find的补充
find不用-regex而是用我们以前用的-name的话是可以用相对路径来查找的,但是相对路径也必须要输全了。

awk的小应用
以前我们用sed做过这个事情,现在我们用awk来做这个事情就会比较简单。

这个应该不需要解释了。那么在每一行前面加上行号也很简单了,虽然这个没办法影响到原文件。
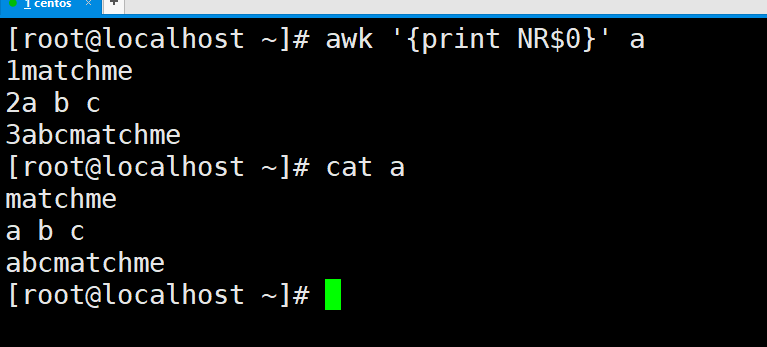
这里补充一个小知识,python里面是可以当作计算器使用的,但是bash不可以,我们可以按一个bc软件就支持了,yum -y install bc,然后输入bc,就可以在里面做一些简单的数学运算,但是看到三角函数都没有,退出的话是ctrl+c。
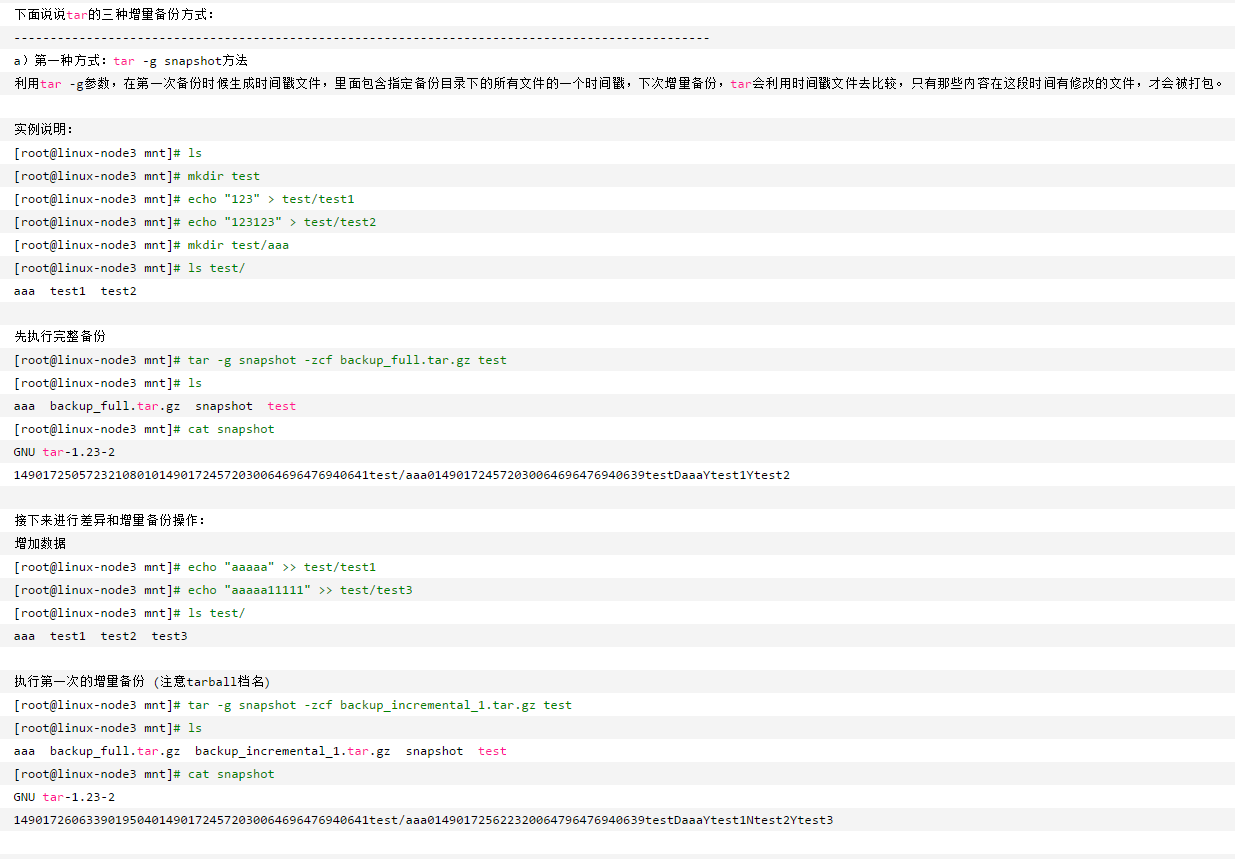
Linux全量增量备份脚本
一些服务器都是全年不关机的,那么对软件和硬件的压力还是蛮大的,说不定什么时候服务器就不行了,那么备份就相当重要了,备份其实前面就说过分为全量备份和增量备份,如果都是全量备份那存储空间的要求就太高了,一个服务器一天可能就要产生几百个G的数据,并且有些数据可能要保存好几十个年头,每天都进行全量备份,那得要多少块硬盘,而且备份肯定不要备份到本机,备份到本机如果本机的磁盘坏了还有什么意义?那么肯定备份文件传输到别的服务器就需要端口资源或者无线的话就需要网络资源,如果文件太大,这些资源的占用也很厉害。于是一般的做法是每隔一个比较长的时间进行一次全量备份,期间都进行增量备份。那么我们下面尝试写一个全量增量备份脚本,备份规则是这样的,每星期天全量备份一次,周一到周六增量备份就可以。全量备份比较简单,我们先写全量备份部分的代码,假设我要备份/etc/里面的文件,为了进一步减小占用的空间,我们用tar再把文件打包压缩一下。当然下面写的只是备份的第一部,因为备份文件还在这台服务器上,那么服务器坏了照样还是不行。第二步就是要把备份文件传输到别的主机上才行。
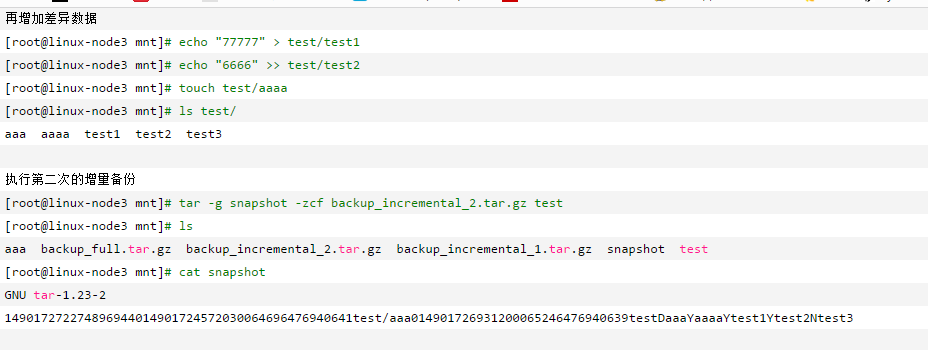
那么增量备份呢?也许你有用find -mtime 1也就是查找最近一天修改的文件这样的想法

,这种想法也是我第一下就想到的一个想法,不过这里有两个命令可以自动做到这一点,一个是rsync,另一个是tar -g。首先来看rsync吧。参考了https://www.cnblogs.com/kevingrace/p/6601088.html
rsync可能需要安装一下,yum -y install rsync。

man一下rsync,写着是一种快速,多功能的远程和本地文件拷贝工具,这个有三种大的方式,第一种是本地,也就是也就是自己的服务器和自己的服务器通信,其实这个是没有什么意义的,但是由于我的青云主机已经到期了,然后也没钱去用其他阿里云,腾讯云的主机,那么我们下面演示还是在本地演示。第二种是通过远程shell,第三种是通过rsync守护进程,我们主要还是来说第一种,我们主要是说HOST可以是别的主机名,也可以是ip。
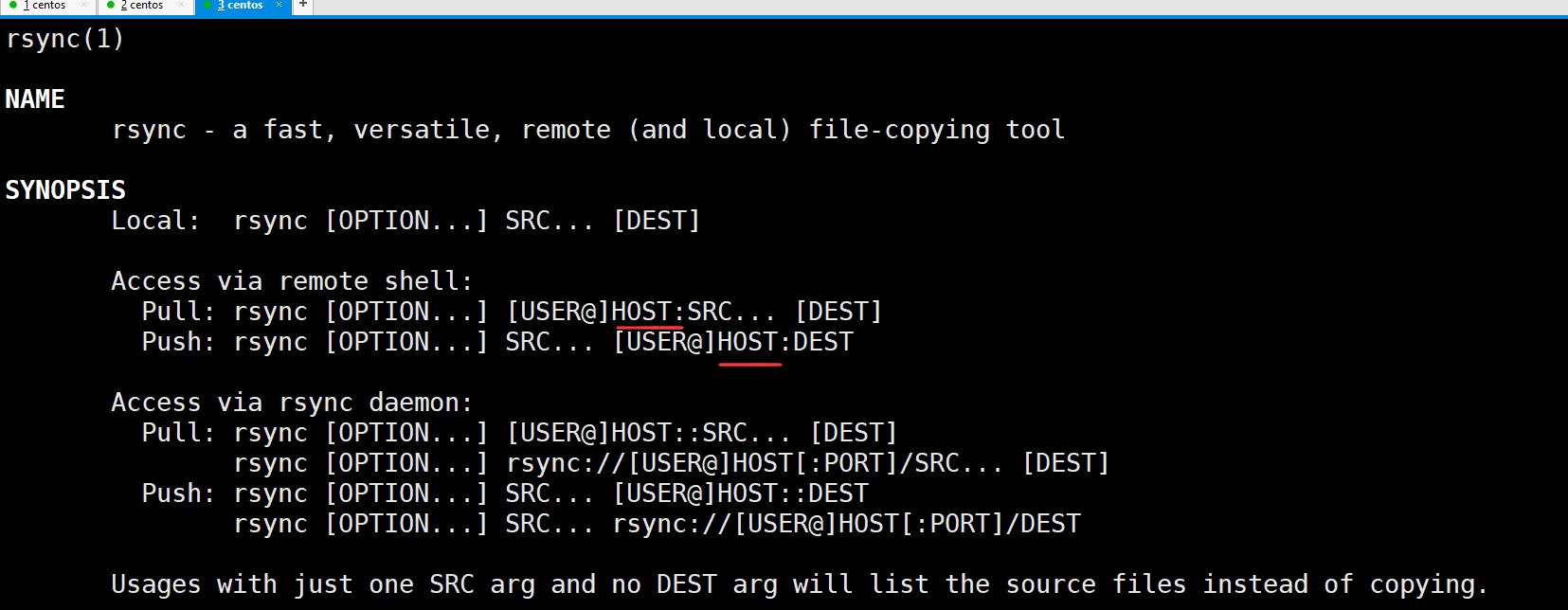
这里说一下-a,相当于-rlptoD。

