Windows10下Eclipse搭建Hadoop3开发环境
前言
由于笔记本配置限制,虚拟机CentOs-7关闭了图形界面,作者在Windows端编写mapreduce程序然后在linux上运行。
工具
windows 10
CentOs-7(已安装,见上一博文)
eclipse-jee-oxygen-2-win32-x86_64.zip(采用其他精简版的eclipse可能会出问题)
jdk1.8(请保证jdk位数跟计算机位数一致)
在Windows上解压Hadoop3
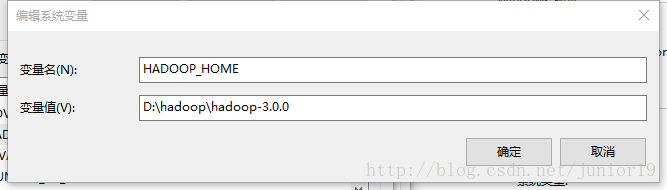
我们编程要用到hadoop的库,需要将
hadoop-3.0.0.tar.gz(最好跟linux上hadoop版本一致)解压一下,然后前往https://download.csdn.net/download/junior19/10292556下载这个东西,覆盖掉hadoop-3.0.0\bin文件夹;接着将bin里面的hadoop.dll复制到C:\Windows\System32中。(hadoop.dll文件尽量用最新版的)到系统->高级系统设置->环境变量下面的系统变量处选择“新建”
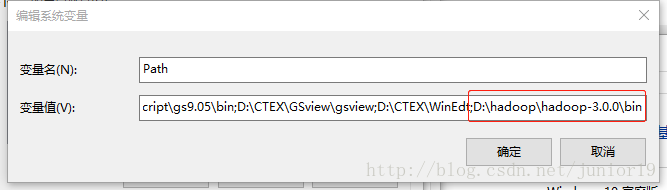
然后设置一下PATH
开放Hadoop的权限
- 为了能在Ecplise上对Linux的HDFS文件操作,需要设置一下权限。
- 进入Linux修改里面的
hdfs-site.xml,添加下面代码
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
- 1
- 2
- 3
- 4
- 请保证已经在hadoop上已经创建了用户以及新建了
input文件夹,如果之前没做这一步请执行以下命令(开启Hadoop集群后)
hadoop dfs -mkdir -p /user/hadoop
hadoop dfs -mkdir input
- 1
- 2
- (开启Hadoop集群后)执行
hadoop fs -chmod 777 /user/hadoop
在Eclipse上安装Hadoop插件
自行去下载
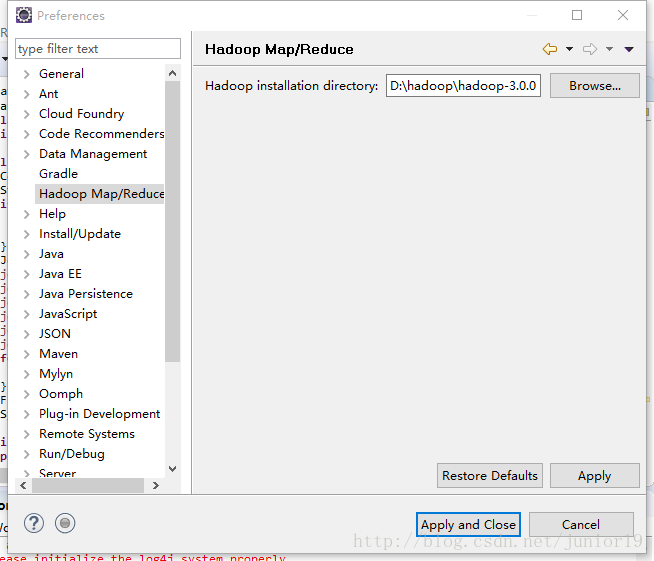
hadoop-eclipse-plugin-2.6.0.jar,放到Eclipse的plugins目录下,重启Eclipse。打开eclipse,在
