NeST:基于生长和剪枝生成神经网络
在此之前,传统调试神经网络的方法是:调整影响识别的因素,如设置的所有参数、激活函数、优化器、网络的结构等,传统神经网络的调试可以理解为“不断尝试试错”,最后从识别结果上来调整每层的参数及其他。
but…这样的识别结果可能也不好。
传统调试神经网络的弊端
由此可以引出传统网络调试的3个主要弊端:
- 结构是固定的:以BP(反向传播)为基础的调试方法仅仅能调整各个神经元的权重。
- 相当耗时:若网络越来越深,涉及到的参数及影响因素也越来越多,传统方法可能相当费时费力。
- 大量冗余:在参数个数和算力方面可能需求过剩,大多神经网络都显著的过参数化。实验证明AlexNet的浮点操作次数可以缩小3倍,参数个数可以缩小9倍且没有准确度损失。
在这可以发现,手工调整神经网络是存在大量问题的。因此就想设法让计算机能够自动调整网络结构和参数个数。
Related Work:过去主要有两方面的尝试
- 演化算法(Evolutionary Algorithms):自1989年就有人开始研究,现在的结果是:演化算法仍然很低效。EA的搜索机制牵涉到大量累赘的迭代,这限制了演化算法的可伸缩性。例如,演化算法无法处理包含120万训练图像的ImageNet数据集,目前最先进的演化算法只支持CIFAR-10和CIFAR-100数据集,每个数据集包含5万张32x32训练图像。
- 结构调整:分为两种方法:
1、构建方法:从一个小网络开始,不断添加神经元和连接直到达到需求准确率。
2、解构方法:从一个大网络开始,不断移除神经元和连接直到达到需求准确率。
仔细看这两种方法的定义,我们就能发现这两种方法的缺陷:
1、在构建方法中,随着迭代的进行,连接和神经元会不断增加,直到达到所需精确度而停止。也就是说,迭代并不顾忌网络复杂度的增加,一心为了追求精确度的提高而不断生长。因此,最终生成的网络往往有很多冗余。
2、在解构方法中,仅仅在保证不影响精确度的前提下追求网络大小的减小,因此只能保持初始的精确度,而无法提高精确度。也就是说,破坏性方法依赖一个完全训练好的精确的初始网络。
我们发现上述两种方法的缺陷可以互补,所以综合以上两种方法,提出了一种综合方法:先构造再解构。
启发来源于人脑,婴儿时期,神经元连接数目快速增长,后趋于峰值。达到成人时期后,神经元连接逐步减少并趋于稳定。
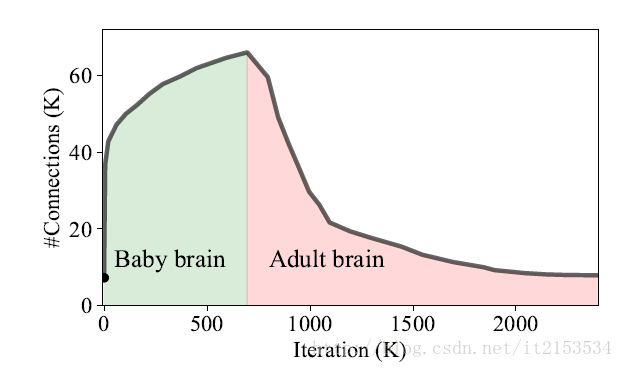
图1 人脑神经元连接数目对比不断迭代的LeNet-300-100网络中的神经元的连接数目
Synthesis Methodology:调试神经网络的新方法
由下图所示,合成方法分为一下几个步骤:
- 从一个小的初始种子结构开始。
- 基于梯度信息扩张网络:不断增加连接或神经元提高准确率。
- 基于幅值信息对网络剪枝:优化多余连接及神经元且不降低准确率。
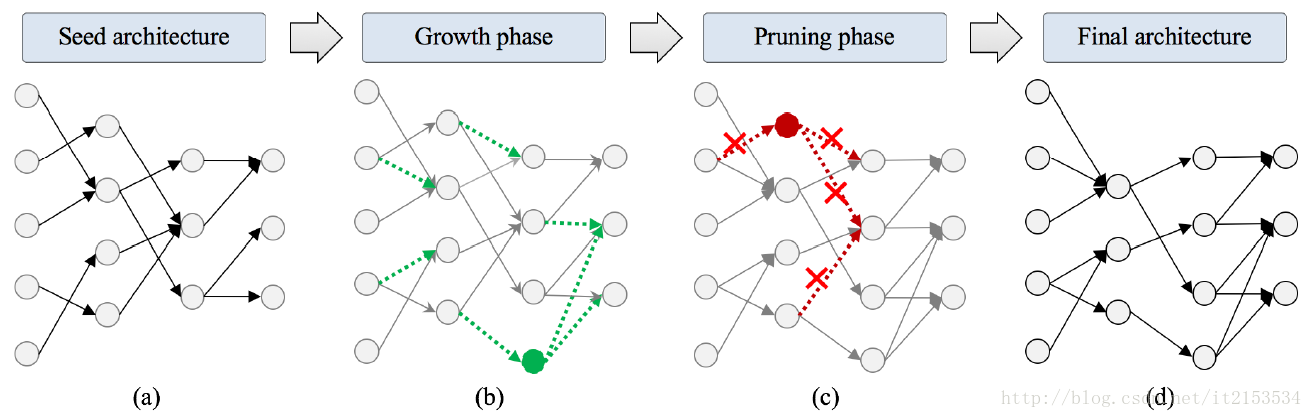
图2 NeST流程
NeST中的架构算法如下:
Input: S - maximum size, A - desired accuracy, Net - neural network
s = sizeof(Net) # s为当前网络神经元个数
a = test(Net) # a为当前网络在测试集的准确率
# 扩张网络阶段
train(Net) # 训练网络
if s ≤ S and a < A then # 循环直到达到神经元数量上限或准确率达到需求
repeat
Grow connections, neurons, and feature maps
Net = train(Net)
s = sizeof(Net), a = test(Net)
until s ≥ S or a > A
end if
# 剪枝阶段
repeat
Prune connections and neurons
Net = train(Net)
a = test(Net)
until a < A
Return Net
图3 算法中的主要部分
基于梯度信息扩张网络阶段
# 增加连接
Policy1: Add a connection w iff it can quickly reduce the value of loss function L .
