的列的值匹配两个表中的行。
- 左向外连接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
- student和teacher表
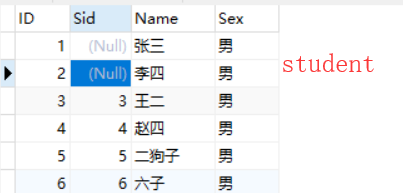
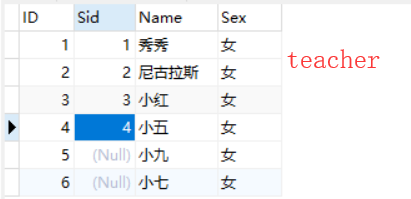
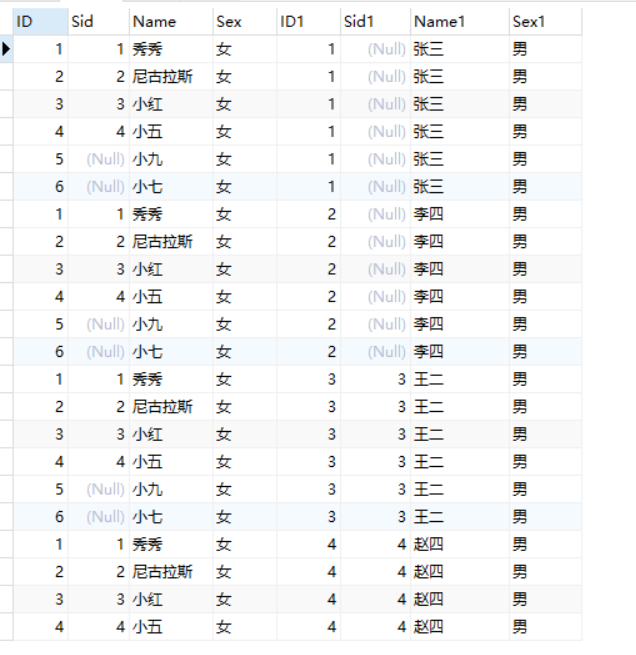
1. 内连接
select a.*,b.* from student a join teacher b;
结果为:
2. 内连接
select a.*,b.* from student a join teacher b where a.sid=b.sid;
//或
select a.*,b.* from student a join teacher b on a.sid=b.sid;
结果为:

3. 外连接
4. 左外连接
select a.*,b.* from teacher a left join student b on a.sid = b.sid;
结果为:
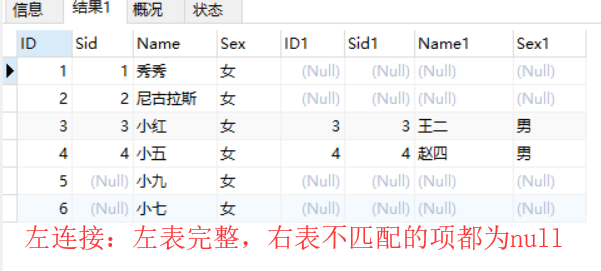
5. 右外连接
扫描二维码关注公众号,回复:
3269269 查看本文章

select a.*,b.* from teacher a right join student b on a.sid = b.sid;
结果为:
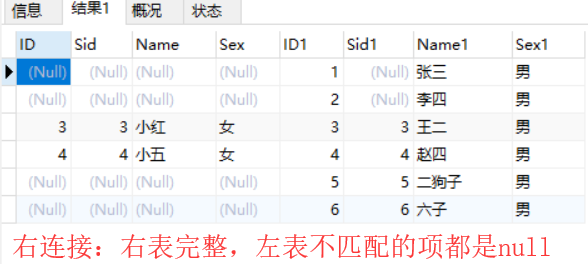
带in关键字的子查询
- 下例中()里面的结果为1,2,3,4;其作为条件查询student表里id为1,2,3,4的信息
select * from student where id in(select sid from teacher);
结果为: