版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/82381545
1 hive 自定义函数开发
1.1 测试案例——大写字母转换为小写
1.1.1 给工程导入包
1.1.2 源码打包成 jar
然后上传到服务器
package udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class ToLowerCase extends UDF {
public String evaluate(String field){
String result = field.toLowerCase();
return result;
}
}1.1.3 将jar包添加到hive的classpath

1.1.4 创建临时函数与开发好的java class关联
create temporary function tolow as 'udf.ToLowerCase';
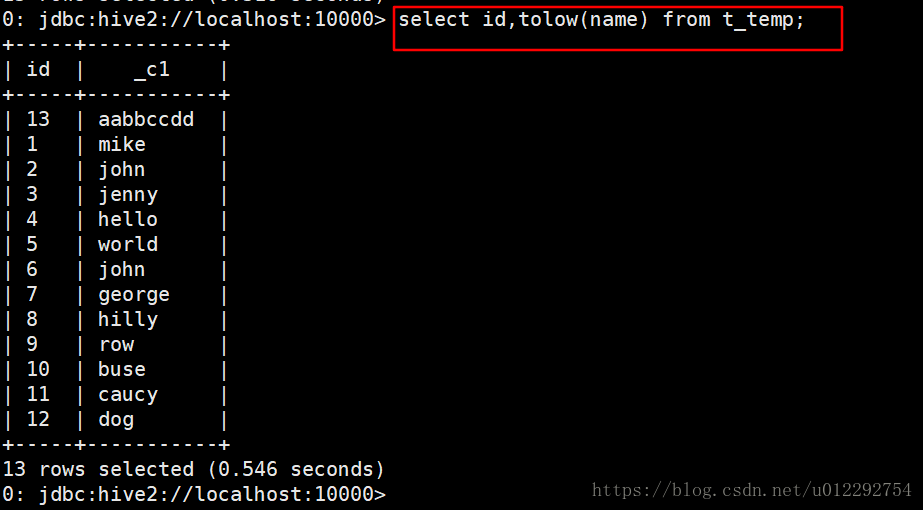
1.1.5 测试函数
0: jdbc:hive2://localhost:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| school |
+----------------+
2 rows selected (0.176 seconds)
0: jdbc:hive2://localhost:10000> use school;
No rows affected (0.192 seconds)
0: jdbc:hive2://localhost:10000> show tables;
+-----------+
| tab_name |
+-----------+
| a |
| b |
| course |
| sc |
| student |
| t_buck |
| t_temp |
+-----------+
7 rows selected (0.191 seconds)
0: jdbc:hive2://localhost:10000> select * from t_temp;
+------------+--------------+
| t_temp.id | t_temp.name |
+------------+--------------+
| 1 | Mike |
| 2 | John |
| 3 | Jenny |
| 4 | Hello |
| 5 | World |
| 6 | John |
| 7 | George |
| 8 | Hilly |
| 9 | Row |
| 10 | Buse |
| 11 | Caucy |
| 12 | Dog |
+------------+--------------+
12 rows selected (1.811 seconds)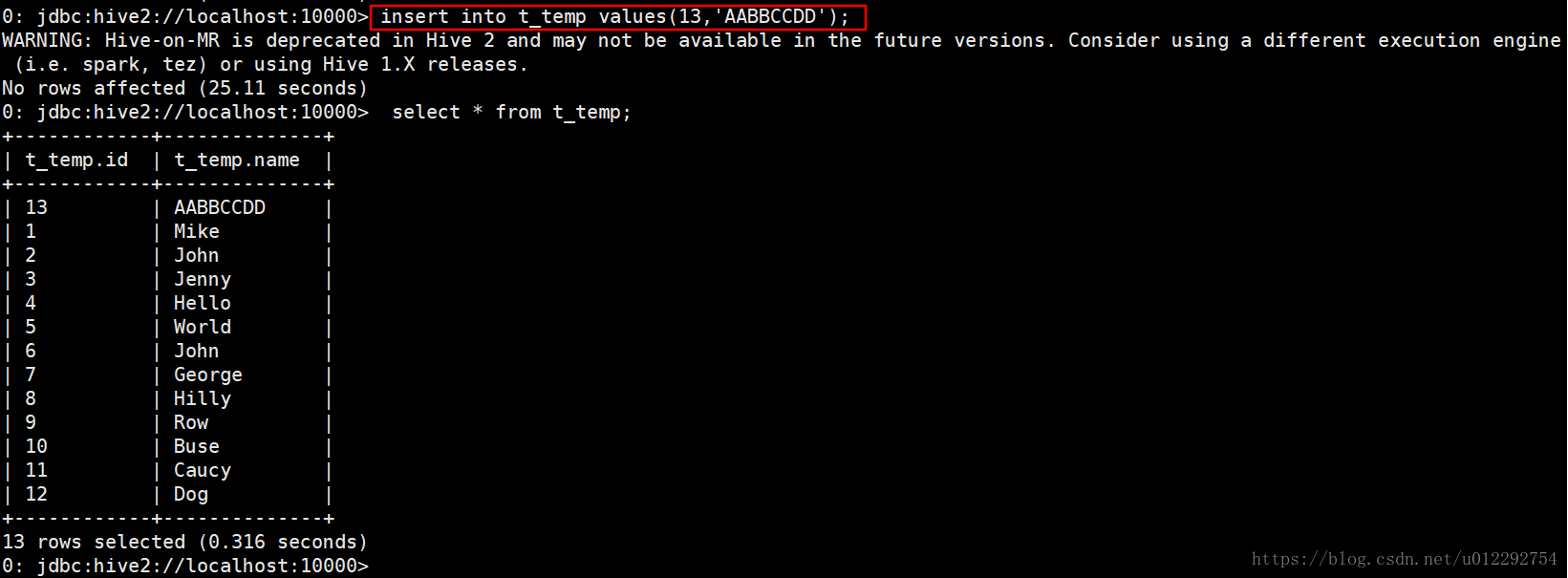
增添了一条数据,hdfs 不会修改原文件
1.2 测试案例——流量分类
1.2.1 源码打包为 jar,上传到服务器
package udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.HashMap;
public class ToLowerCase extends UDF {
public static HashMap<String, String> provinceMap = new HashMap<>();
static {
provinceMap.put("136", "Beijing");
provinceMap.put("137", "Shanghai");
provinceMap.put("138", "Guangzhou");
}
public String evaluate(String field) {
String result = field.toLowerCase();
return result;
}
public String evaluate(int phoneNbr) {
String pnb = String.valueOf(phoneNbr);
return provinceMap.get(pnb.substring(0,3)) == null ? "No-Result" : provinceMap.get(pnb.substring(0,3));
}
}
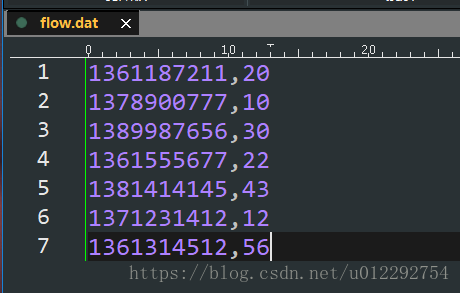
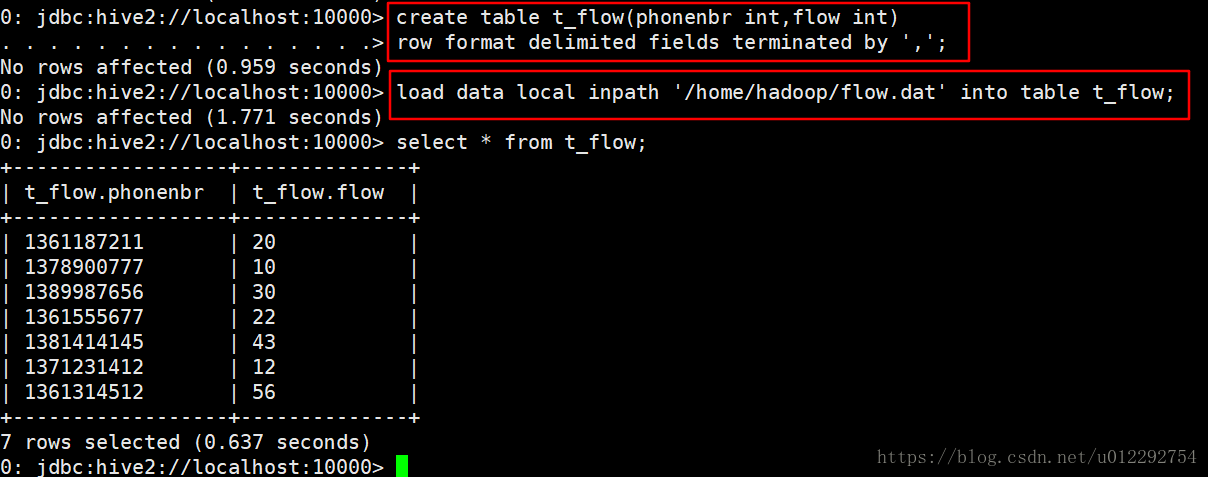
1.2.2 建表导入数据
1.2.3 将jar包添加到hive的classpath

1.2.4 创建临时函数与开发好的java class关联
create temporary function getprovince as 'udf.ToLowerCase';
1.2.5 测试函数
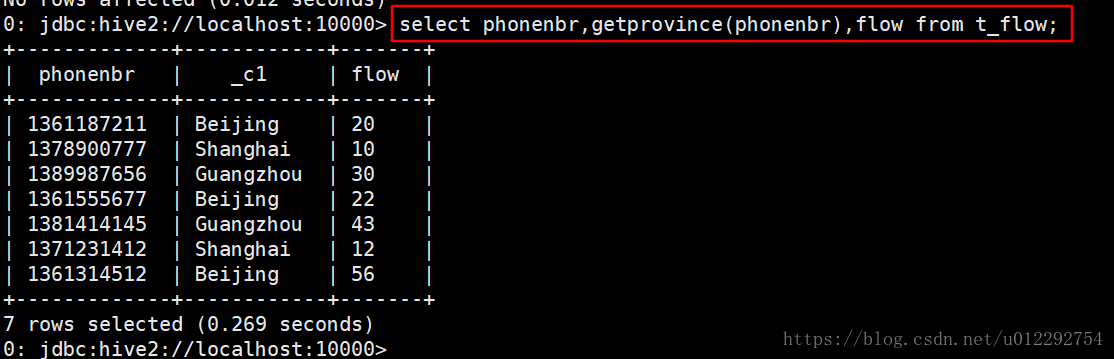
1.3 json 数据解析 案例
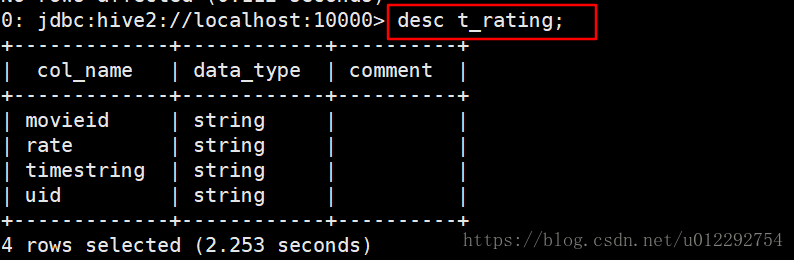
1.3.1 新建表导入数据
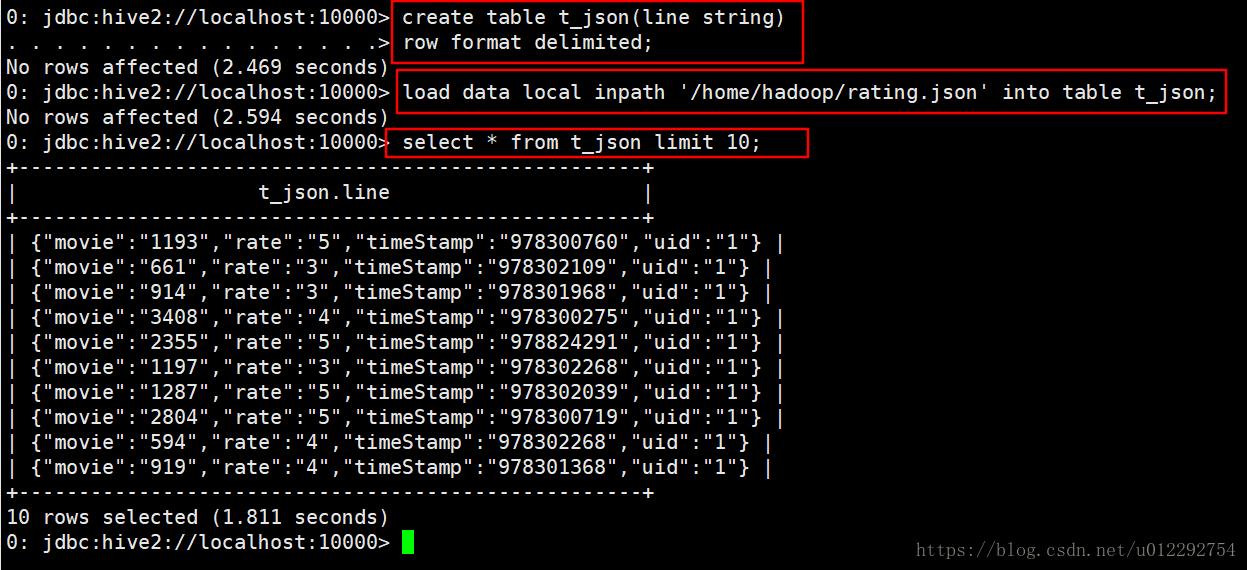
1.3.2 把源码打包为 jar,上传到服务器
package udf;
public class MovieRateBean {
private String movie;
private String rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
return
movie + '\t' + rate + '\t' + timeStamp + '\t' + uid ;
}
}
package udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
public class JsonParser extends UDF {
public String evaluate(String jsonLine) {