-r是递归的意思,-l我们先不去管它,-p是保存权限,-o是保存所有者,-g是保存文件的属组等,-t是保存了修改的时间。

z是压缩的意思。
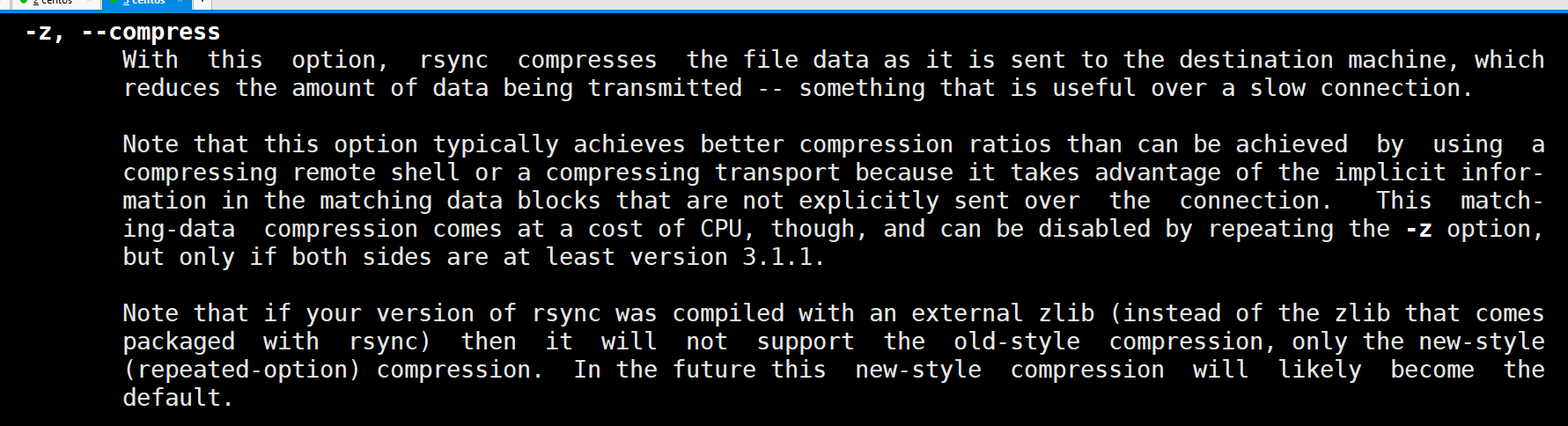
delete和上面说的意思差不多。
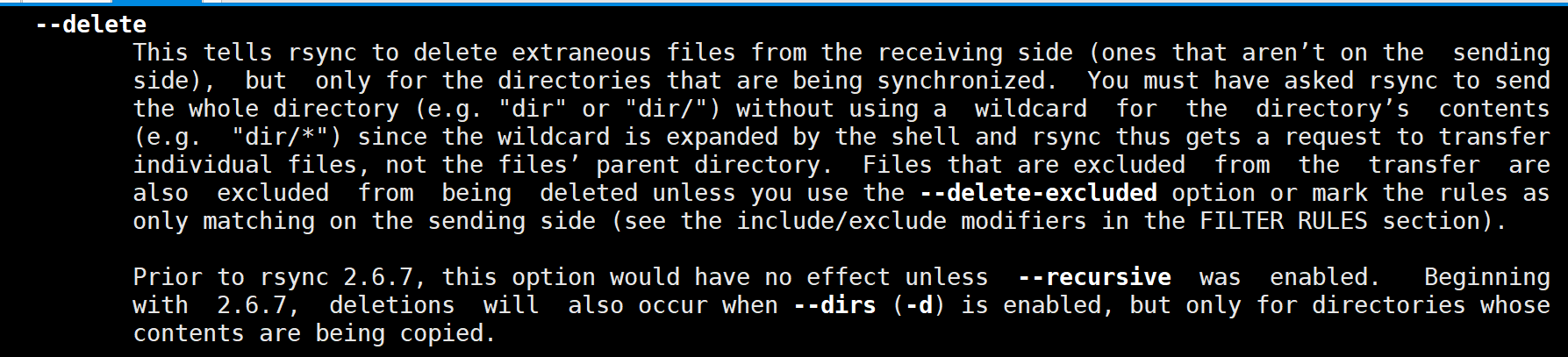
我们怎么看到的不是压缩文件呢?这是因为那些文件只是在传输过程中打包压缩了,传输到了目的地就会自动解压解包了。
由于这是第一次备份,增量备份也就和全量没什么区别。那么下面我们来一个增量备份。我们加了一个-v选项以看见备份的过程。
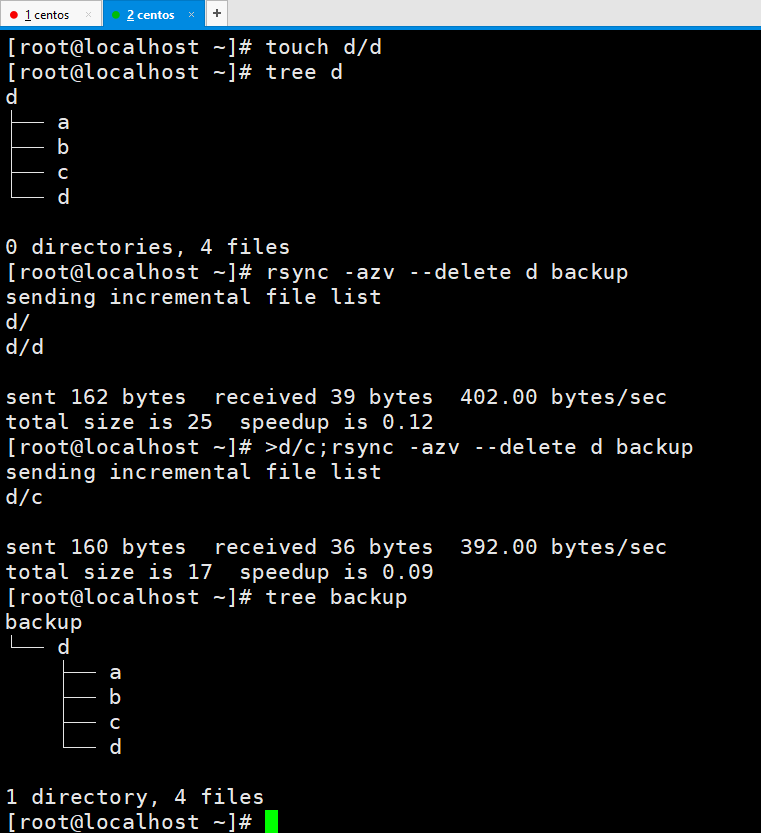
其实-z和--delete可以不要的,不过-a是得要的。
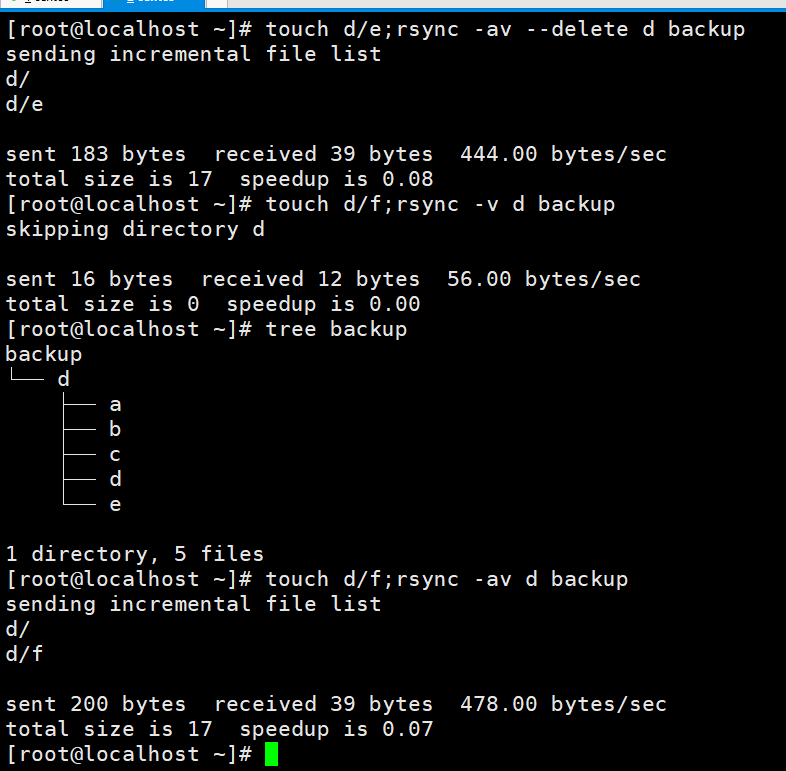

我修改了一下文件权限,看到再备份一次,备份的文件权限也跟着变了。

我们下面看一下--delete的作用。下面是不加--delete。不会删除这个g。
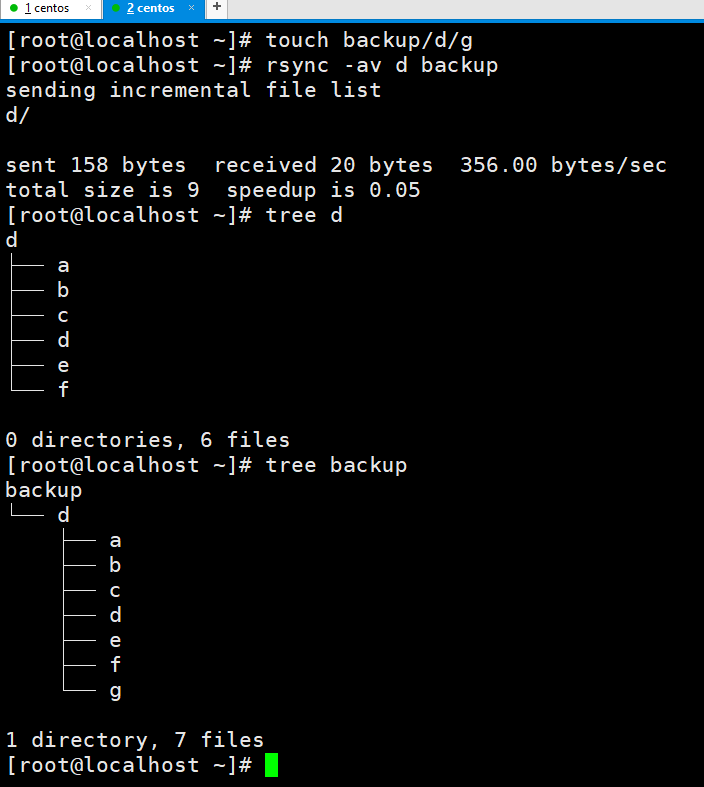
然后是加的,明确显示删除了这个g。

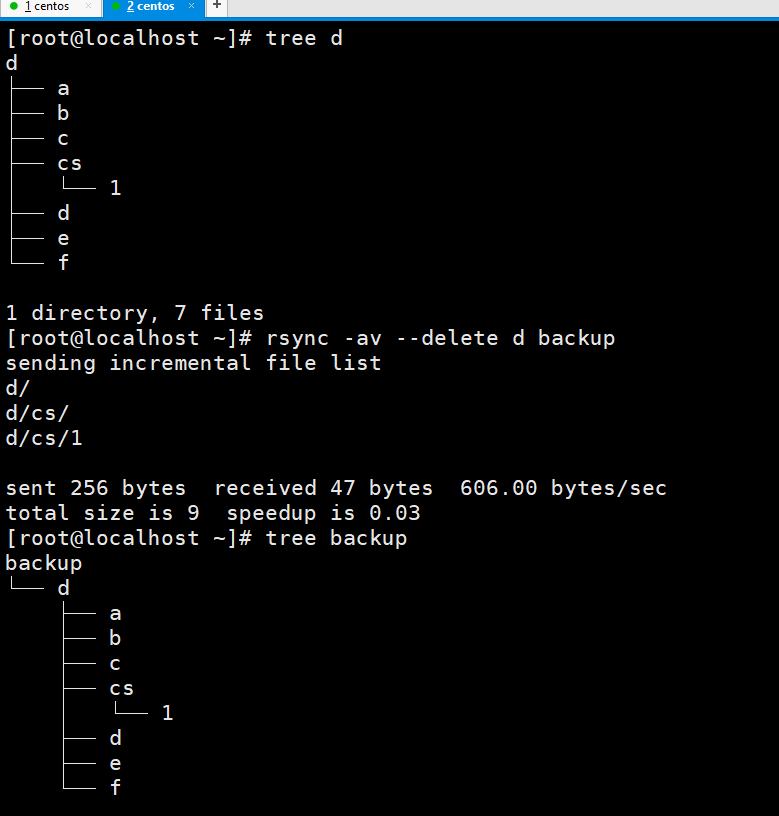

只有一个副本的意思就是说如果你改动一个文件再备份一次,那么备份文件里的这个文件也随着改动,并且原来的副本就没有了,但是其实这也不是完全对的,因为我们不一定备份到一个文件夹,我们上面是都备份到了backup文件夹,我们完全可以以备份时间命名一个文件夹,这也很简单,我们以前就用`date`这种格式实现过。
看到这个A确实没有被删除。
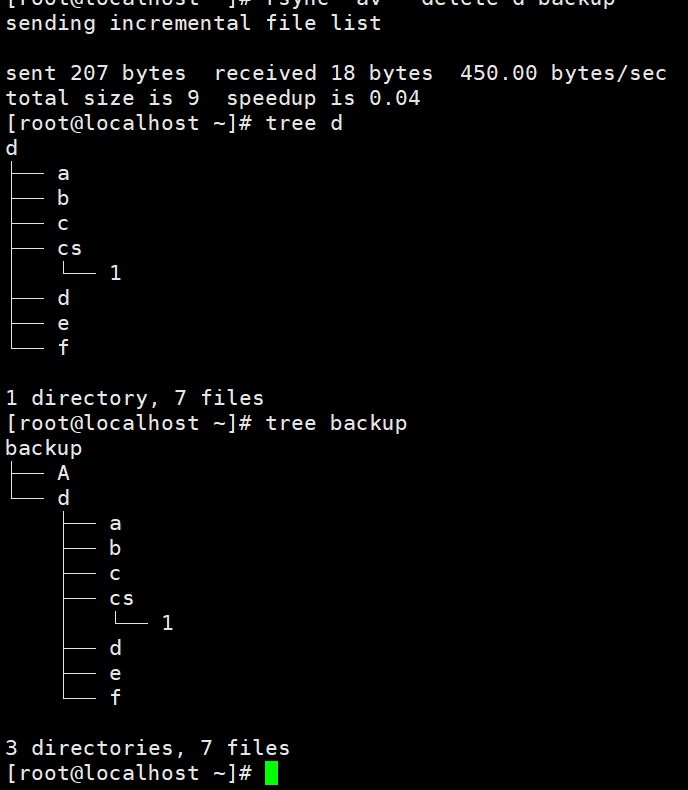
第二种是用tar -g备份。

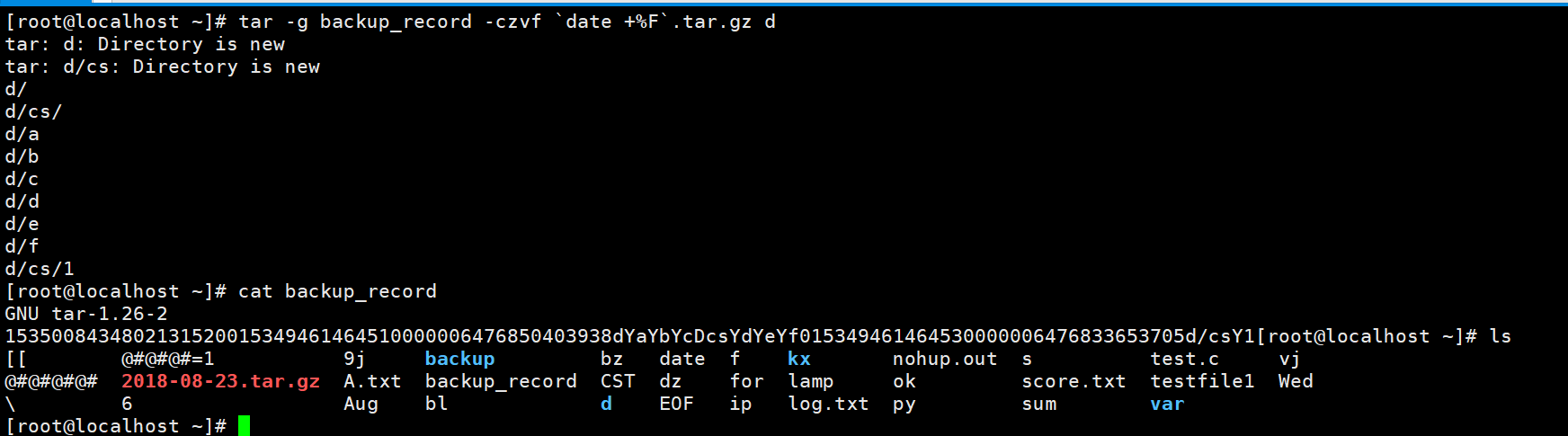
tar -g后面跟的是时间戳,那么什么是时间戳呢?这个时间戳可以自己命名的。看到里面是一串数字。

时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。通俗的讲, 时间戳是一份能够表示一份数据在一个特定时间点已经存在的完整的可验证的数据。 它的提出主要是为用户提供一份电子证据, 以证明用户的某些数据的产生时间。 在实际应用上, 它可以使用在包括电子商务、 金融活动的各个方面, 尤其可以用来支撑公开密钥基础设施的 “不可否认” 服务。增量备份就是要根据时间戳信息去只备份修改过的内容。由于上面是第一次备份,也就是全量备份了。下面看看增量备份。一次是修改了文件内容,一个是修改文件权限。看到第一次d/a等没有修改的都没有打印出来,只打印了目录的一个结构和修改过的d/a,第二次打印了目录结构和修改过权限的d/a。
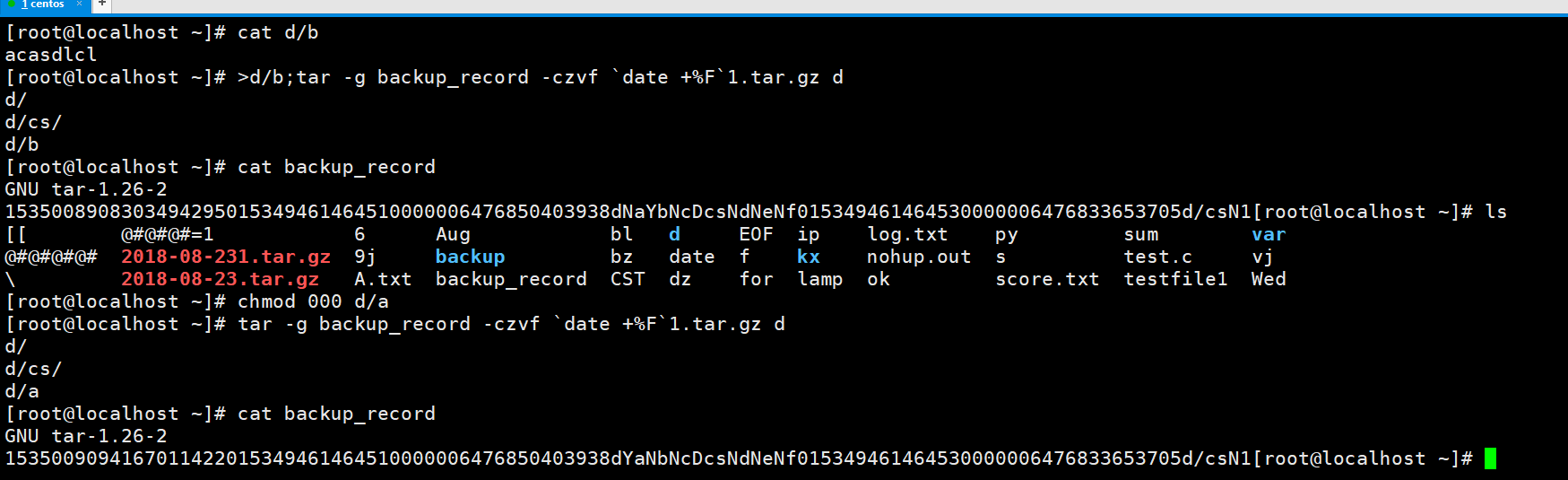
观察修改d/a前后的两个时间戳文件,是可以看到不同的,就是下面画红线的几位,可能这几位就和d/a的权限是相关的。

我们试着来解压看一看对不对。这个`date +%F`.tar.gz其实是个全量包。
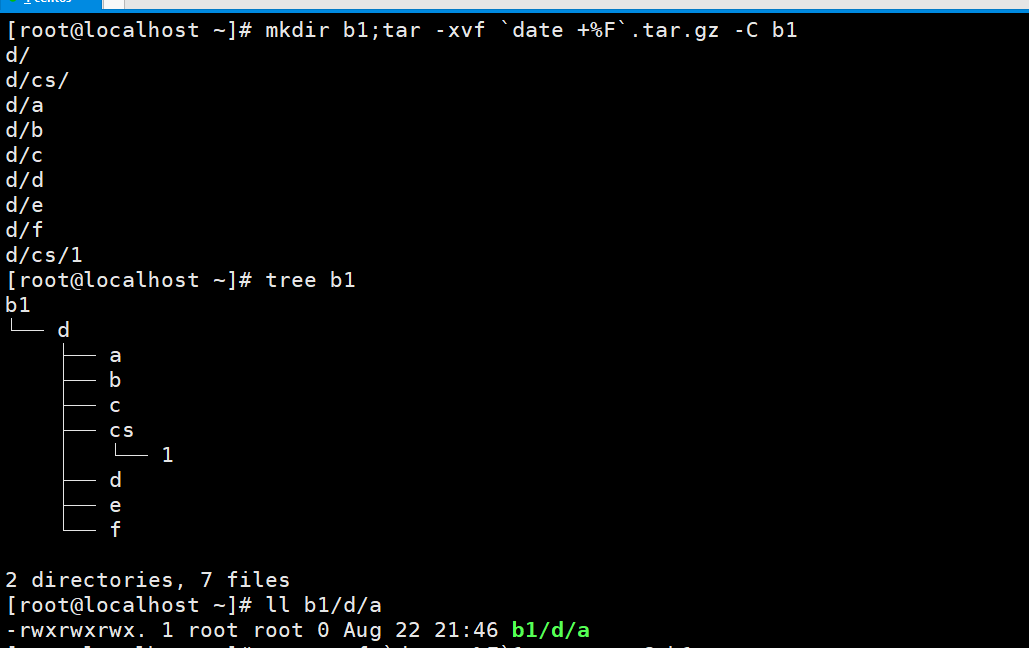
`date +%F`1.tar.gz是个增量包。对比一下前后的b1/d/a的权限。
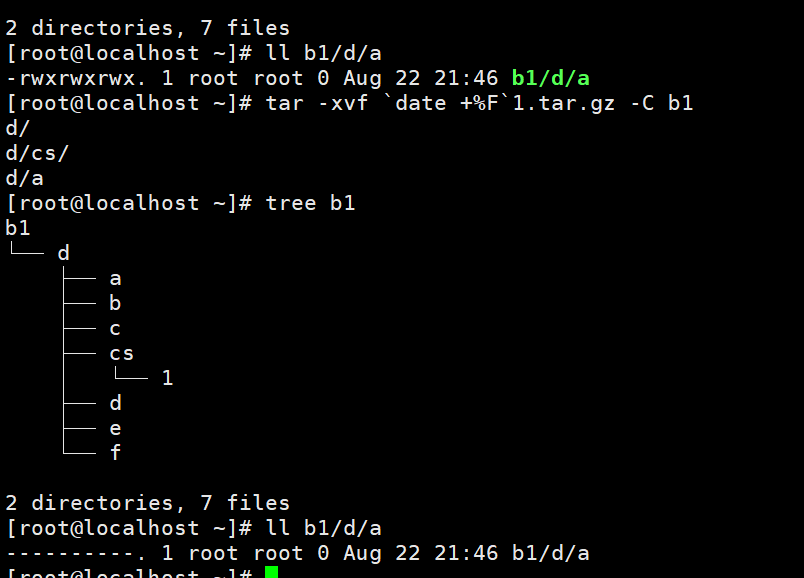
这中间当然我们是少了一步的,就是把打包压缩完之后的包传送到另一台服务器的过程,很多命令都可以实现这种操作,我就说一个linux自动带有的一个scp,它就是一个安全的远程文件拷贝程序。

由于我没办法演示,就先看一看这个命令吧。参考了http://www.runoob.com/linux/linux-comm-scp.html

tar还有一种方式,就是以前提到和find结合。

不过我觉得其实也没什么太大的必要,当然也是一种办法,不过我觉得tar -g就可以,如果tar -g出了问题,我们可以试试这种办法,这里我就不演示了,比较简单。那么下面我们就结合crontab写一个脚本来实现每周日的一点全量备份一次,周一到周六的一点增量备份一次。
以下脚本中没有文件传输的代码,因为缺少演示的条件,决定先不写。我们的脚本名字就叫做backup.sh。内容如下。
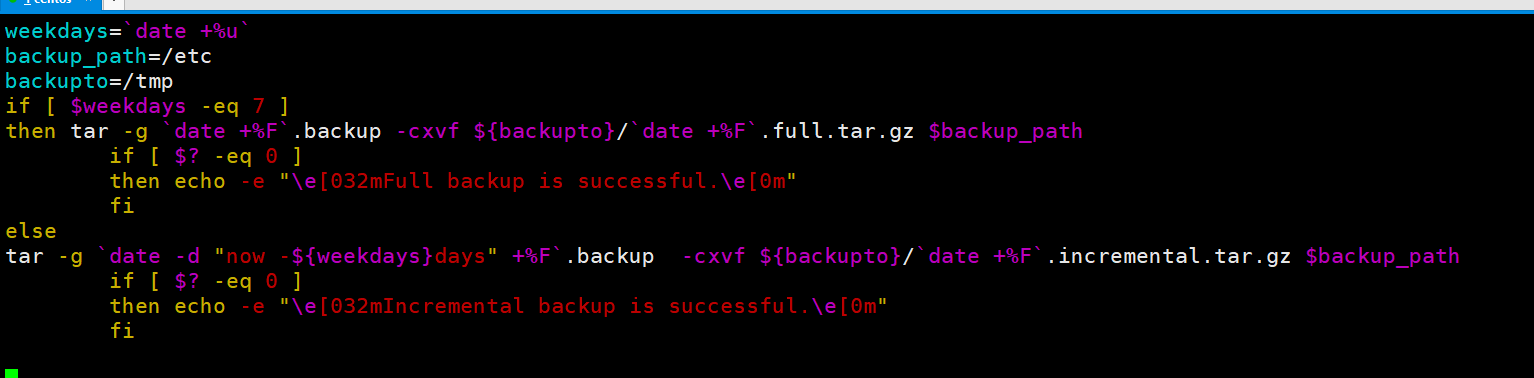
其中有几个点说一下,date +%u打印的是星期几,然后date -d是可以运算的,now-3days就是现在减去三天。那么now-${weekdays}days就是现在减去星期几,也就是上个星期天。


这个string可以是now,上面说的意思是写now就没有什么意思了。
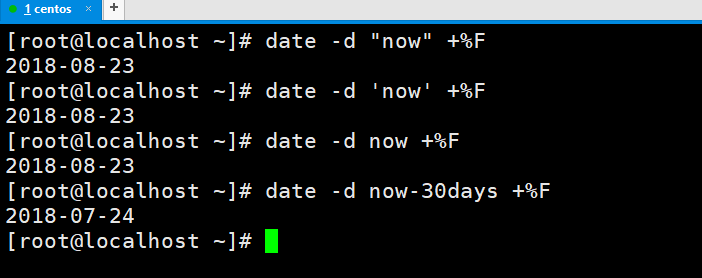
然后我们就可以这么写了。

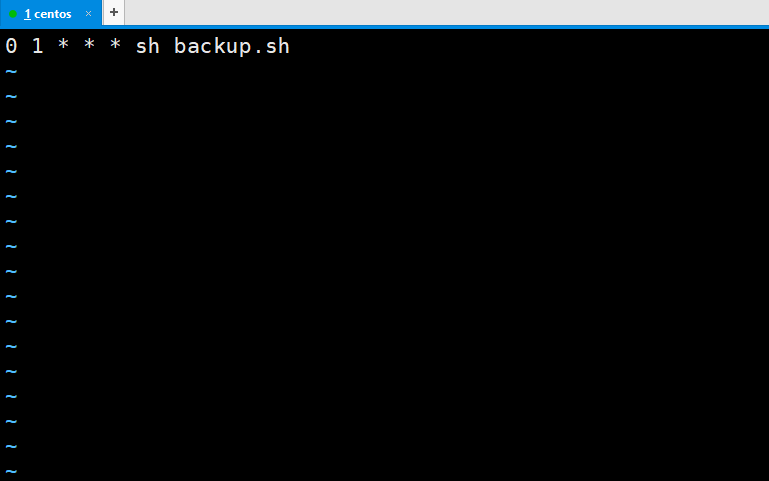
crontab里面的格式如果忘了可以复习一下。

我上面是每天执行一次backup.sh脚本,在脚本里面判断是否是星期天,你也可以分别写全量备份和增量备份的脚本,然后在crontab里面写两行。
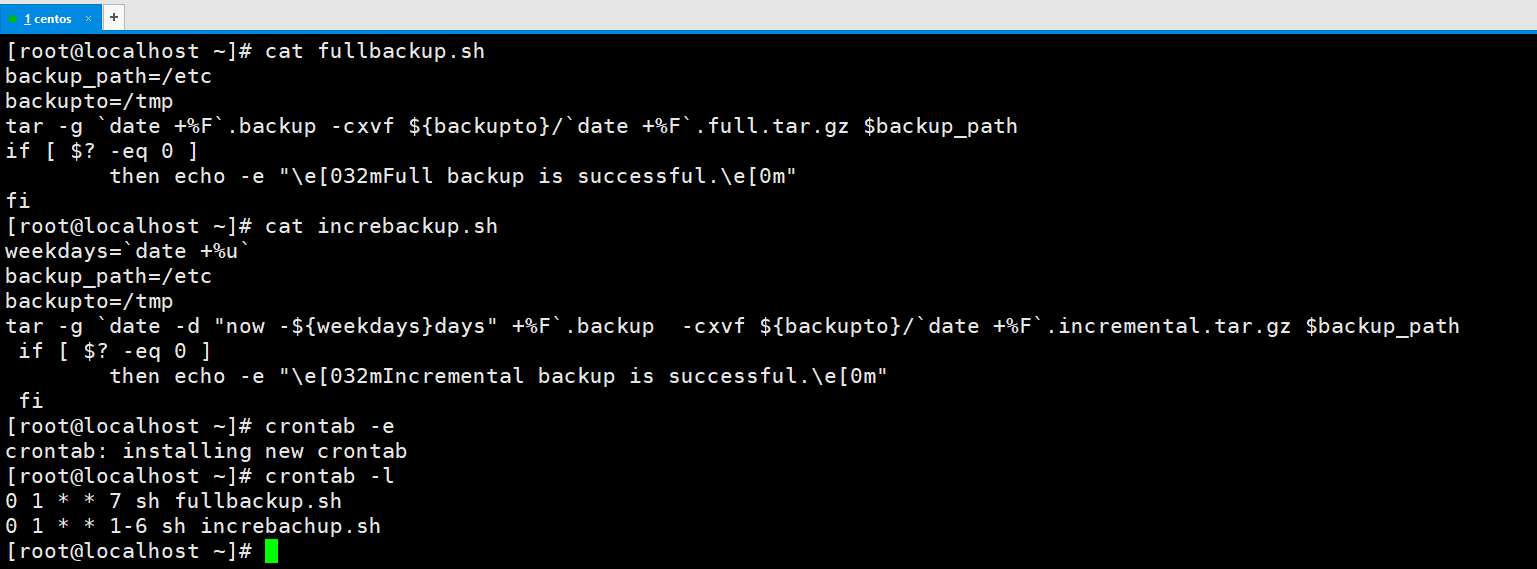
有没有必要加入系统级别的计划任务呢?可以加也可以不加,因为服务器是不关机的,一般用户级别的计划任务就够了。
虽然我没有云主机,但是我们还是可以用两个虚拟机来做测试。一个虚拟机的ip是192.168.214.128,另一个是192.168.214.129,当然这都是内网ip而已,不是公网ip。
首先来测试rsync。PULL是从别的主机上“拉”来文件,PUSH是从这台主机上把文件“推到”别的主机上,还是很形象的。再复习一下格式:
但是还有一个前提,就是接受文件的主机也要安装rsync命令。不然就会出现错误。

看到rsync确实是可以增量备份的。第一次还是相当于全量备份。录gif的时候感觉很卡。

第二次才是增量备份。

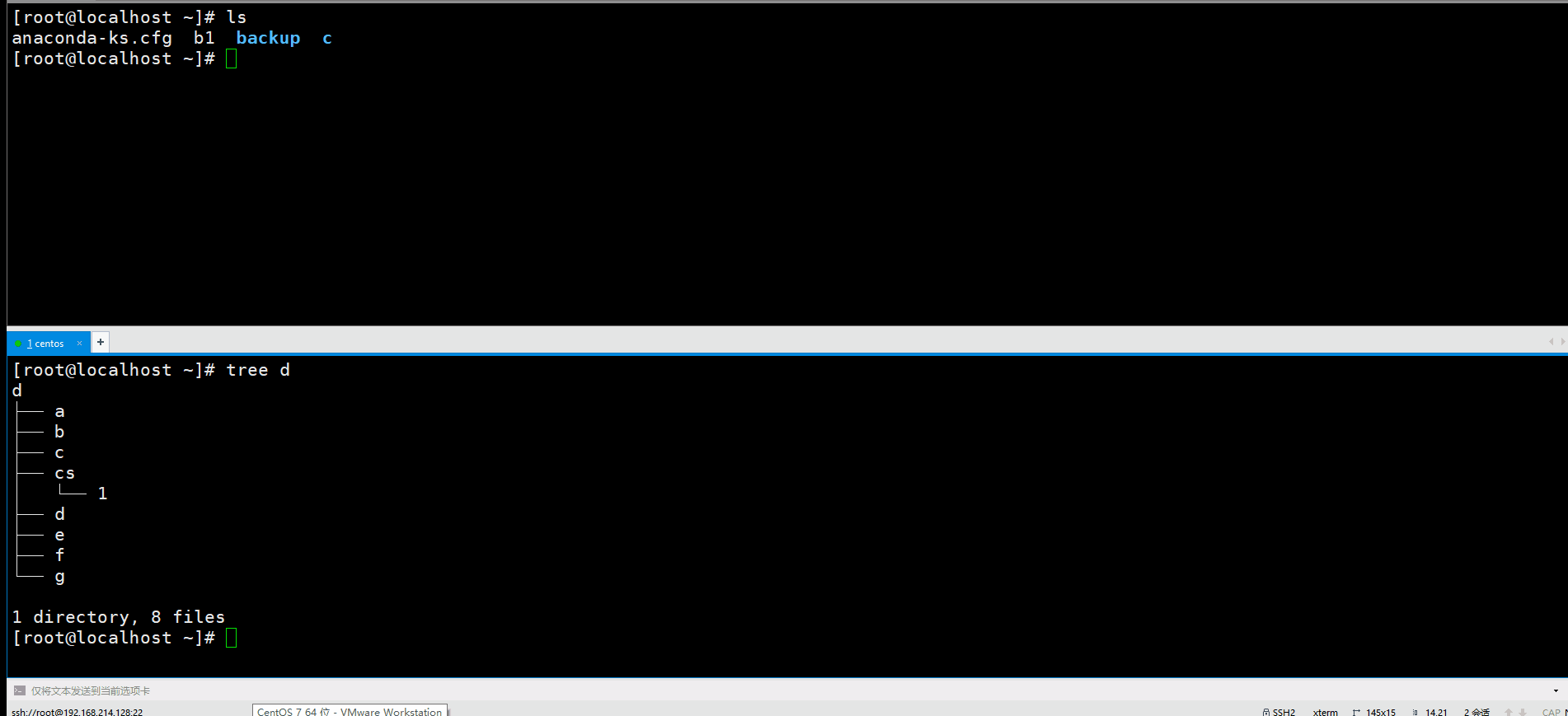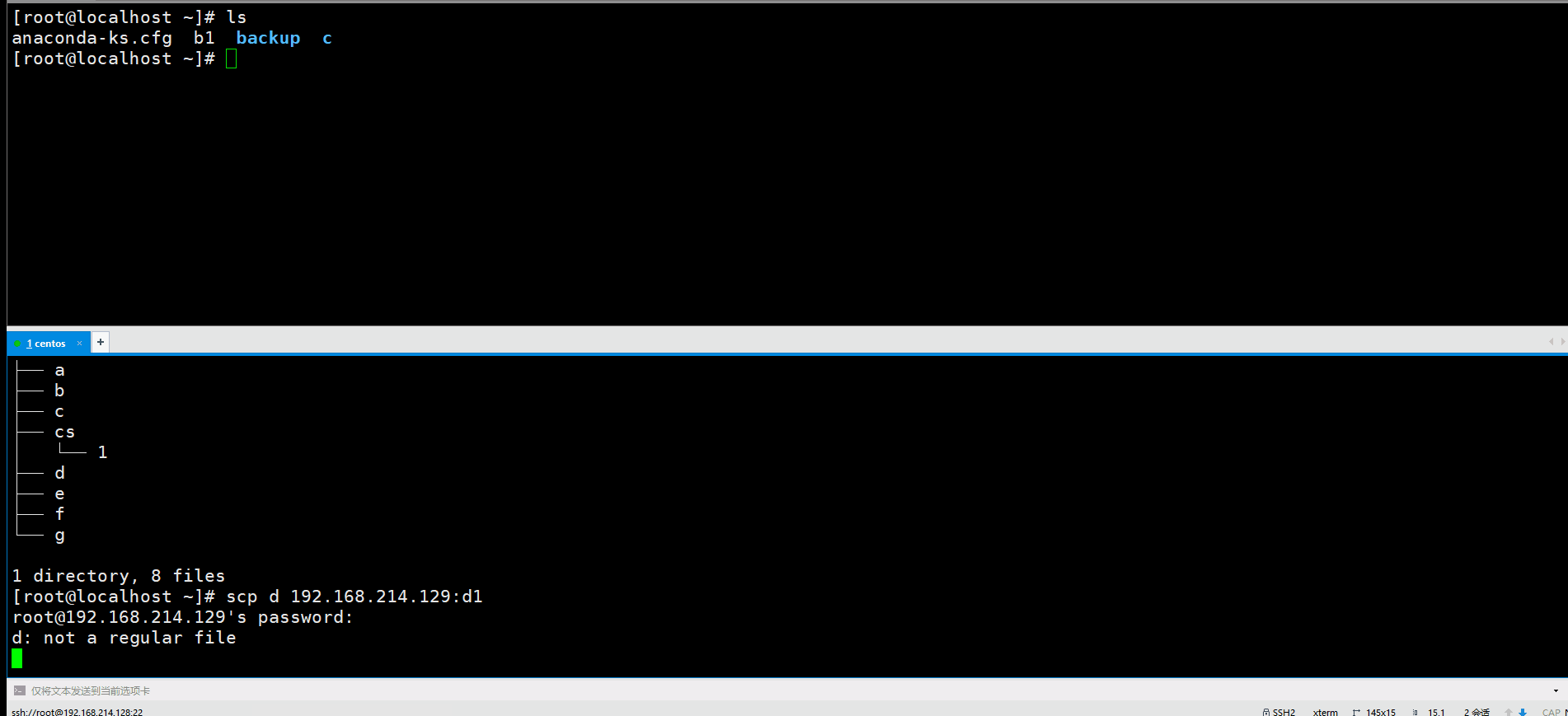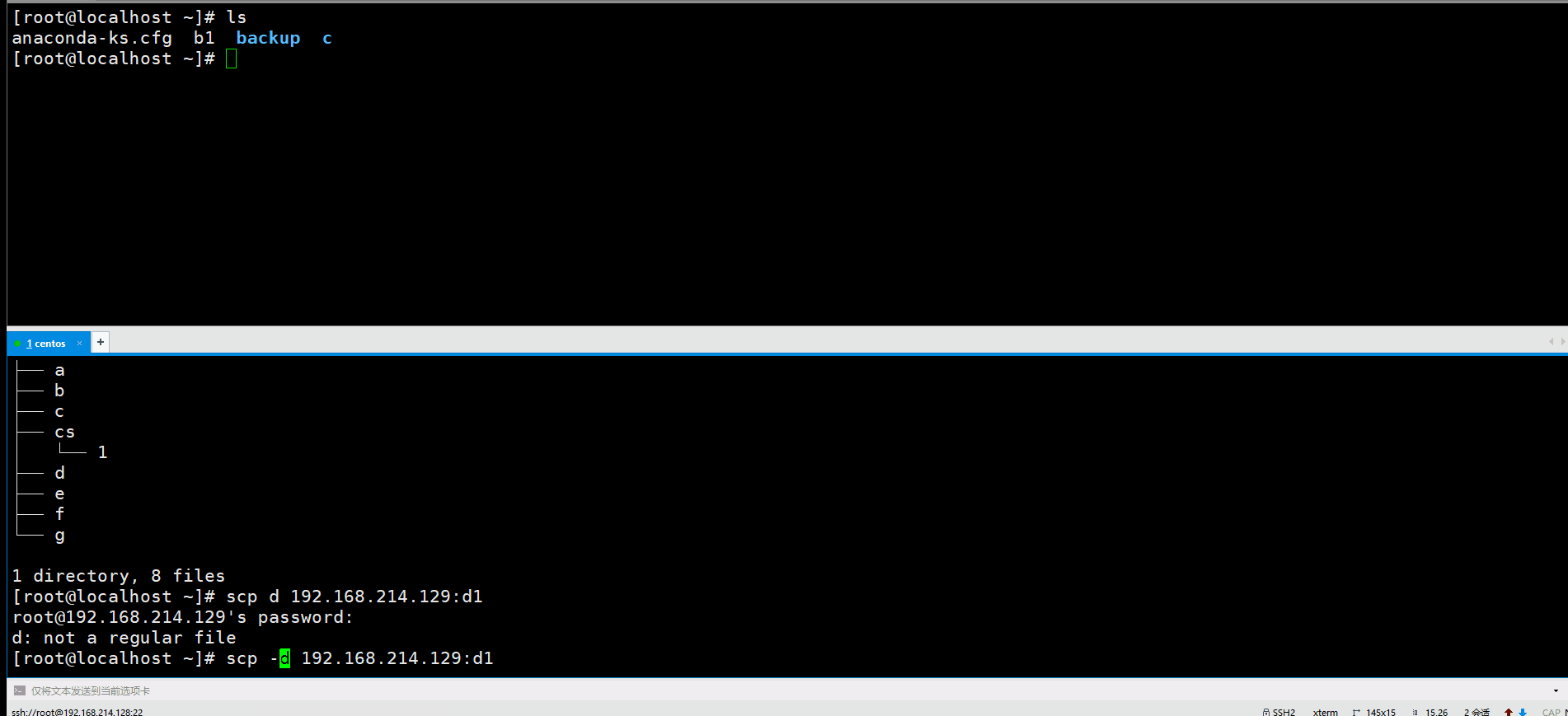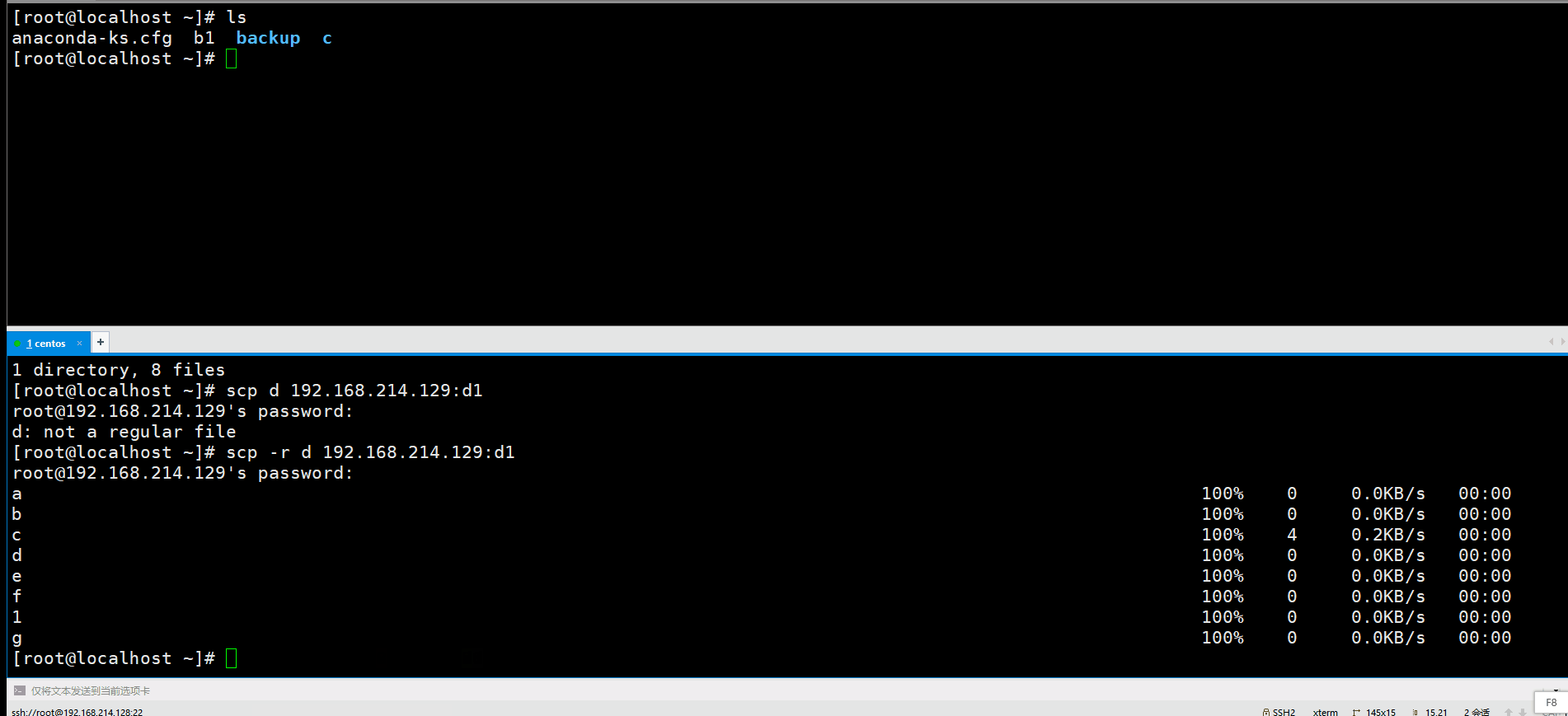
然后是学一个scp。我们tar -g完了以后可以scp过去。
scp最好加上一个-r,也就是递归的意思,如果不加的话,文件夹传不过去,例如我们想传d,就显示了d:not a regular file这样的错误信息,加上-r就可以了。
192.168.214.129确实是收到了。

那么在backup.sh或者fullbackup.sh和increbackup.sh的最后加上scp语句就可以了,整个全量增量备份脚本就实现了。那么如果需要备份到多台服务器呢?其实也比较简单,我们只需要先准备一个存放ip文件,然后去一行一行读取就可以了,至于这存放ip的文件怎么来的,无非是前面的awk,sed等命令把ip提取出来,然后重定向到文件中。下面的例子中,我们直接从ip文件开始。我们的本机是192.168.214.129,然后向其他主机上传。其实就是很简单的一个for循环。

看到第一次是和这个ip的主机通讯的时候是有一大段话的,里面的ECDSA是一种加密算法。SHA256和MD5是不同的加密散列(或者哈希)函数。

问你是不是继续连接,输入yes,然后192.168.214.128就加入到已知主机里面了。然后输入密码就可以传输文件,第一次失败是因为d这个文件夹不存在。d1是存在的。

就传过去了,而后面的两个ip我们是连不上的,当这两个主机不存在或者没有开机的时候就会出现No route to host。重点在于我们掌握这种方法就可以了。
Linux远程操作服务器脚本实现批量操作
有的时候我们就是有需求要在这台服务器上远程操控另一台服务器,其实也很简单。用ssh命令就可以了。
格式就是ssh host command。当然远程服务器必须要是开着的,并且sshd要是启动起来的,不然就会出现No route to host。
我们把192.168.214.128开机了以后,就可以远程操作了。由于sshd是开机自启的,没出现问题,如果有问题,1可能是sshd没有启动,可以systemctl start sshd启动一下,2是防火墙的问题。关于防火墙,下面还有一个例子里会有说到。
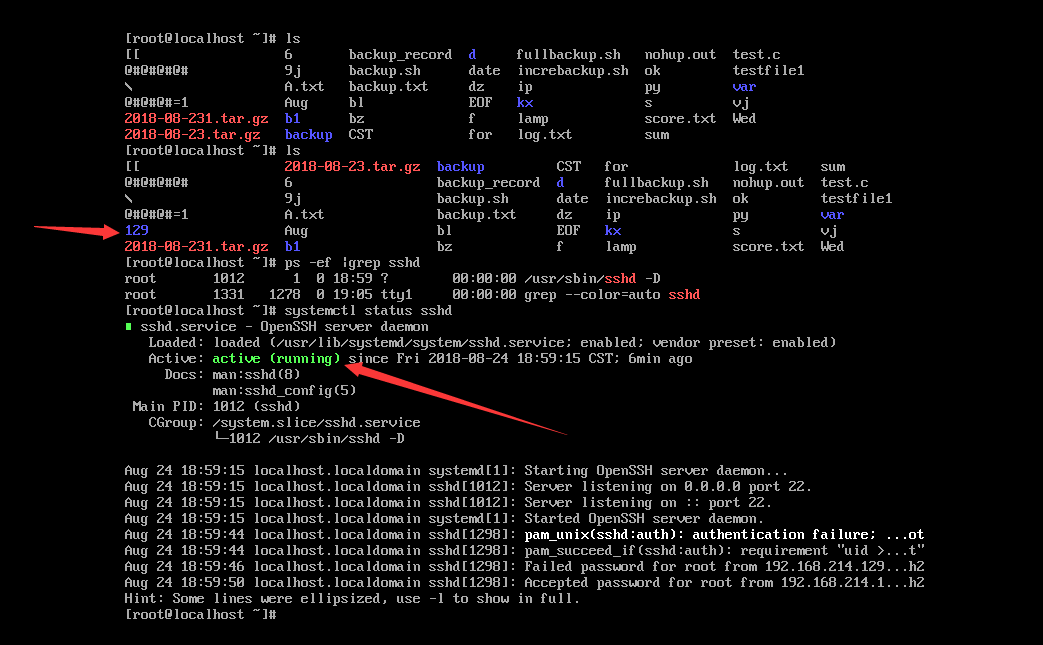
ssh还有一个-l参数,是指定用户登录要用到的。格式是ssh -l user host command

当然其实我们不用-l的。
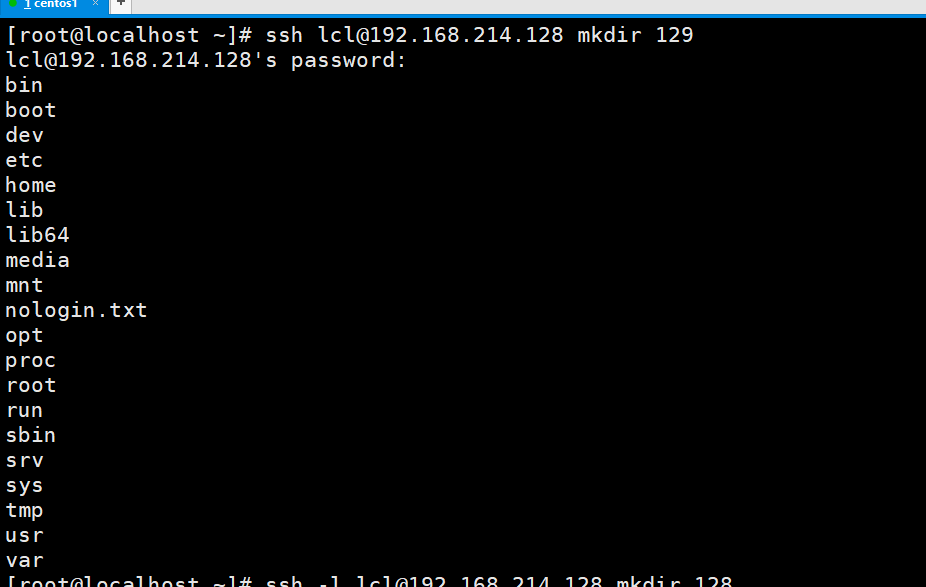
看到另一台服务器上已经是有了129这个目录。
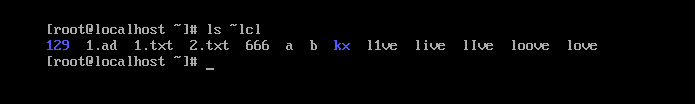
用-l的话。
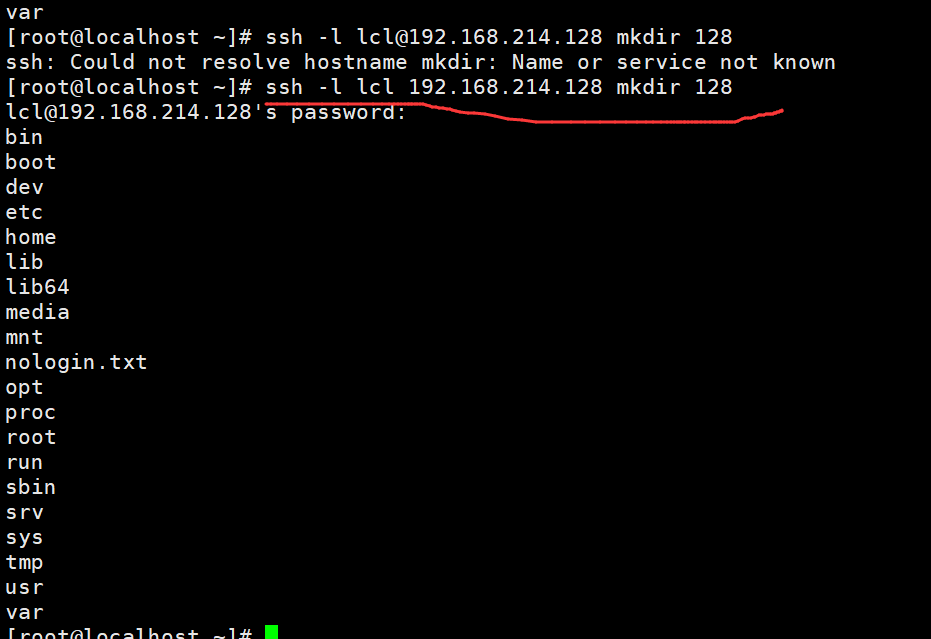
也是可以的,不过注意用-l的格式。
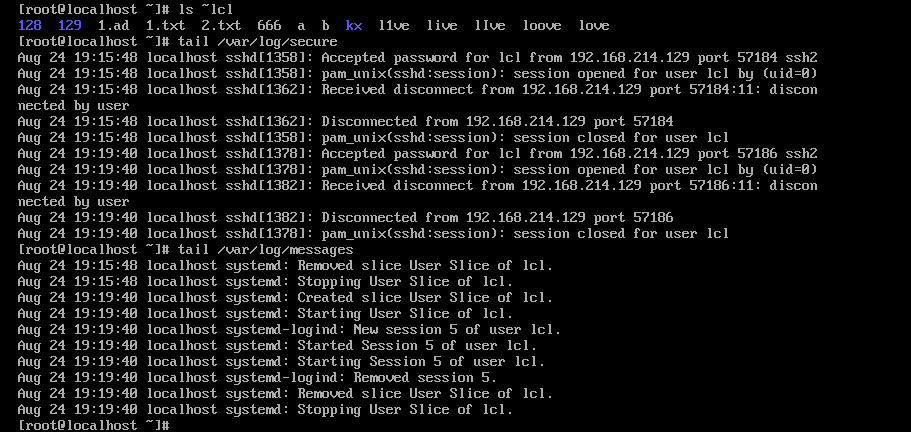
如果-l和@同时用,取的是@前面的,我们看到让输入的是root的密码嘛。

ssh执行命令不会改变ip a的。
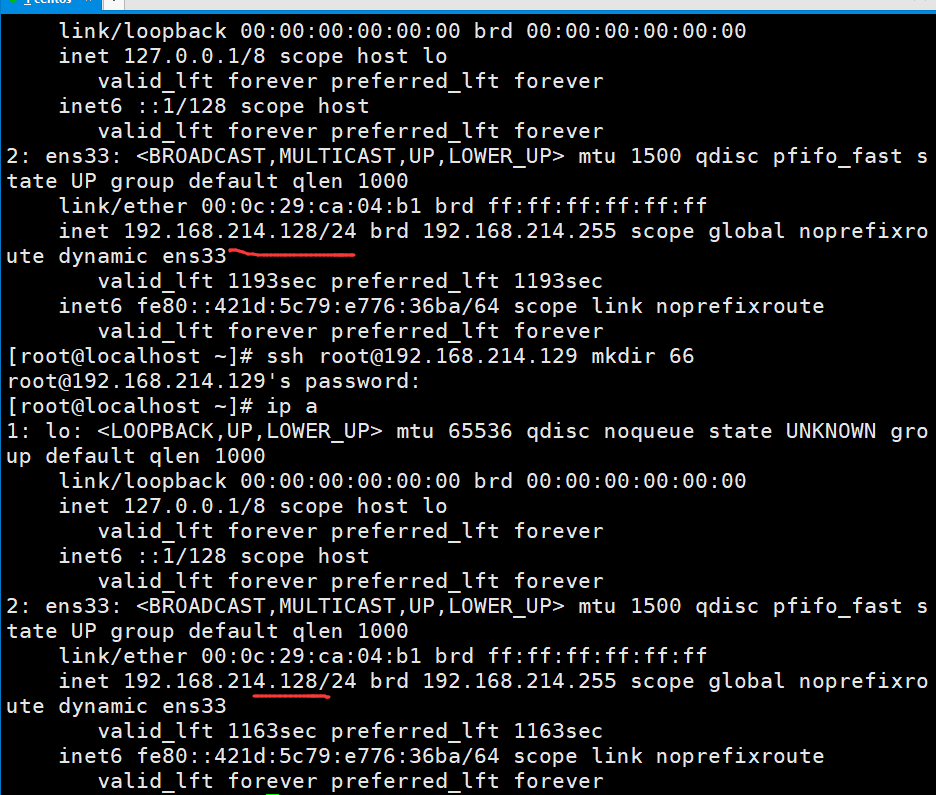
如果不加命令,就会直接进入这个主机的shell。

这有什么用处呢?我们手动写看着作用好像不大,但是试想一个场景,如果要实现批量部署或或者启动某一个软件,我们难道要一个一个服务器去执行命令或者去写脚本吗?那该多麻烦啊。我们要么是写好计划任务的脚本,然后传输到/var/spool/cron/文件夹里面,文件名最好是执行的用户名。或者我们就在一台主机上远程操作一条龙服务。如果ip.list里都需要创建http目录,就可以像下面这么写。
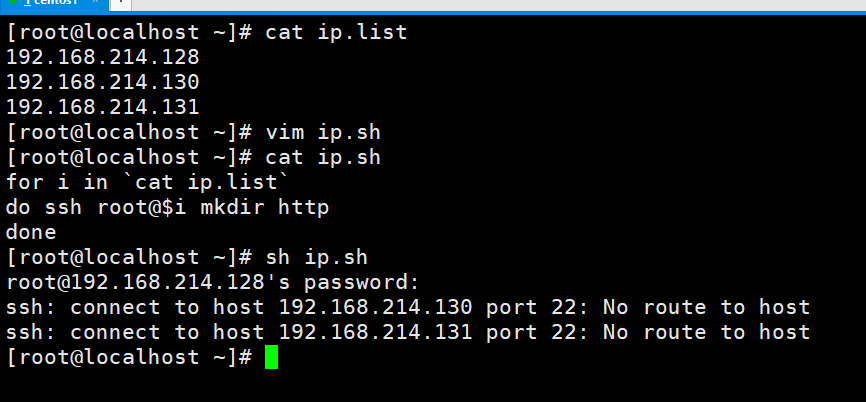

