Elasticsearch是一个开源的搜索引擎,是一个建立在全文搜索库Apache Lucene库中上。Lucene可以说是当下不论是私有还是开源中,最先进,功能最全,高性能的搜索引擎库。
但是Lucene仅仅是一个库,你需要使用Java将Lucene集成到应用程序中。
Elasticsearch是用Java编写的,它的内部使用Lucene做搜索和索引,但是它的目的是为了让全文搜索变得更简单,通过隐藏Luncene的复杂性,取而代之提供了一套简单一致的 RESTful API。
然而Elasticsearch不仅仅是Lucene,也不仅仅是全文搜索引擎。它可以被下面这样准确的来形容:
1)一个分布式的实时文件储存,每个字段可以被搜索与索引
2)一个分布式实时分析搜索引擎
3)能胜任上百个服务节点的扩展,并支持PB级别的结构化和非结构化的数据
Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
如果你正在使用 Java,在代码中你可以使用 Elasticsearch 内置的两个客户端:
节点客户端(Node client)
节点客户端作为一个非数据节点加入到本地集群中。换句话说,它本身不保存任何数据,但是它知道数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。
传输客户端(Transport client)
轻量级的传输客户端可以将请求发送到远程集群。它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。
以上两个Java客户端都是通过9300端口并使用Elasticsearch的原声 数据传输协议和集群交互,集群中的节点通过端口9300进行通信,如果9300端口未打开,节点将无法形成一个集群
那我们直接上手了,如果ES环境没搭建好的话可以参照笔者的另一篇ELK安装的博客。
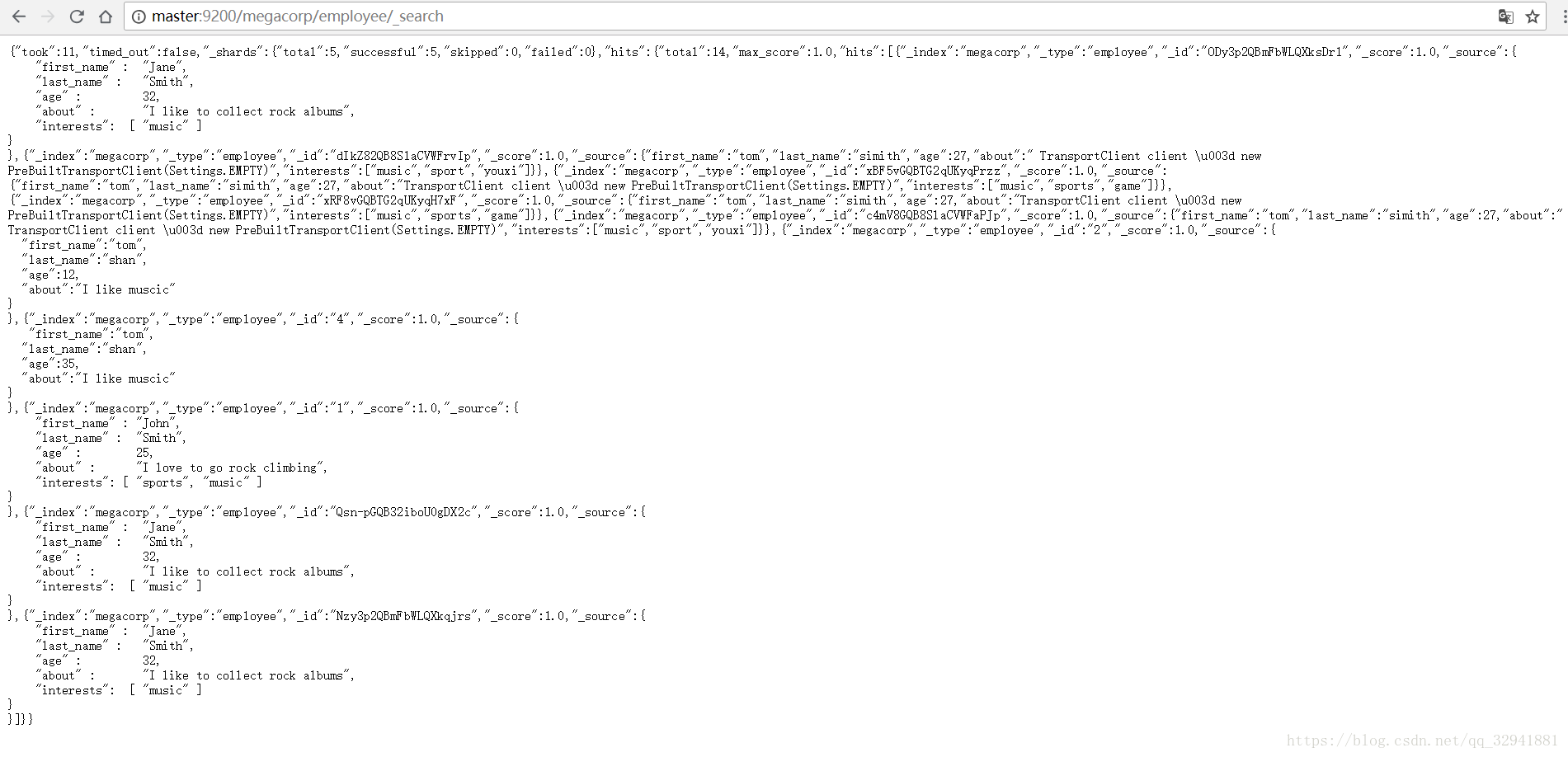
