1)GAN数学角度分:https://zhuanlan.zhihu.com/p/27912062
2)DCGAN篇:
DCGAN论文笔记+源码分析:http://lib.csdn.net/article/aimachinelearning/59228?knId=1731
源码地址:DCGAN in TensorFlow
DCGAN 原文译文:https://ask.julyedu.com/question/7681
DCGAN论文解析笔记:https://blog.csdn.net/stdcoutzyx/article/details/53872121(在该博客中讲解了原文中隐空间的特征表示能力)
注:要知道自从2014年Ian Goodfellow提出以来,GAN就存在着训练困难、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。从那时起,很多论文都在尝试解决,但是效果不尽人意,比如最有名的一个改进DCGAN依靠的是对判别器和生成器的架构进行实验枚举,最终找到一组比较好的网络架构设置,但是实际上是治标不治本,没有彻底解决问题。
3)LSGAN(最小二乘GAN)篇:
LSGAN解析:https://zhuanlan.zhihu.com/p/25768099
4)WGAN篇:
令人拍案叫绝的WGAN:https://zhuanlan.zhihu.com/p/25071913
注:针对于DCGAN的治标能不治本而言,Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
- 基本解决了collapse mode的问题,确保了生成样本的多样性
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高(如题图所示)
- 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到

WGAN前作分析了Ian Goodfellow提出的原始GAN两种形式各自的问题,第一种形式等价在最优判别器下等价于最小化生成分布与真实分布之间的JS散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及JS散度的突变特性,使得生成器面临梯度消失的问题;第二种形式在最优判别器下等价于既要最小化生成分布与真实分布直接的KL散度,又要最大化其JS散度,相互矛盾,导致梯度不稳定,而且KL散度的不对称性使得生成器宁可丧失多样性也不愿丧失准确性,导致collapse mode现象。
WGAN前作针对分布重叠问题提出了一个过渡解决方案,通过对生成样本和真实样本加噪声使得两个分布产生重叠,理论上可以解决训练不稳定的问题,可以放心训练判别器到接近最优,但是未能提供一个指示训练进程的可靠指标,也未做实验验证。
WGAN本作引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题。接着通过数学变换将Wasserstein距离写成可求解的形式,利用一个参数数值范围受限的判别器神经网络来最大化这个形式,就可以近似Wasserstein距离。在此近似最优判别器下优化生成器使得Wasserstein距离缩小,就能有效拉近生成分布与真实分布。WGAN既解决了训练不稳定的问题,也提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。作者对WGAN进行了实验验证。
以上简称《Wassertein GAN》为“WGAN本作”,简称《Towards Principled Methods for Training Generative Adversarial Networks》为“WGAN前作”。
WGAN源码实现:martinarjovsky/WassersteinGAN
5)LS-GAN(loss-sensitive GAN)篇:
条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上:https://zhuanlan.zhihu.com/p/25204020
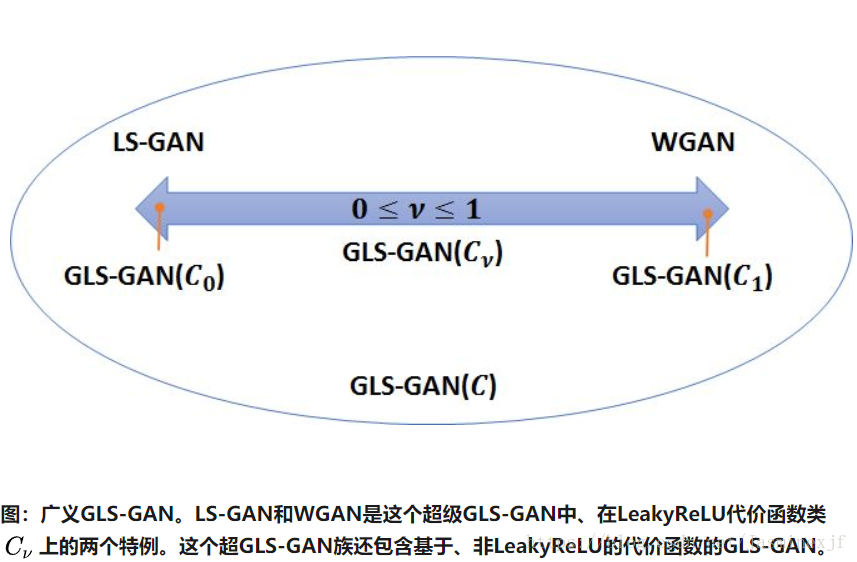
广义LS-GAN(GLS-GAN):现在是LS-GAN和WGAN斗志这个超模的特例:https://zhuanlan.zhihu.com/p/25580027
LS-GAN博客解析:https://blog.csdn.net/qq_31780525/article/details/71854186
在最后一篇博客中,给出如下参考:
代码
1. LS-GAN: https://github.com/guojunq/lsgan
2. GLS-GAN: https://github.com/guojunq/glsgan
参考文献
1. Qi G J. Loss-Sensitive GenerativeAdversarial Networks on Lipschitz Densities[J]. arXiv preprintarXiv:1701.06264, 2017.