我在老家用的是五年前买的台式机,开两个虚拟机长时间跑还是有点卡的,我就不开三台虚拟机试了。
Linux实现网络监控禁止ip访问脚本
有的时候很多人会恶意攻击你的服务器,那么这个时候我们可以利用脚本自动去禁止这些恶意的ip来访问你的服务器。首先,我们用192.168.214.128多次失败登陆192.168.214.129,然后写脚本自动利用防火墙禁止它访问。
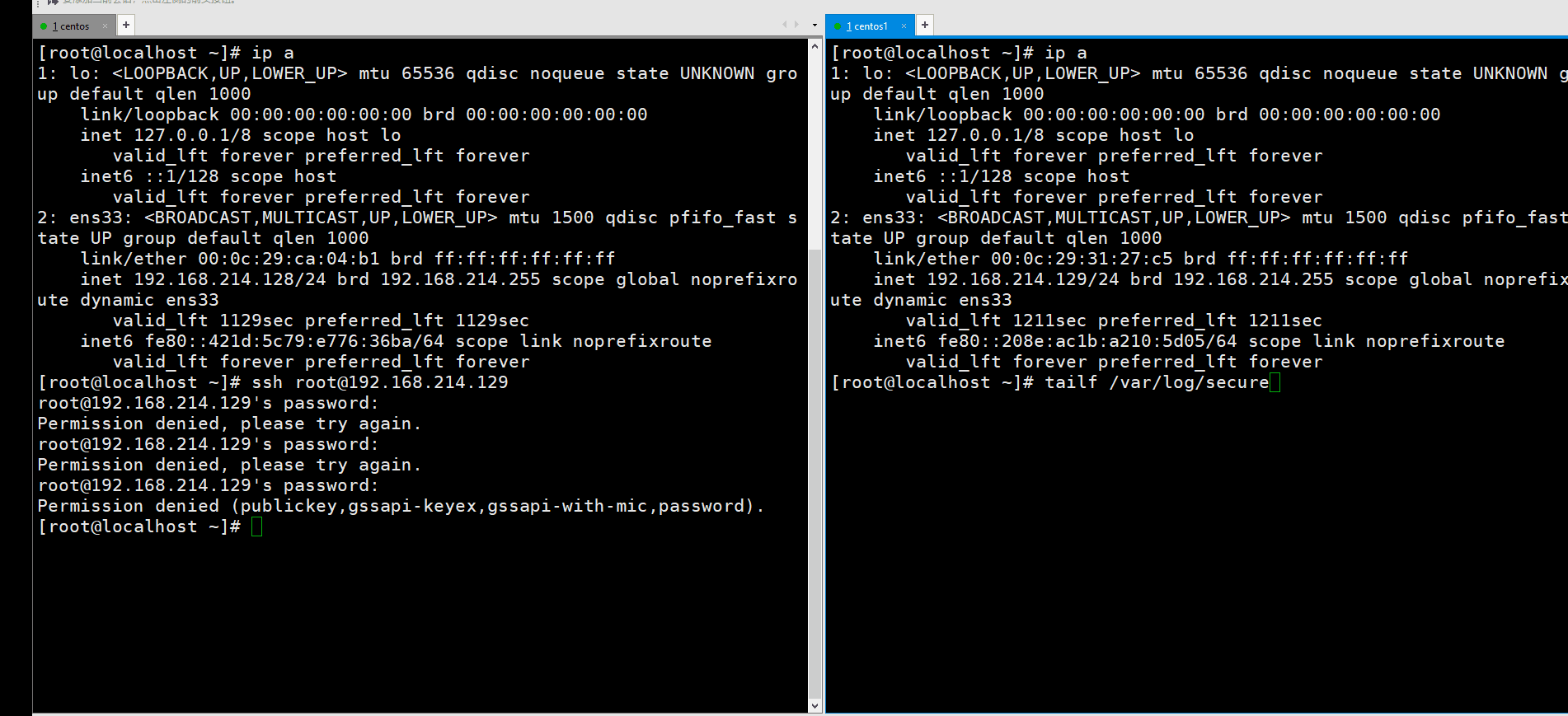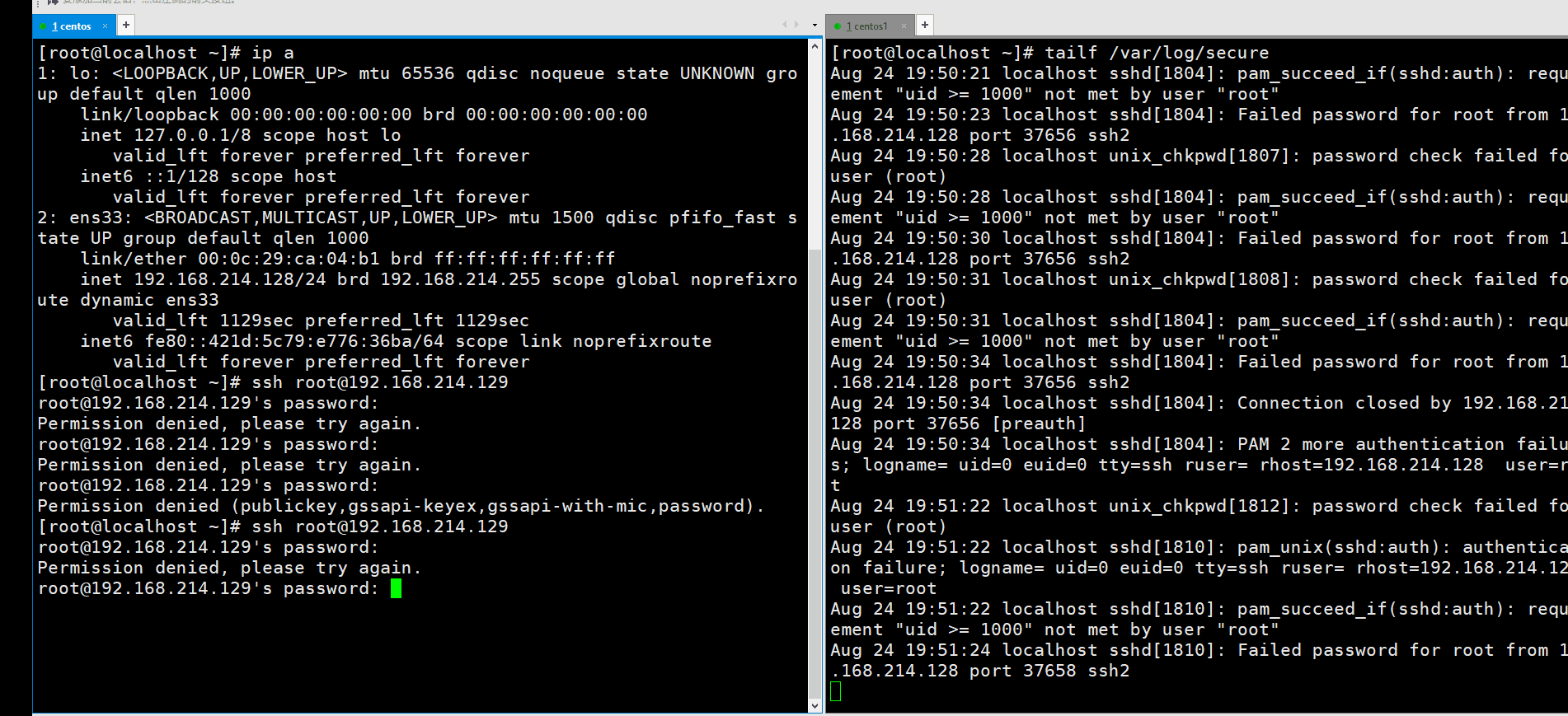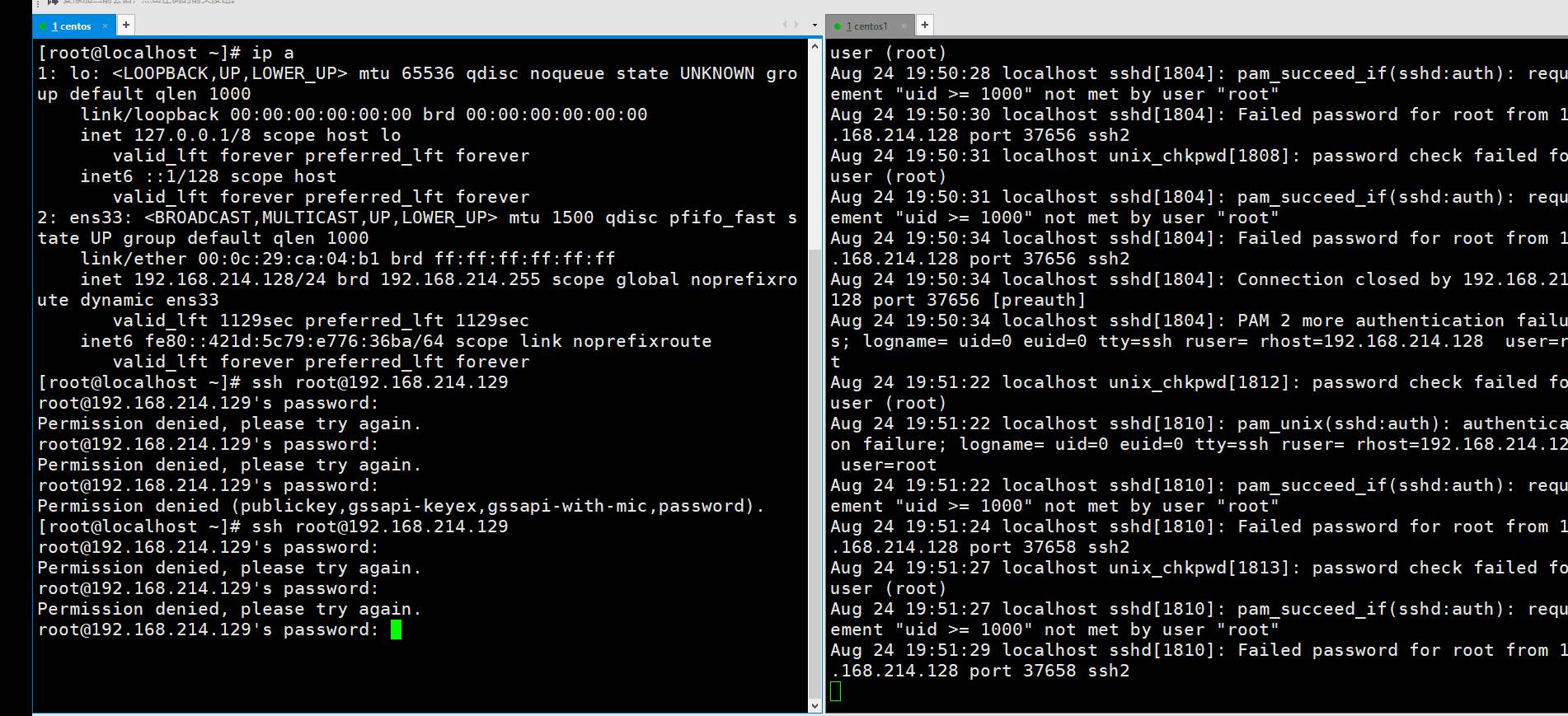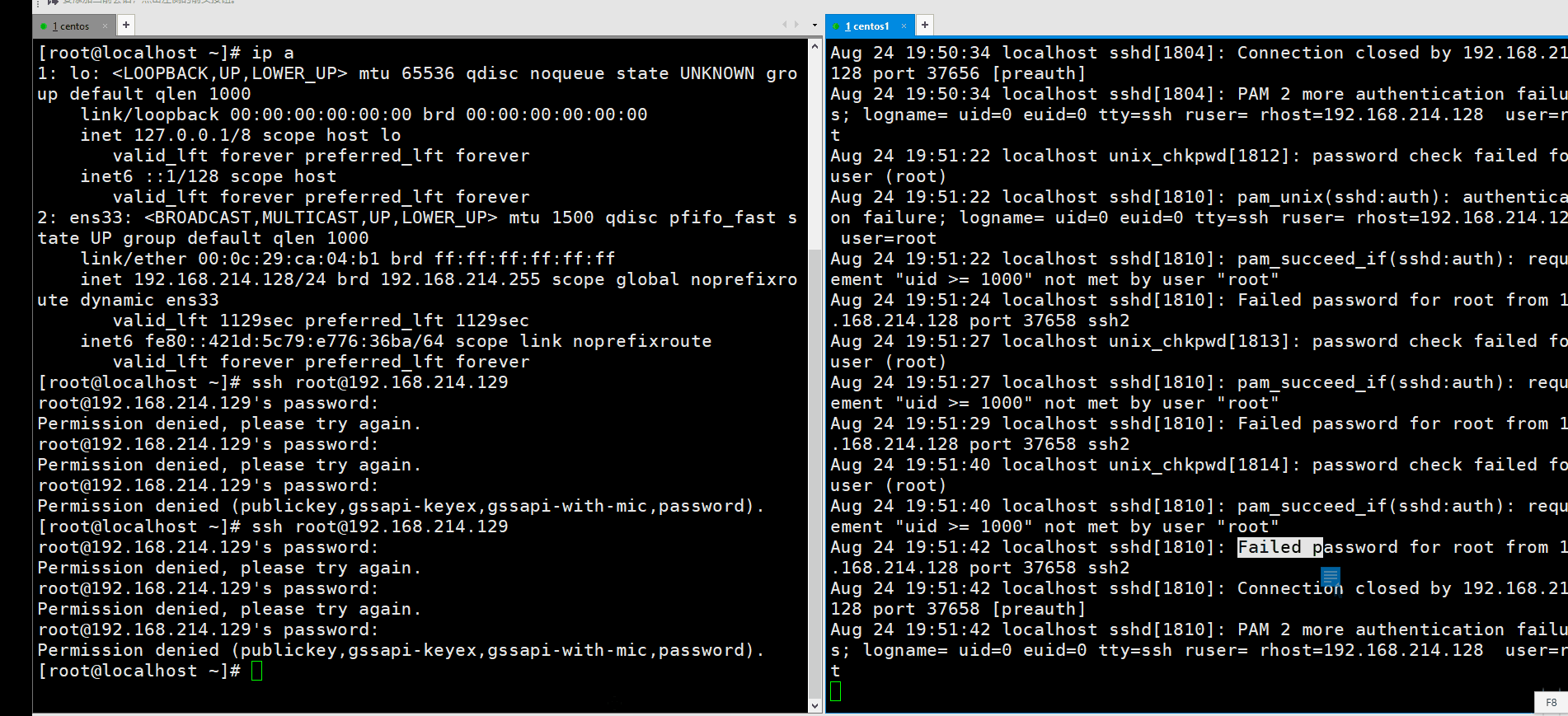
我们可以在计划任务里每个整点去执行一次下面要写的脚本。第一步,首先我们统计出最近登陆失败最多的一次ip,如何统计呢?在日志管理那里我们曾经说过,/var/log/secure里面主要是记录和认证登陆有关的日志。
看到失败的ip可以用awk来提取,是在第11列。我们可以像下面这样来统计。先过滤一下Failed,然后打印ip。
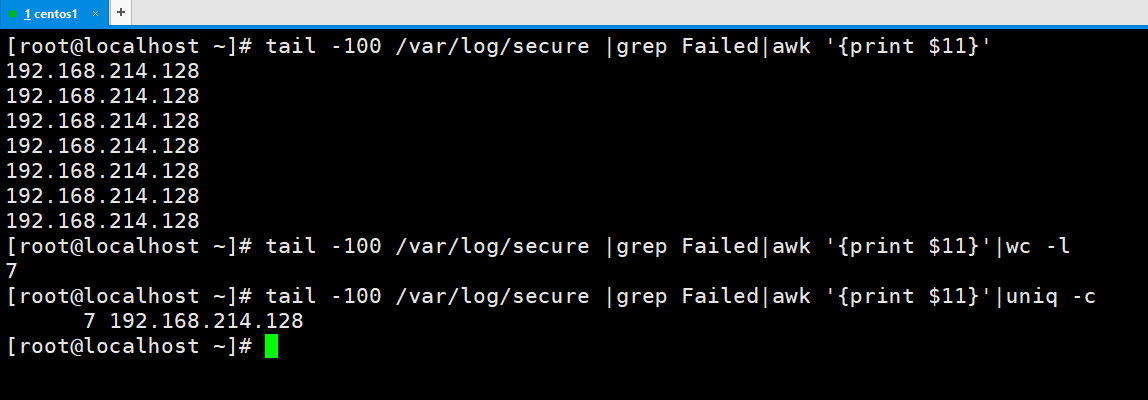
当然在生产环境中不可能只有一个ip,这个其实以前我们有讲过,可以结合sort -nr和uniq -c来处理,sort是排序-n是按照数值排序,-r是按照降序,uniq是合并相同的行,-c是打印次数。这个我以前是讲过的,需要注意的是uniq -c前需要uniq一下,这是因为uniq不能合并不相邻的行。所以需要先sort一下。