我们启动ES和Kibana,在Kibana创建一个索引文档:
- 每个文档都将是
employee类型 。 - 该类型位于 索引
megacorp内。 - 该索引保存在我们的 Elasticsearch 集群中。
注意,路径 /megacorp/employee/1 包含了三部分的信息:
megacorp
索引名称
employee
类型名称
1
特定雇员的ID
这时候右界面就显示出我们创建的这个索引文档的内容了,当然我们也可以通过xshell命令去查看我们ES集群中的索引文档
我们通过命令 curl -XGET 路径 你的主机名和IP 你的索引名(类似于mysql中的数据库) 你的索引类型和指定的ID

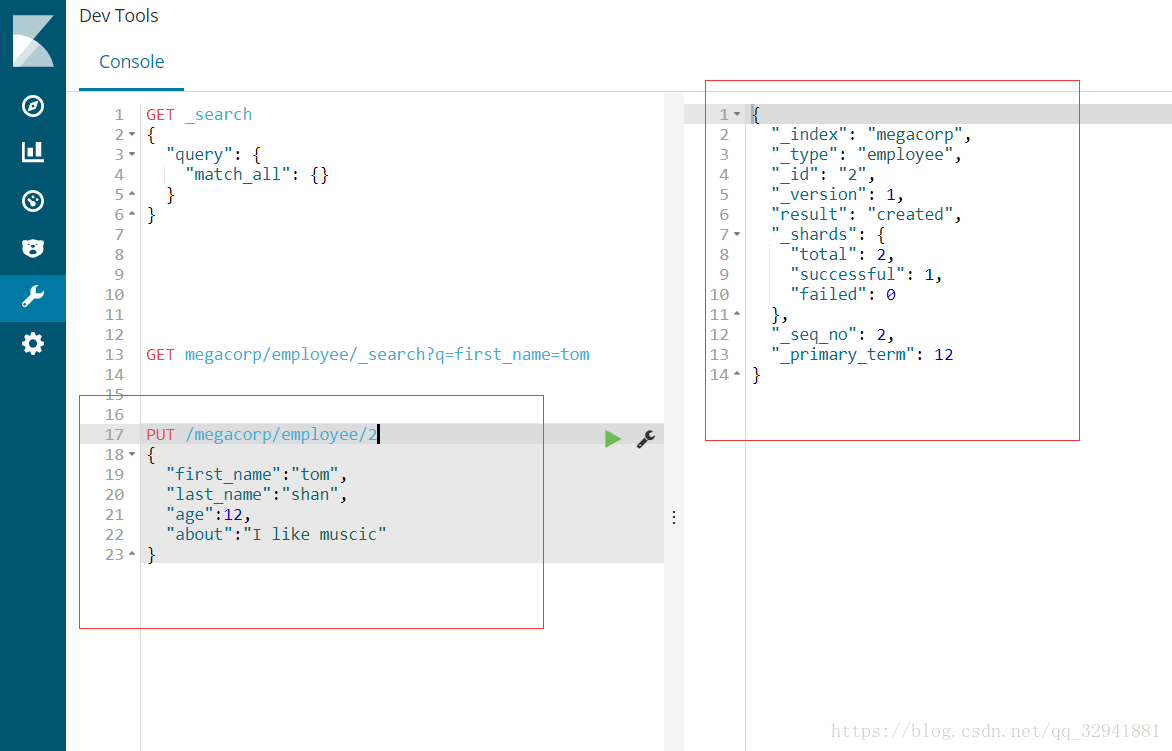
那么我们在kibana中可以通过命令查看 创建 如:
创建:PUT/索引名称/索引类型/ID
查看:关键字GET /索引名称/索引类型/ID
查看所有:GET /megacorp/employee/_search _search是查看所有的意思
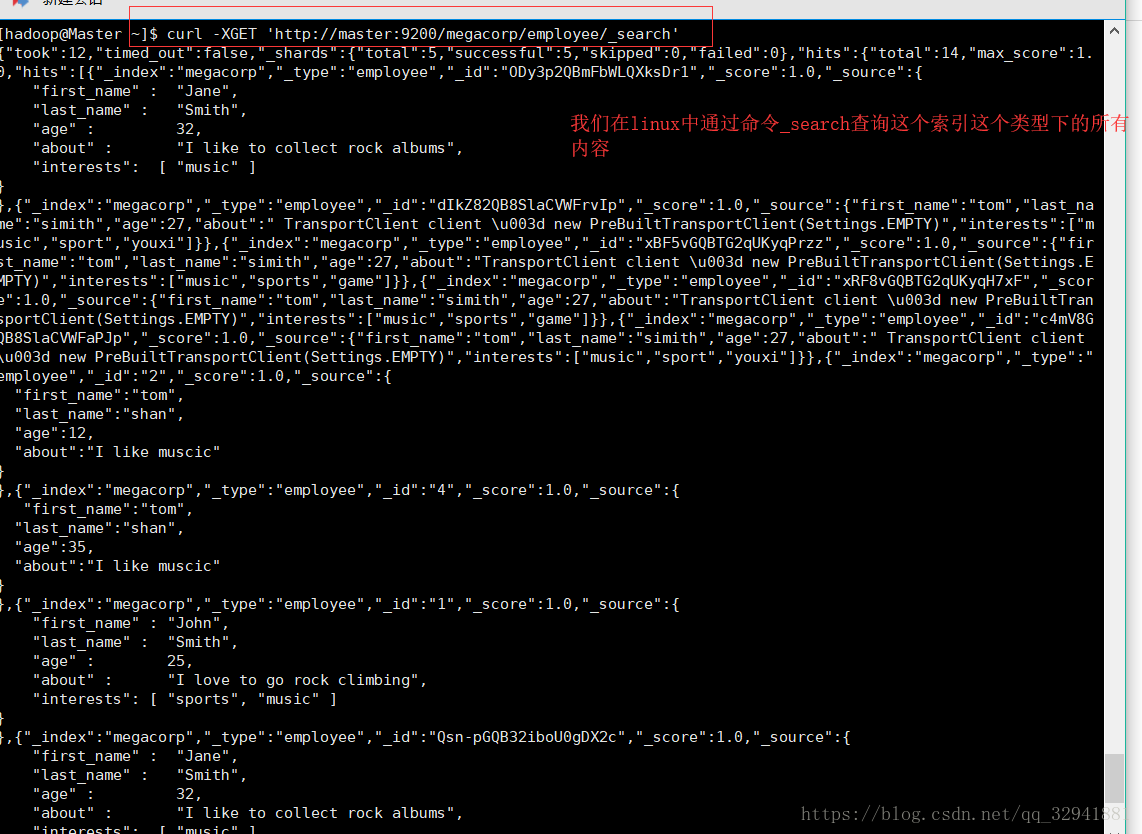
那我们再来个条件查询 按照姓氏进行查询
我们仍然在请求路径中使用 _search 端点,并将查询本身赋值给参数 q= 。返回结果给出了所有的 shan:
