Ubuntu18.04配置Hadoop
1. 实验环境
- 64位ubuntu18.04虚拟机(master,slave1,slave2)
- 需要的软件:
- hadoop3.1.0
- jdk-8u171-linux-x64
2. 实验步骤
master、slave1、slave2都需要配置
修改各个节点的主机名,使其与该节点的角色名一致,如 master,slave1,slave2:
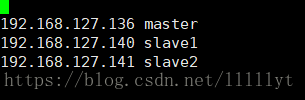
sudo vi /etc/hostname #编辑 /etc/hostname 文件从而修改主机名 sudo reboot #重启使新主机名生效修改各个 hosts 文件,在本地植入部分 DNS 映射,将对应的角色名与 IP 匹配起来,然 后尝试用角色名相互 ping,相互能 ping 通证明配置成功
sudo vi /etc/hosts #编辑 /etc/hosts 文件,插入角色与 IP 映射一下为需要添加的(其他的不需要改动,ip应与虚拟机的ip相应)- 配置 SSH 无密码登录 (网上教程比较多不多阐述)
- 安装 JDK(网上教程比较多不多阐述)
安装 Hadoop
在各个节点上将 hadoop 解压到/usr/local/目录下,改变其所属用户和所属组(让 hadoop 软件用 hadoop 账号登录时对 hadoop 文件夹拥有最高权限):
tar -zxvf hadoop-3.1.0.tar.gz -C /usr/local/ sudo mv /usr/local/hadoop-3.1.0 /usr/local/hadoop #mv 实现重命名 sudo chown -R hadoop:hadoop /usr/local/hadoop修改 slaves 文件,让 hadoop 知道自己可以聚合的节点名(保证与 hosts 里的角色 名一致):
vi /usr/local/hadoop/etc/hadoop/slaves修改 core-site.xml 文件如下:
vi /usr/local/hadoop/etc/hadoop/core-site.xml<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>修改hdfs-site.xml文件如下(启用所有节点作为DataNode,故replication=3):
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/hdfs/data</value> </property> <property> <name>dfs.http.address</name> <value>192.168.127.136:50070</value> </property> </configuration>修改 mapred-site.xml 文件如下:
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/local/hadoop/share/hadoop, /usr/local/hadoop/share/hadoop/common/*, /usr/local/hadoop/share/hadoop/common/lib/*, /usr/local/hadoop/share/hadoop/hdfs/*, /usr/local/hadoop/share/hadoop/hdfs/lib/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/yarn/*, /usr/local/hadoop/share/hadoop/yarn/lib/* </value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> </configuration>修改 yarn-site.xml 文件如下(启用 yarn 资源管理器):