上面其实我主要是想说一个wc,这个以前也提到过。它可以打印字节数,字数和行数。-c是打印字节,-w打印字数,一般来说一个字就是两个字节,所以字数等于字节数除以2。-l打印行数。

有了ip和次数,我们怎么禁止这个ip访问呢?这个时候就需要用到防火墙。下面参考了
https://www.linuxidc.com/Linux/2017-01/140073.htm
或者https://www.linuxidc.com/Linux/2012-08/67952p3.htm
以下内容也不必太深究了,我们只要还是要会应用。



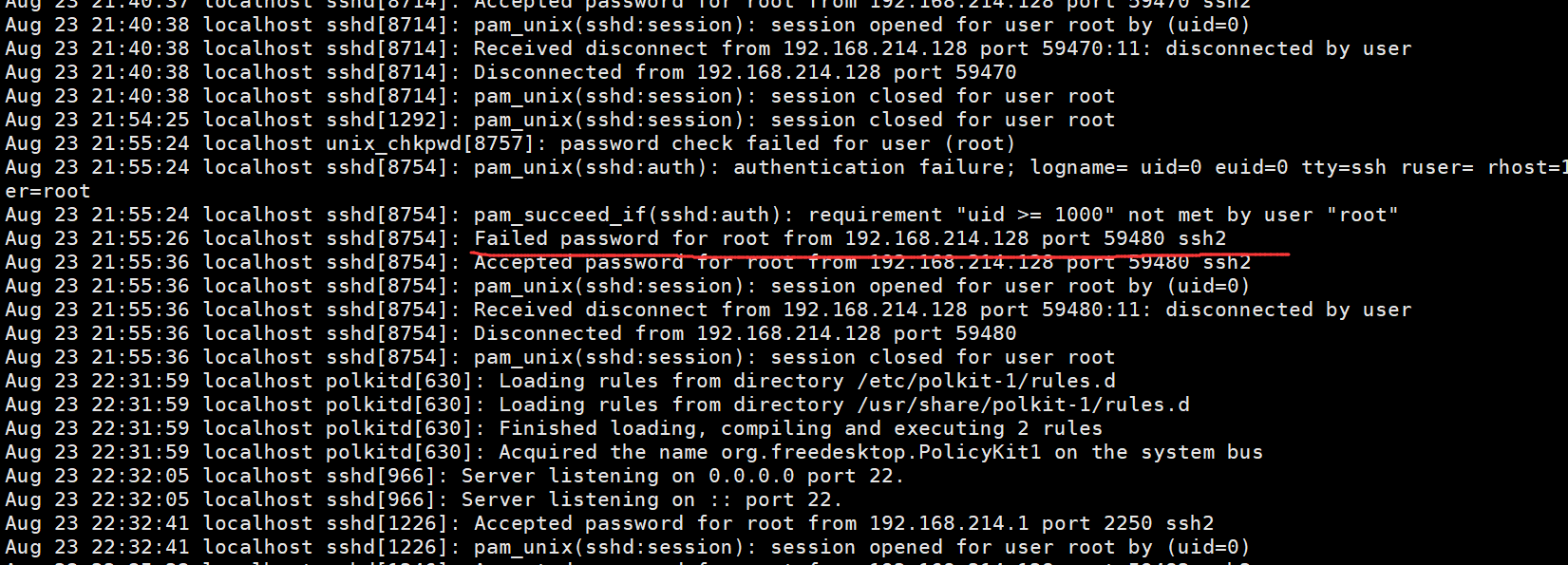
画红线的注意的内容需要重点关注一下。




-p其实可以不要的,下面在演示的时候就没有用到。

我们就只需要看到这里,我们的目的已经可以达到了(当然其实整篇文章已经快完了,我们就不看下面的链接了),你如果想要深入,可以去上面留的网站看一看,我本身不是一个浅尝辄止的人,不过身为一个自动化的学生,我还有别的任务要完成,浅尝辄止不可取,但是捡了芝麻丢了西瓜也不可取,还是要分清主次。iptables生效的前提是要关掉firewalld防火墙,并且只有在防火墙关闭以后,iptables的设置才会生效。
看到DROP就是半天不反应。
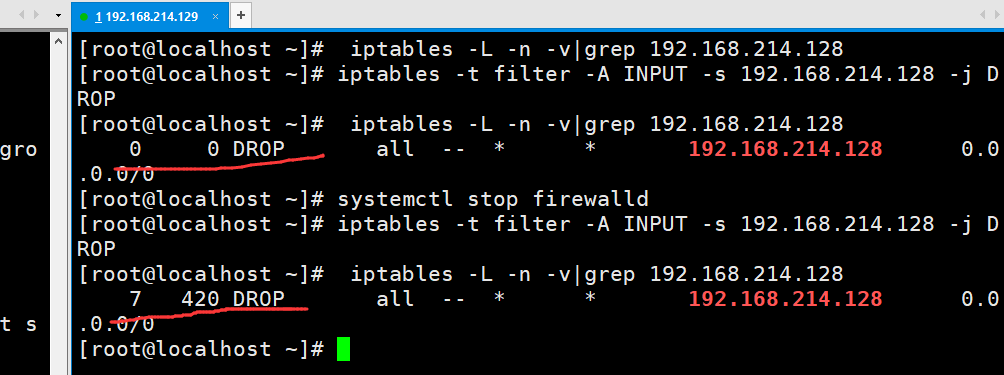
看到在防火墙关闭以后,我们再设置一边后,iptables -L -n -v过滤一下192.168.214.
128.,也只有一条,说明firewalld开启的时候根本就没有设置成功。那么我们再试一试REJECT。
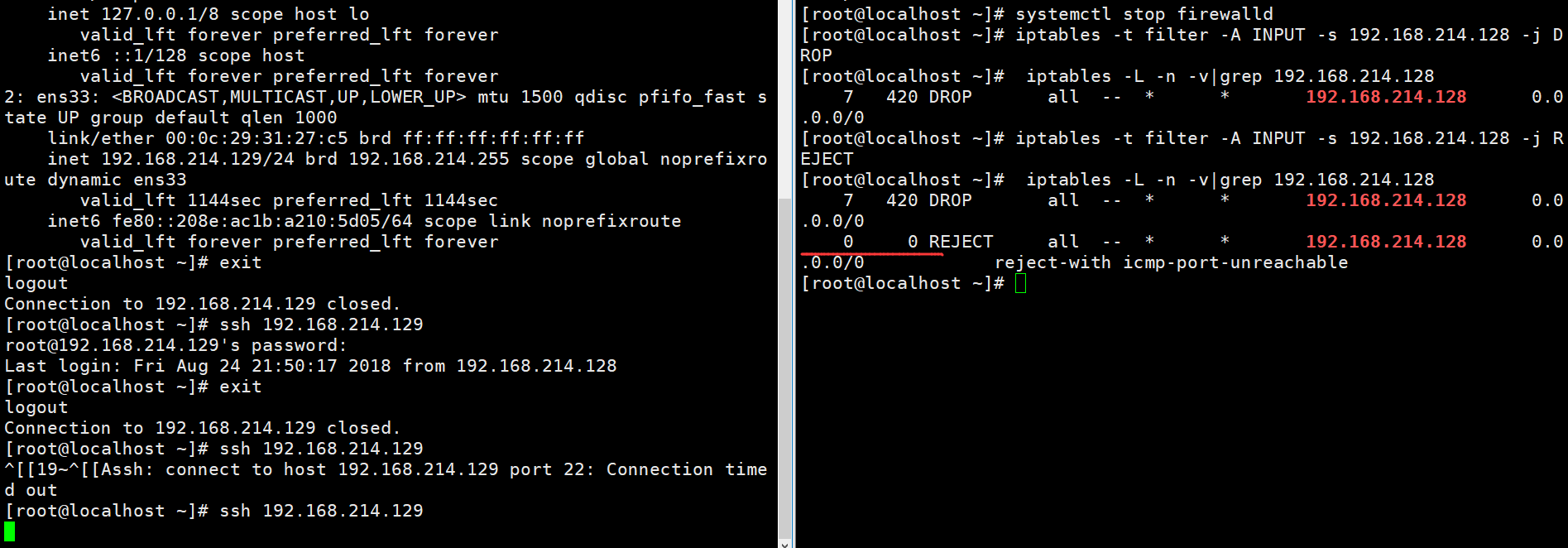
为什么还是没变化啊,还记得上面红线的吗?越严格的要在最上面,REJECT是比DROP严格的。那么我们-D删除一下DROP。

就发现很明确的拒绝了,refused。再加一个-A DROP呢?

发现还是拒绝,因为REJECT比DROP严格,并且是在DROP的上面的,所以是这样。我猜想原理可能是iptables对于每一层(比如说INPUT)只采用最上面的规则,下面的规则会被舍弃.或者说忽略。如果我们启动了firewalld,iptables又不管用了。
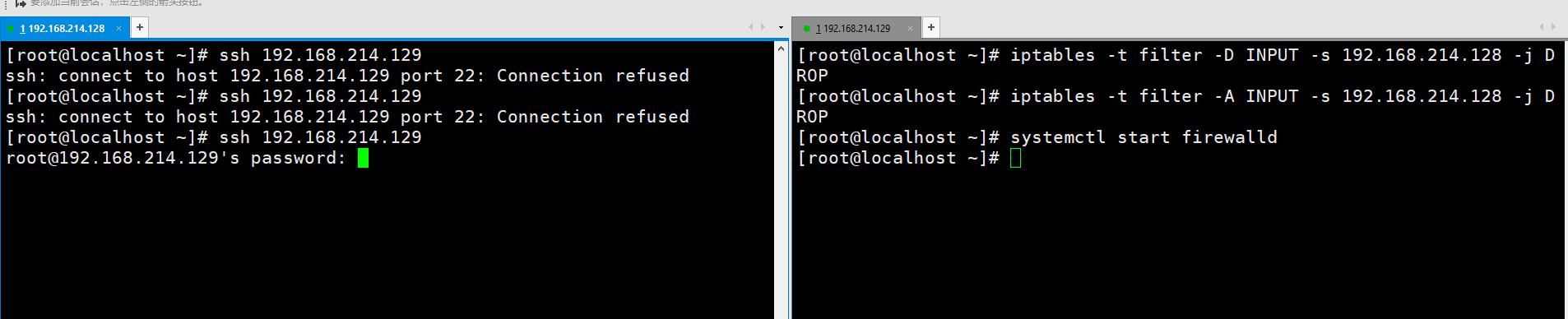
如果又停掉firewalld,原来的规则还会管用吗?不会,说明这种是一次性的。

那么有没有配置文件呢?还真的没有,我试了很多方法,网上说配置文件在/etc/sysconfig/iptables,不过我找不到

,结果发现,我们需要安装iptables-services,这个文件才有。
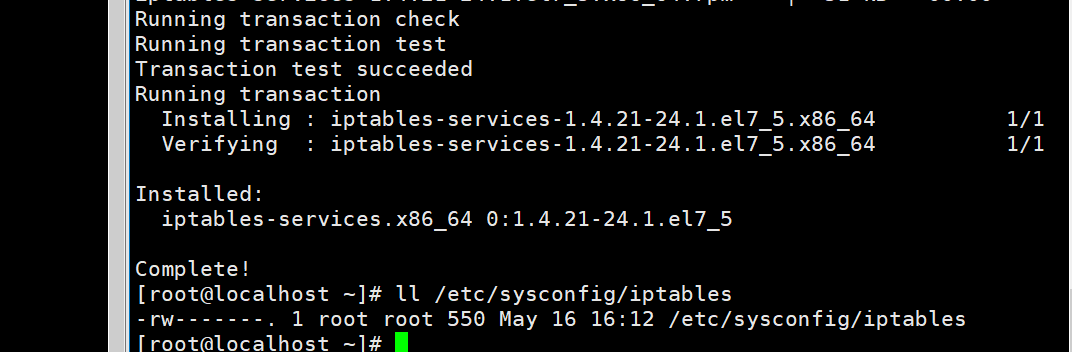
原本是这样的。