window->Preferences->Hadoop Map/Reduce下设置Hadoop的解压路径
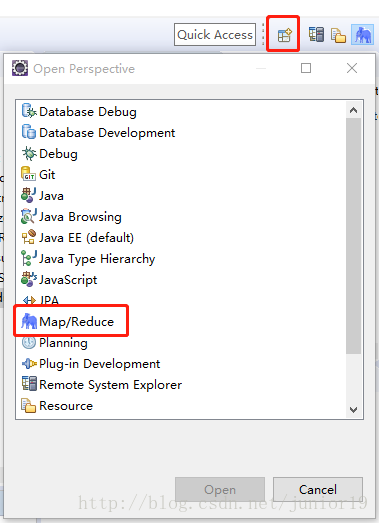
点击
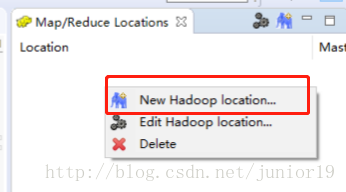
window->show view->other->map/reduce locationsOPEN。- 也可以在右上角的这里切换到map/reduce项目(以后可以在这里切回去Resource界面)
- 右键new一个
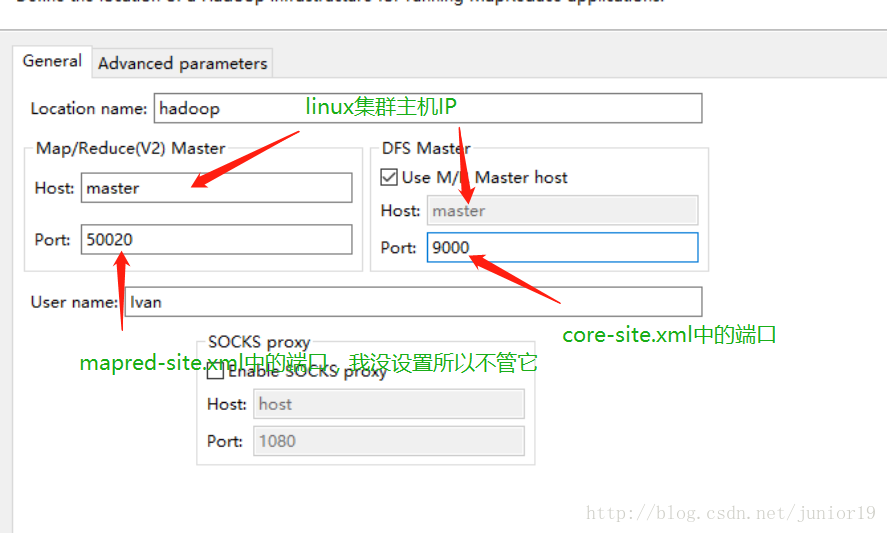
- 配置如下,Host那里最好直接填IP地址,如果像我这样填Linux主机名请先在Windows的Hosts文件设置好IP映射
然后点击右边设置一下
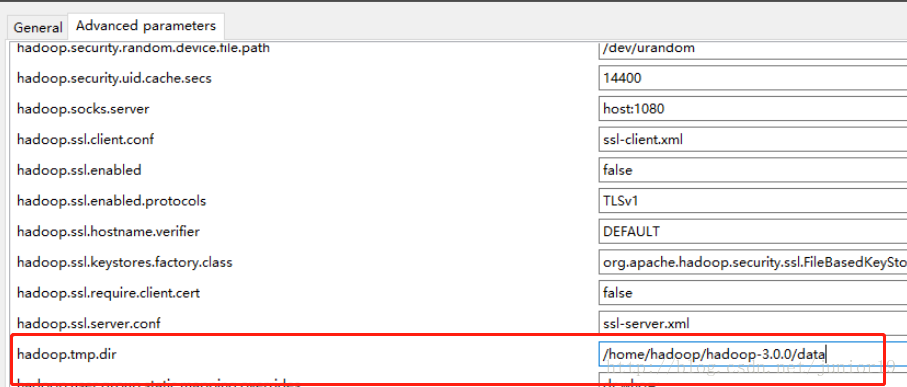
hadoop.tmp.dir的地址,跟core-site.xml的要一致
还有这个我们之前设置为1
- Finish后可能会报
NullPointer错误,貌似没影响先不理它。

运行WordCount例子
- 先去linux启动下Hadoop集群
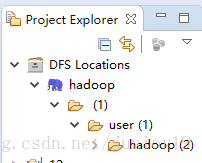
start-all.sh - 此时Eclipse应该能看到以下内容,没有就试试右键刷新下
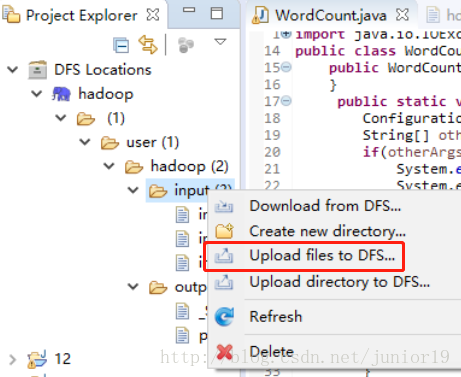
- 注意要先创建一些文件到
input文件夹内,创建方法可以在linux上用命令行上传上去,也可以先在windows新建好一些形如input1.txt文件,里面随便填一些句子hello word之类的,然后在Eclipse直接上传上去。
- 新建项目,
File->new->Project->Map/Reduce project,包名最好留空!否则最后运行老会遇到”找不到class”错误。 - 新建一个class命名为
WordCount加入下面代码
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values<span class="hljs-preprocessor">.iterator</span>()<span class="hljs-comment">; i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