vi /usr/local/hadoop/etc/hadoop/yarn-site.xml<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>修改 hadoop-env.sh 文件,将54行JAVA_HOME 的值换成 jdk 所在的路径:
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh# The java implementation to use. By default, this environment # variable is REQUIRED on ALL platforms except OS X! export JAVA_HOME=/usr/local/jvm/jdk1.8.0_171 # Location of Hadoop. By default, Hadoop will attempt to determine # this location based upon its execution path. # export HADOOP_HOME= # Location of Hadoop's configuration information. i.e., where this # file is living. If this is not defined, Hadoop will attempt to # locate it based upon its execution path. # # NOTE: It is recommend that this variable not be set here but in # /etc/profile.d or equivalent. Some options (such as # --config) may react strangely otherwise. # export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop

启动及验证 hadoop:
对 hadoop 进行 NameNode 的格式化:
master进行格式化,slave1和slave2不需要
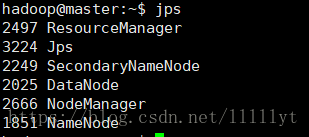
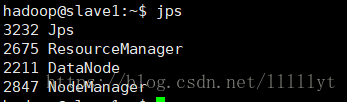
/usr/local/hadoop/bin/hdfs namenode -format - 启动 hdfs 和 yarn,并在各个节点上输入 jps 查看启动的服务:
master,slave1,slave2都需要启动
/usr/local/hadoop/sbin/start-dfs.sh
/usr/local/hadoop/sbin/start-yarn.sh
jps # 每个节点都查看一次
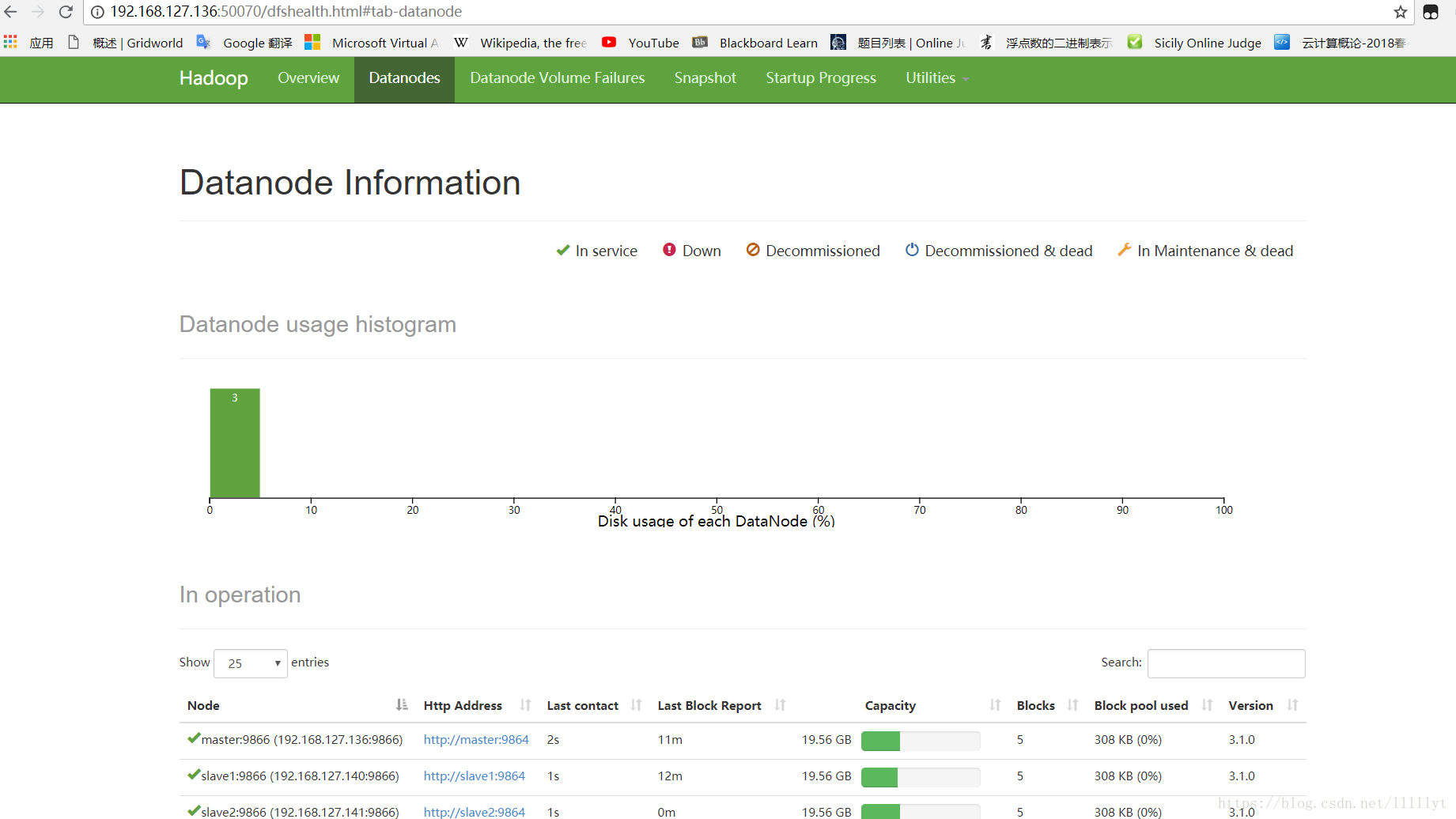
3. 遇到的问题和解决
在外部浏览器输入 master 的 IP 地址和 50070 端口失败
解决:
在hdfs-site.xml添加一下代码<property> <name>dfs.http.address</name> <value>192.168.127.136:50070</value> </property>
建议
每个虚拟机的内存2G,不然可能会出现virtual-memory的错误