我们再设置一下,发现配置文件的内容没有变化。

我们需要运行一条service save iptables。然后会发现里面的内容变了。
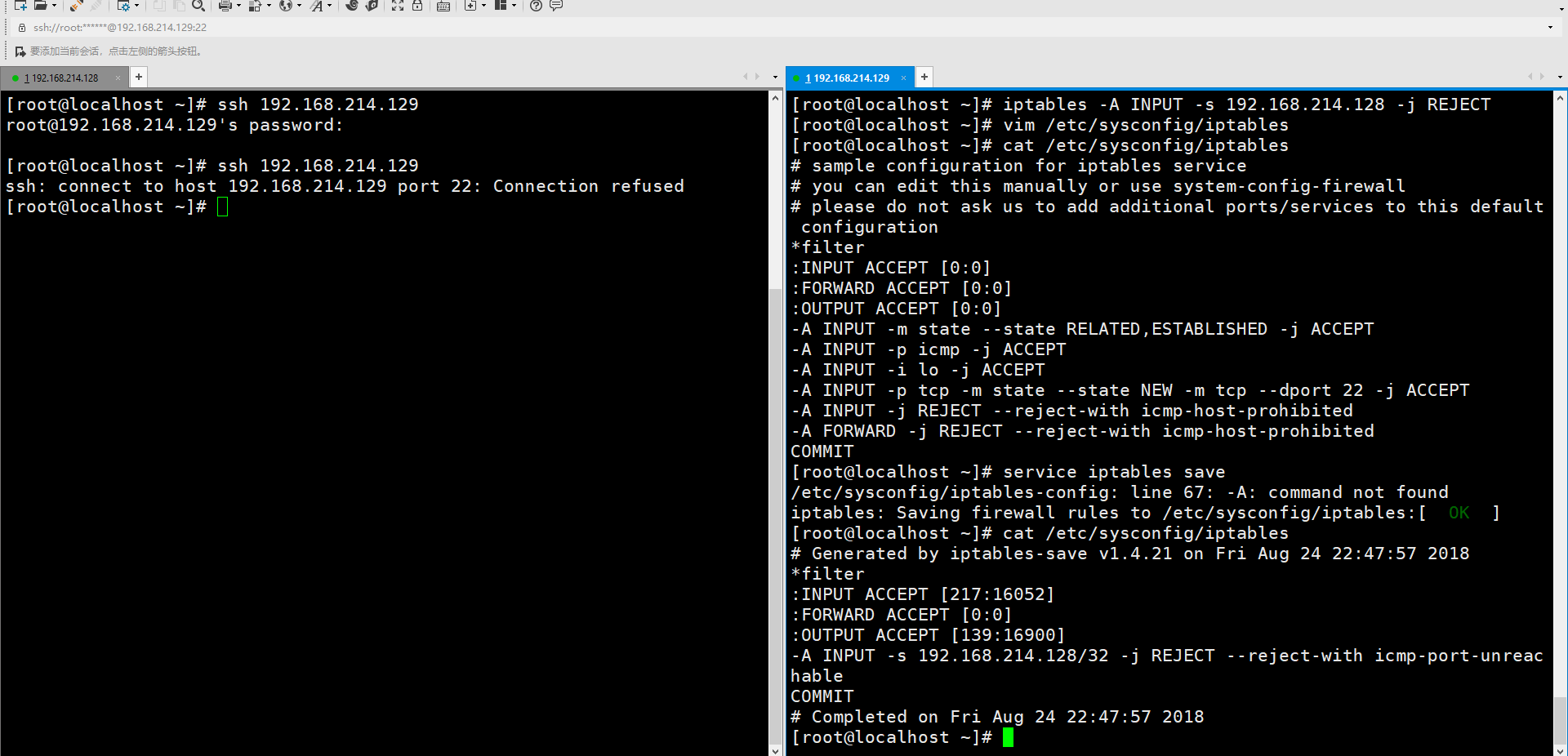
但是我们开关一下firewalld,还是老样子。
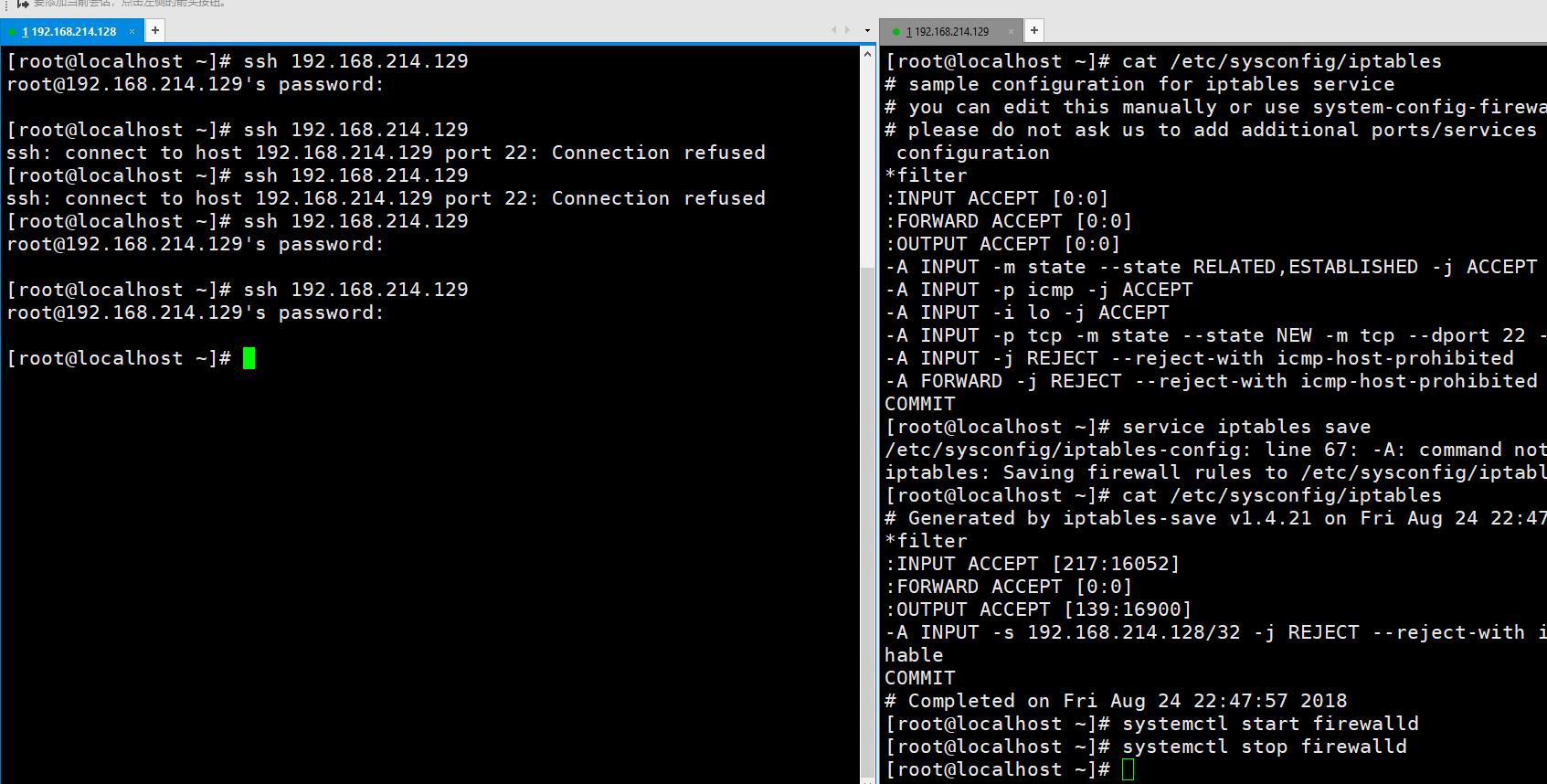
这是因为我们没有重启iptables,那么配置文件就没有被重新加载。重启一下iptables就好了。

当然也可以直接在/etc/sysconfig/iptables里面改内容,然后保存,重新加载iptables。你们可以试一试。综合上面的我们可以写一个脚本,如果失败的次数超过3,那么就禁止访问。我现在先把iptables的配置文件还原了,先iptables -D 192.168.214.128 -j REJECT,然后service iptables save一下就还原了。那么下面我们就看一下脚本怎么写。这个脚本叫做fip.sh。
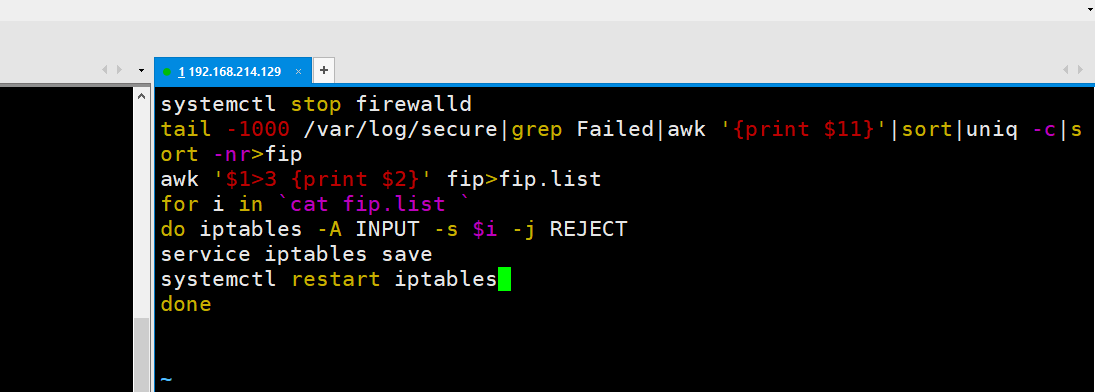
脚本运行良好。
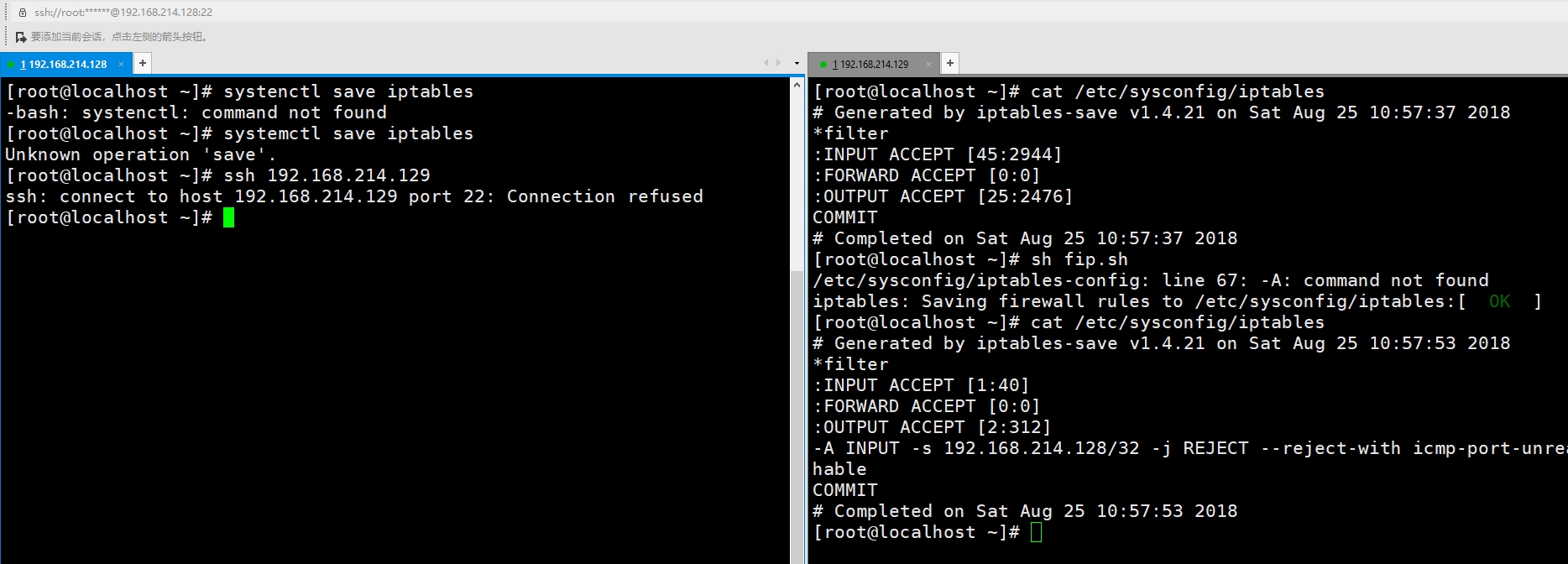
我们重新开关一次firewalld,发现又不行了。
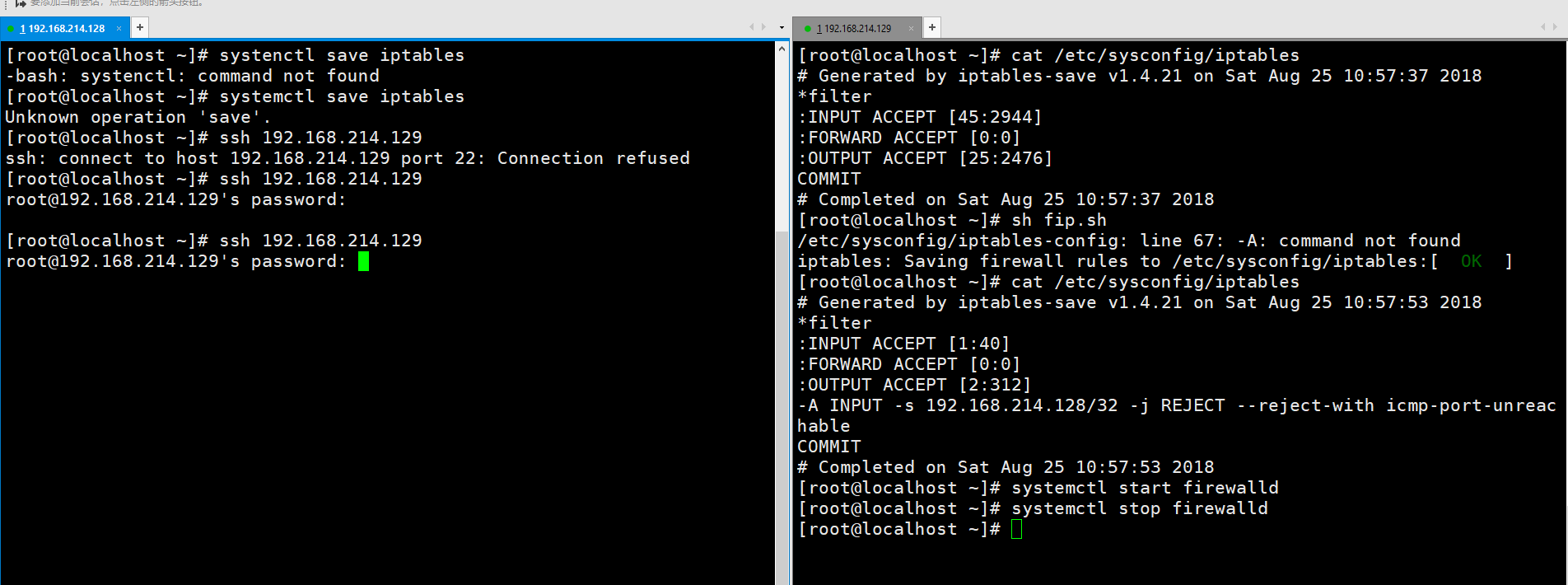
这是因为还需要重启一次iptables。

这一讲先到这里,不过我们的例子还没有讲完。