2. 知乎专栏:条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上 - 知乎专栏
3. An Incomplete Map of the GAN models: http://www.cs.ucf.edu/~gqi/GANs.htm
4.f-GAN:Training generative neural samplers using variational divergence minimization[C]//Advances in Neural Information Processing Systems. 2016:271-279.
到目前为止,讲解了GAN;DCGAN;LSGAN;WGAN;LS-GAN
那么究竟GAN,WGAN和LS-GAN谁更好呢?
持平而论,笔者认为是各有千秋。究竟谁更好,还是要在不同问题上具体分析。
这三种方法只是提供了一个大体的框架,对于不同的具体研究对象(图像、视频、文本等)、数据类型(连续、离散)、结构(序列、矩阵、张量),应用这些框架,对具体问题可以做出很多不同的新模型。
当然,在具体实现时,也有非常多的要考虑的细节,这些对不同方法的效果都会起到很大的影响。毕竟,细节是魔鬼!
笔者在实现LS-GAN也很多的具体细致的问题要克服。一直到现在,我们还在不断持续的完善相关代码。
对LS-GAN有兴趣的读者,可以参看我们分享的代码,并提出改进的建议
6)WGAN-GP(WGAN with gradient penalty)篇
https://www.jianshu.com/p/12bbf08363cd
本论文在github上开源了代码:github
注1:生成对抗网络(GAN)是一种强大的生成模型,但是自从2014年Ian Goodfellow提出以来,GAN就存在训练不稳定的问题。后来提出的 Wasserstein GAN(WGAN)在训练稳定性上有极大的进步,但是在某些设定下仍存在生成低质量的样本,或者不能收敛等问题。
随后蒙特利尔大学的研究者们在WGAN的训练上又有了新的进展,他们将论文《Improved Training of Wasserstein GANs》发布在了arXiv上。研究者们发现失败的案例通常是由在WGAN中使用权重剪枝来对critic实施Lipschitz约束导致的。在本片论文中,研究者们提出了一种替代权重剪枝实施Lipschitz约束的方法:惩罚critic对输入的梯度。该方法收敛速度更快,并能够生成比权重剪枝的WGAN更高质量的样本
注2:我们现在大概可以把目前已经开发出来的GAN模型分个类。
第一类是要假设无限建模能力、以此证明能够生成真实样本的模型。Goodfellow的经典GAN,EBGAN,还有最近出现的最小二乘GAN,都基于这样的假设。
而这些GAN都存在梯度消失的问题:即当真实样本和生成样本的流型没有重叠或者重叠可以忽略时,它们优化生成网络的目标函数是一个常数。
对GAN来说是J-S距离,EB-GAN是total variation距离,最小二乘GAN是Pearson 距离。这时,这些梯度就消失了。
这里似乎可以建立个猜想:一旦要假设无限建模能力,那么梯度消失就是不可避免的。也就是说无限建模能力是引起梯度消失的本质原因。不过我现在还没有证明这点。
第二类就是GLS-GAN了。代表就是LS-GAN和WGAN,它们都是GLS-GAN特例了。这第二类不用假设无限建模能力,也没有梯度消失问题。
那有没有第三类呢?现在我也不知道:)
7)InfoGAN+Improved GAN
注:提出许多训练GAN的小trick,有着很强的实际意义;Improved GAN实际上是提出了几个使得GANs更稳定的技术,包括:feature matching、minibatch discrimination、historicalaveraging、one-sided label smoothing、virtual batch normalization。
InfoGAN代码:https://github.com/openai/InfoGAN
Improved GAN代码:https://github.com/openai/improved-gan