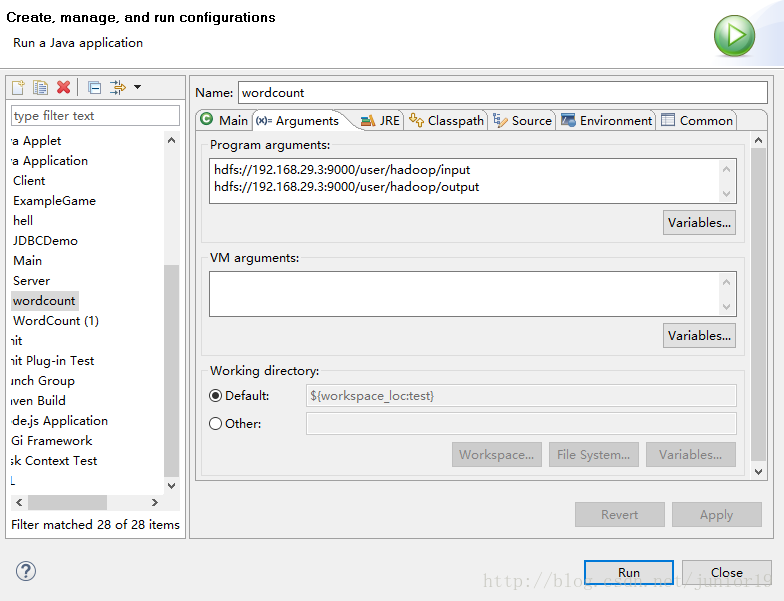
- 右键class选择
run as->Run configuations设置如下,当然里面的IP填你Linux主机的IP,然后RUN即可。
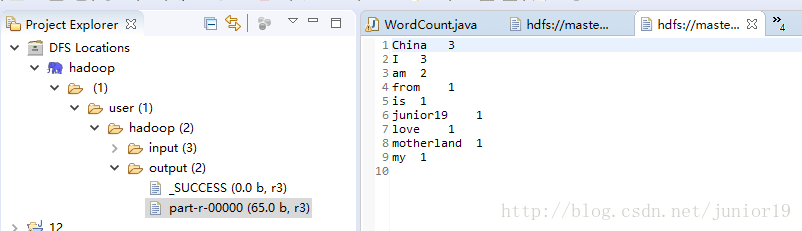
- 输出结果如下,下次执行的话需要先将
output文件夹删除掉。
打包JAR在linux运行
- 如果上述步骤搞不好,无法在eclipse直接运行代码,也可以
export出一个jar包,通过SFTP发到linux上执行
hadoop jar WordCount.jar WordCount input output
- 1
这里中间的WordCount貌似是填Main函数的所在Class名,但是网上说填包名,我报错无数次(找不到class)之后,在新建project时不用包名才成功运行。
一些自己遇到的问题和解决方法
- eclipse下的plugins导入hadoop-eclipse-plugin-2.7.1.jar,Preference下没有hadoop Map/Reduce的解决方法
这种现象一般由于安装在eclipse\plugins下的插件没有导入的问题。 解决方法:把
eclipse\configuration\org.eclipse.update 删除掉。出现这种情况的原因是在你安装新的插件以前你启动过eclipse ,在 org.eclipse.update文件夹下记录了插件的历史更新情况,它只记忆了以前的插件更新情况,而你新安装的插件它并不记录。(转载)

这种情况一般是由于log4j这个日志信息打印模块的配置信息没有给出造成的,可以在项目的src目录下,新建一个文件new->other->general->file,命名为“log4j.properties”,填入以下信息:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appenderlogfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n保存后重新运行即可成功。