在此阶段,目标是通过增加连接或神经元来提高网络的准确率,而网络准确率和损失函数相关。一般而言,损失函数的值越小,模型的拟合度就越高,也就意味着精确度越高。所以有了Policy1。
损失函数的下降意味着梯度的下降,所以我们用L对w求偏导来表示这个连接的梯度信息 。(L : loss function, w : a connection)
在实际连接中,我们将 指代第k层中第m个神经元的输入,将 指代第k层中第m个神经元的输出。
所以我们在第k和k+1层增加连接时,将第k+1层的输入刺激量定义为
,将第k层的输出刺激量定义为
。当连接被激活时,据Hebbian theory,突触强度增加,到达值
,所以有等式如下:(令该值用
表示)
# 神经元增加
神经元增加算法分为一下两个步骤:
- 连接的创建:即神经元应该添加在何处?
- 权值初始化:新增神经元初始权重应为多少?
Policy2:In the layer, add a new neuron as a shared intermediate node between existing neuron pairs that have high postsynaptic (x) and presynaptic ( ) neuron correlations (each pair contains one neuron from the layer and the other from the layer). Initialize weights based on batch gradients to reduce the value of L.
重申一点:所谓神经元的增加,并不是增加层数,在k和k+1层之间增加神经元,而是在第k-1和k+1层之间增加神经元,即在第k层增加神经元,所以由此可知,NeST方法是不能增加网络层数的。
算法选择在输出刺激量和输入刺激量高的两层神经元之间增加神经元。考虑到下一阶段为剪枝阶段,将移除神经元之间较弱的连接,所以的确应当在连接较强的神经元之间加入新的神经元。
所以算法将筛选k-1层到k+1层j间可能较强的神经元连接,因为已知第k-1层所有神经元的输出和第k+1层所有神经元的输入,利用上文提到的 建立一系列桥接梯度,具体实现如下:
根据上文提到的规则:第k-1层的输出值为: , 第k+1层的输入值为 。由神经网络结构可知,第k层的输入为第k-1层的输出,第k层的输出为第k+1层的输入。令连接为w~b~,连接 和 。
首先我们需要得到两个等式:
BP算法更新权重公式根据设置的值有以下公式:
文章中设置初始化权重的值为梯度的平方根:
其中: 是新增神经元与 的连接上的初始化权重值, 同理。由此假设可推出下列公式:
上述公式是一个简单神经元推导式, 是激活函数。此处选取双曲正切函数 ,当x非常小时,此函数近似为 。由此可继续推导:
上述公式的约等于是假设 和 都非常小的情况下得到的。从公式可以看出,通过设置初始化权重为桥接梯度的平方根可以使权重的更新呈线性变化,因此实现BP权值更新算法。
后续为增加新神经元所建立连接的强度,设置参数 ,为避免这些新建连接在剪枝阶段被剪掉。

图4 神经元生长算法
#巻积层核的增加
Policy 3: To add a new feature map to the convolutional layers, randomly generate sets of kernels, and pick the set of kernels that reduces L the most.
对于卷积层来说,神经元的增加相当于卷积核的增加,该文章对增加卷积核的方法设置很简单。
基于幅值信息的剪枝阶段
Policy 4: Remove a connection (neuron) iff the magnitude of the weight (neuron output) is smaller than a pre-defined threshold.
即剪掉那些没有显著影响的神经元和连接。
#剪掉非显著连接
该步骤需要对权重进行标准化,具体而言使用了批量规整化技术,通过规整化层输入来减少内部协变量的变化。批量规整化能显著提升训练速度和表现,对于大型神经网络尤为适用。
用迭代的方式逐步移除非显著权重。在每一次迭代中,我们只移除最不显著的权重,然后重新训练整个神经网络以恢复因为移除非显著权重而可能造成的损失。
#部分区域卷积
卷积计算时,参数所占内存约5%,,而浮点操作和计算负荷占内存90%~%95。优化该部分前提是发现核卷积计算存在冗余,因为核不一定对整张图片都感兴趣,由此我们需要减去核不感兴趣部分。

图5 部分核卷积算法
值得一提的是,此处运用Hadamard矩阵乘积,此乘积是使两个矩阵对应位置元素相乘积,所以可以通过建立一个Msk矩阵来屏蔽图中不感兴趣部分的值。
总结
NeST其实是基于现有模型进行优化调整的,不能更改结构只能减少参数和计算量。
实验结果见原论文:NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm
参考:
https://baijiahao.baidu.com/s?id=1584805452475827734&wfr=spider&for=pc