GET megacorp/employee/_search?q=last_name:Shan
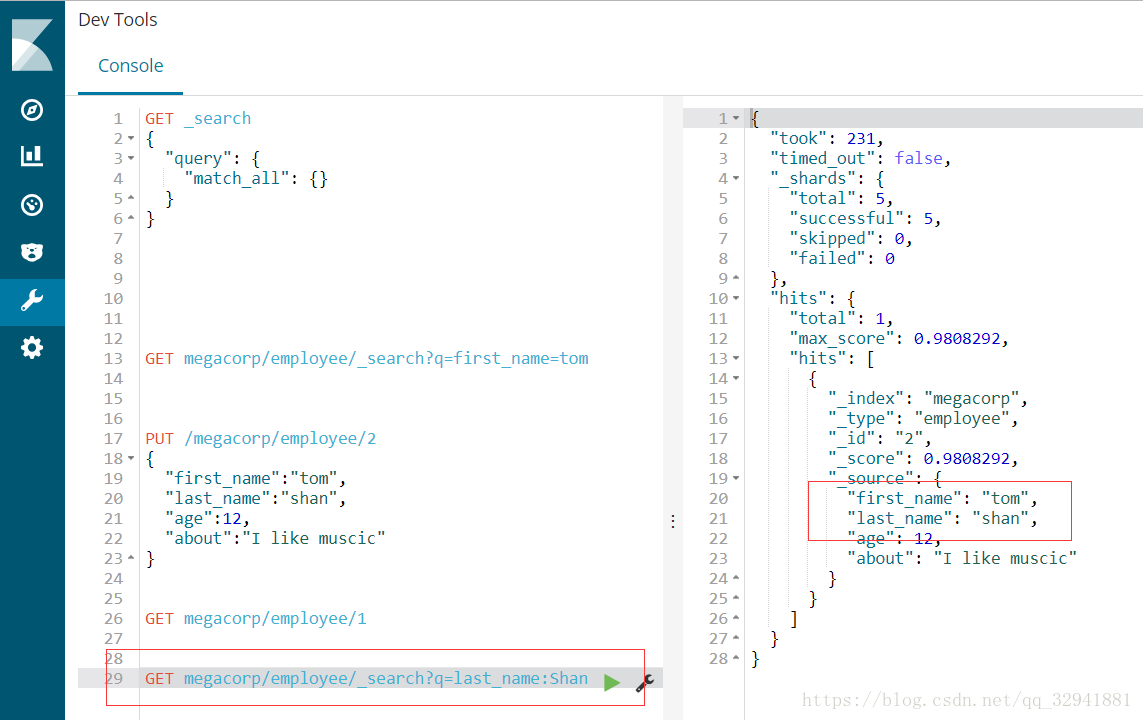
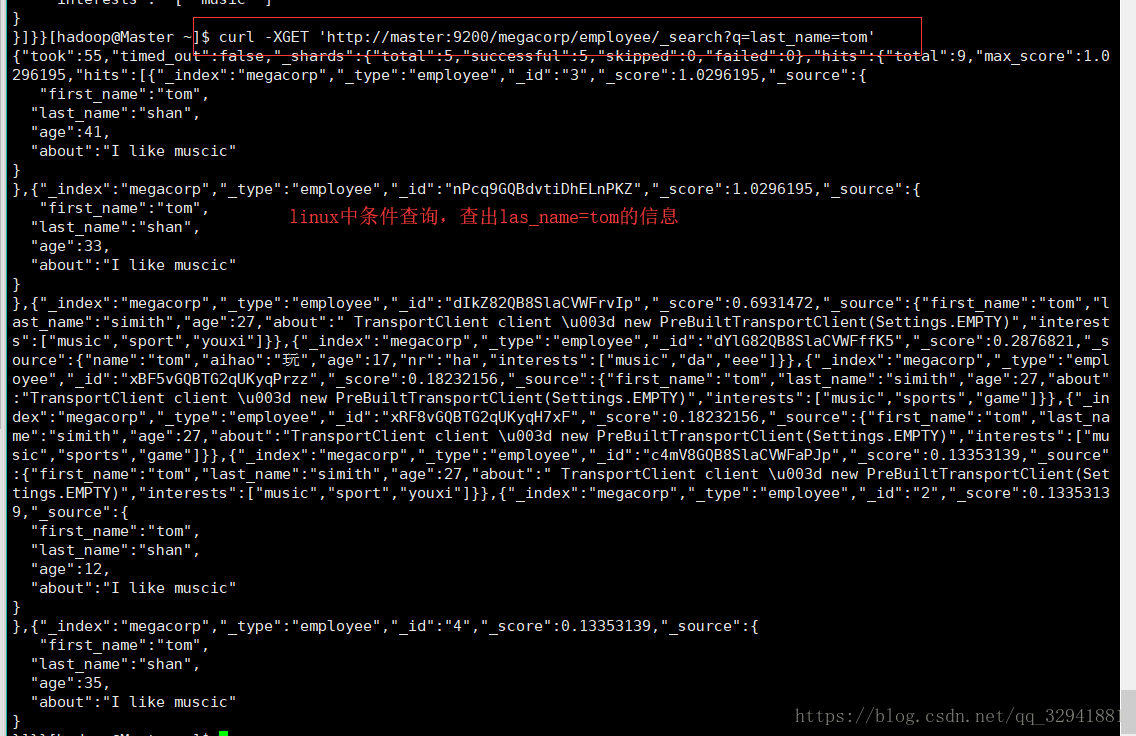
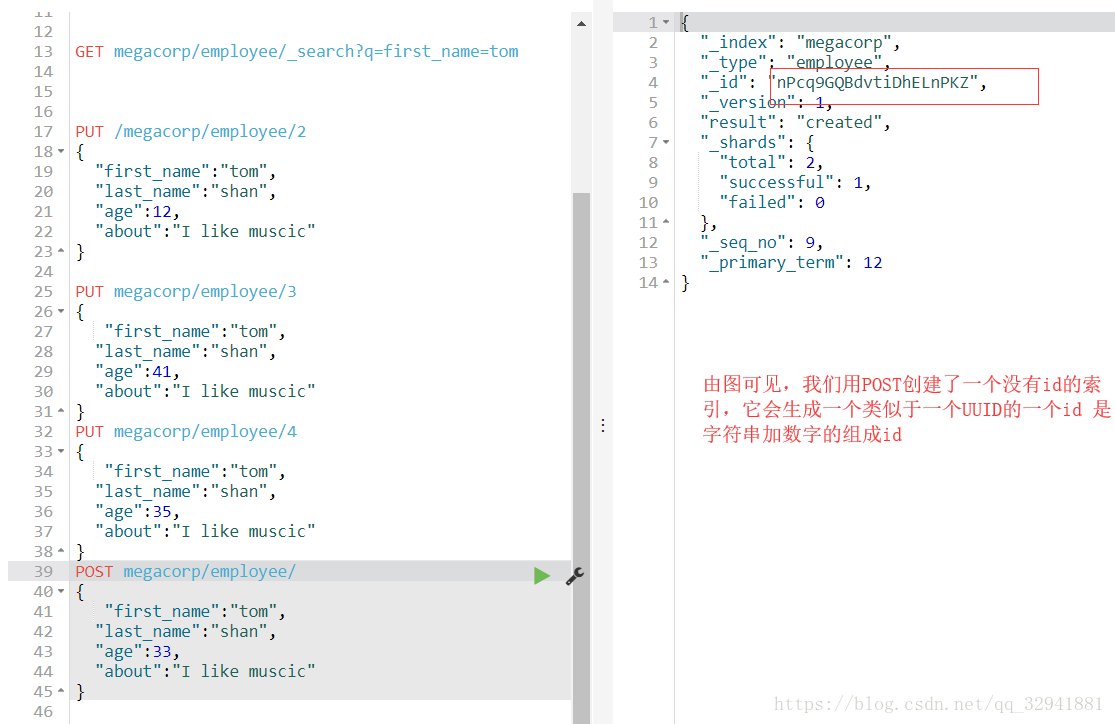
我们可以多创建几个索引文件,用于我们操作复杂一些的条件查询
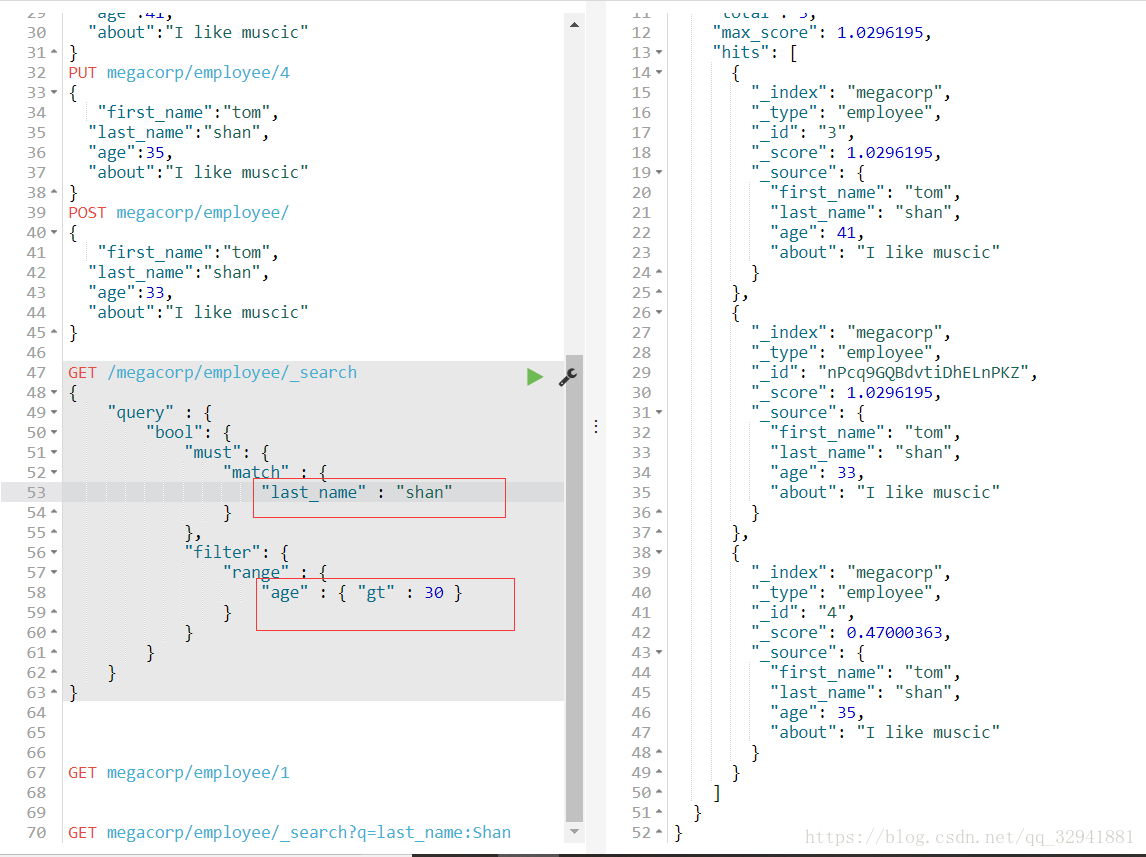
我们这次查询一个姓氏为shan 年龄大于30岁的所有信息
我们也可以在页面输入主机名或IP加端口号和索引名称类型查看全部索引信息