ObjectMapper objectMapper = new ObjectMapper();
try {
MovieRateBean bean = objectMapper.readValue(jsonLine, MovieRateBean.class);
return bean.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
}
1.3.3 将jar包添加到hive的classpath
add JAR /home/hadoop/udf.jar;
1.3.4 创建临时函数与开发好的java class关联
create temporary function parsejson as 'udf.JsonParser';
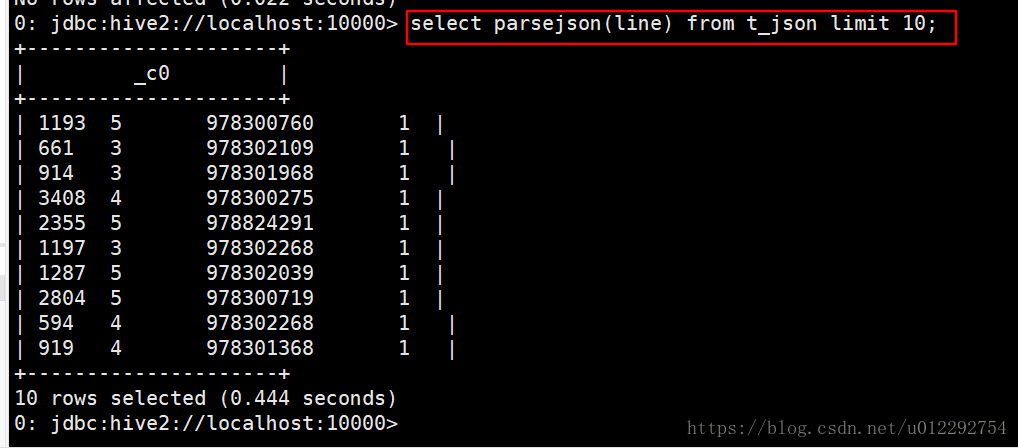
1.3.5 测试函数
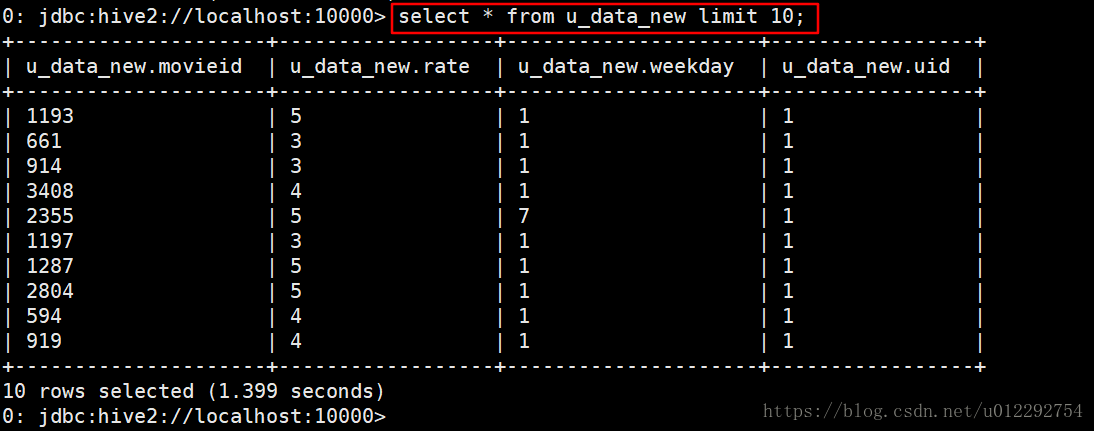
select parsejson(line) from t_json limit 10;
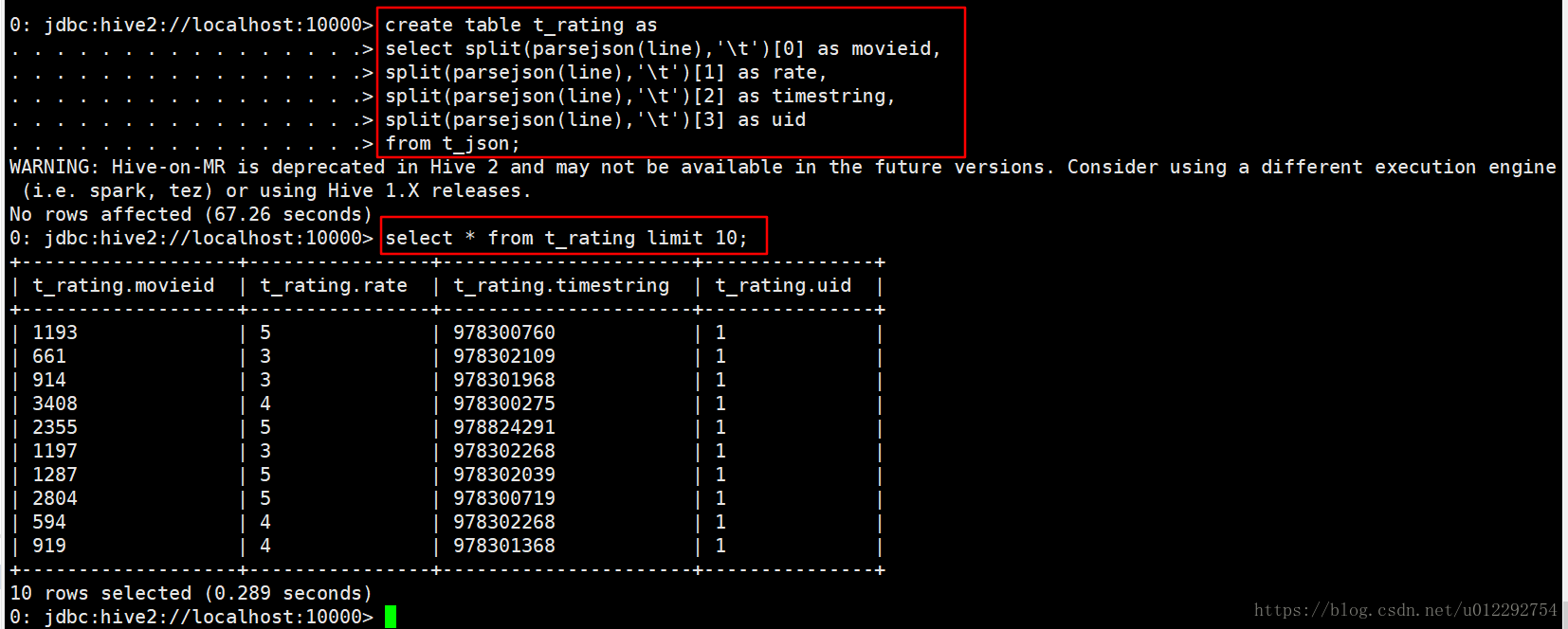
2 Transform实现
Hive的 TRANSFORM 关键字提供了在SQL中调用自写脚本的功能。适合实现Hive中没有的功能又不想写UDF的情况
2.1 weekday_mapper.py
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])

2.2