如何在linux上安装spark
首先我这里使用的是Ubuntu18.04,64位系统

安装spark之前,需要先搭建环境
1.安装jdk
我安装到了/usr/local/java目录下,然后在~/.bashrc中配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
然后source ~./bashrc
最后在终端输入java -version

显示jdk的版本是1.8.0,表示安装成功
2.安装scala
我安装到了/usr/local/scala目录下,然后在~/.bashrc中配置环境变量
export SCALA_HOME=/usr/local/scala/scala-2.12.4
export PATH=$SCALA_HOME/bin:$PATH
然后source ~./bashrc
最后在终端输入scala -version

也可以进入scala交互式环境
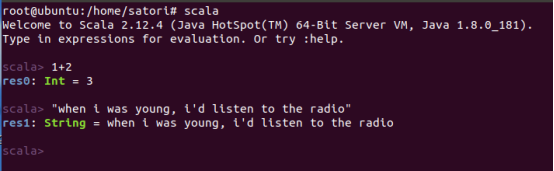
证明scala安装成功,scala版本是2.12.4
3.安装Hadoop
由于Spark没有HDFS,所以需要安装一下Hadoop,当然Hadoop不是唯一的选择,也可以选择其他的。
我安装到了/usr/local/hadoop目录下,然后在~/.bashrc中配置环境变量
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.1
export PATH=$HADOOP_HOME/bin:$PATH
然后source ~./bashrc
输入hadoop version
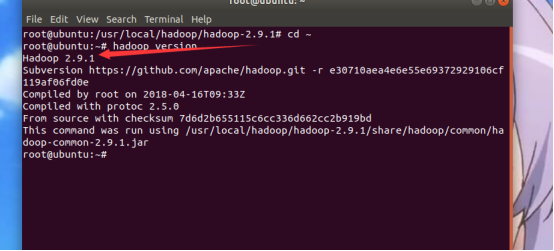
显示版本2.9.1
这里还需要修改一些其他的配置文件,进入到$HADOOP_HOME/etc/hadoop中。

首先修改hadoop-env.sh
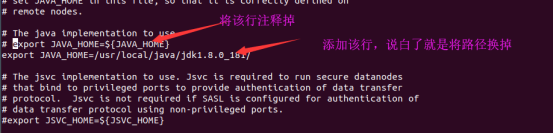
然后修改core-site.xml
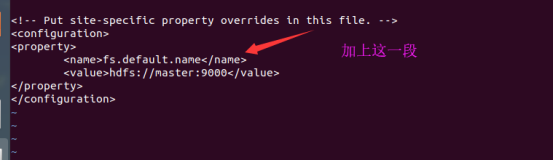
然后修改hdfs-site.xml
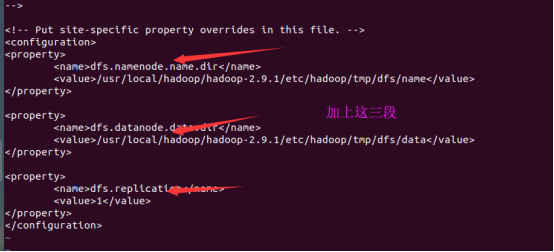
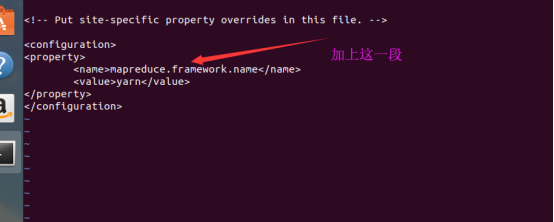
然后修改mapred-site.xml,由于没有这个文件,但有mapred-site.xml.template这个文件,所以我们拷贝一份。

然后配置yarn-site.xml
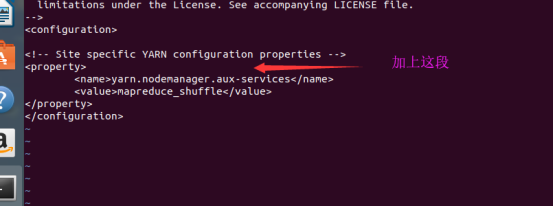
配置完成
接下来格式化一下
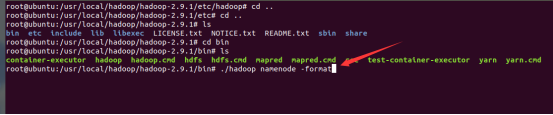
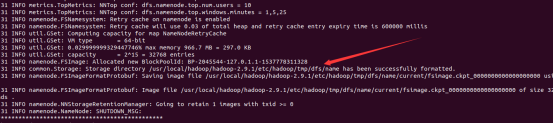
格式化成功,看一下相应的目录
可以看到之前新建的空目录,里面已经有东西了。
如果需要密码,就输入这两行,就可以免密码登陆了
最后启动一下hadoop
ssh-keygen -t rsa -P
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

4.安装maven
我安装到了/usr/local/java目录下,然后在~/.bashrc中配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
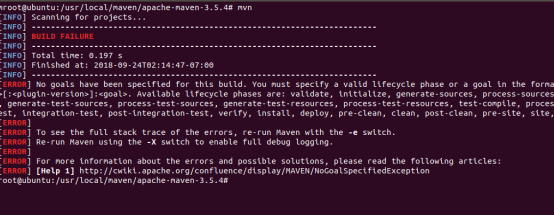
输入mvn输出如下,说明安装成功
5.安装python
直接apt-get install python3即可
6.安装spark
我安装到了/usr/local/目录下,然后在~/.bashrc中配置环境变量
export SPARK_HOME=/usr/local/spark/spark-2.3.1-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
