版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qingqing7/article/details/80653855
第一用来预测,第二寻找因变量的影响因素。
自变量可以是离散值,也可以是连续值;逻辑回归中的离散变量 数据不平衡问题: Logistic回归的非平衡数据问题及其解决方法 Logistic模型对非平衡数据的敏感性:测度、修正与比较
原理的相对简单,可解释性强等优点,它还可以作为众多集成算法以及深度学习的基本组成单位Logistic回归分析报告结果解读分析
广义线性模型
如果是连续的,就是线性回归
如果是二项分布,就是logistic回归
如果是poisson分布,就是poisson回归
如果负二项分布,就是负二项回归
线性回归和Logistic回归都是广义线性模型的特例。
y
y
y
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
x_1, x_2, x_3, ... , x_n
x 1 , x 2 , x 3 , . . . , x n
y
y
y
y
=
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
⋯
+
w
n
∗
x
n
−
−
−
−
−
(
1
)
y =w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +\cdots+w_n*x_n-----(1)
y = w 0 + w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + ⋯ + w n ∗ x n − − − − − ( 1 )
w
w
w
y
y
y
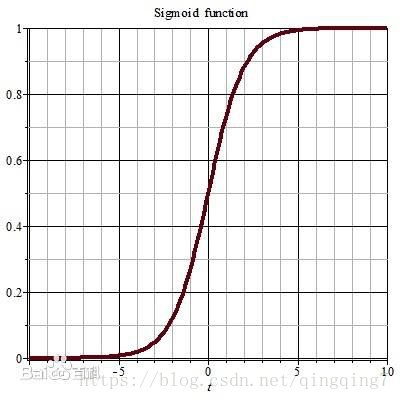
s
(
x
)
=
1
1
+
e
−
x
s(x)=\frac{1}{1+e^{-x}}
s ( x ) = 1 + e − x 1
y
=
1
1
+
e
−
(
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
)
−
−
−
−
(
2
)
y=\frac{1}{1+e^{-(w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n)}}----(2)
y = 1 + e − ( w 0 + w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + . . . + w n ∗ x n ) 1 − − − − ( 2 )
y
=
p
y=p
y = p
p
≥
0.5
p\geq 0.5
p ≥ 0 . 5
p
<
0.5
p< 0.5
p < 0 . 5
w
0
、
w
1
、
w
2
、
w
3
、
.
.
.
、
w
n
w_0 、w_1、w_2、w_3、...、w_n
w 0 、 w 1 、 w 2 、 w 3 、 . . . 、 w n
1
−
p
1-p
1 − p
优势
Ω
\Omega
Ω
Ω
\Omega
Ω
Ω
=
p
1
−
p
=
e
(
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
)
\Omega=\frac{p}{1-p}=e^{(w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n)}
Ω = 1 − p p = e ( w 0 + w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + . . . + w n ∗ x n )
Ω
\Omega
Ω
p
p
p
Ω
\Omega
Ω
Ω
Ω
Ω
(
0
,
+
∞
)
(0,+\infty)
( 0 , + ∞ )
Ω
\Omega
Ω
l
n
Ω
=
l
n
p
1
−
p
=
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
ln\Omega=ln\frac{p}{1-p}=w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n
l n Ω = l n 1 − p p = w 0 + w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + . . . + w n ∗ x n
l
o
g
i
t
logit
l o g i t
l
o
g
i
t
logit
l o g i t
l
n
Ω
ln\Omega
l n Ω
l
o
g
i
t
P
logitP
l o g i t P
l
o
g
i
t
P
logitP
l o g i t P
(
−
∞
,
+
∞
)
(-\infty,+\infty)
( − ∞ , + ∞ )
l
o
g
i
t
logit
l o g i t
设
y
y
y
(
x
1
,
x
2
,
…
,
x
p
)
(x_1,x_2,\dots,x_p)
( x 1 , x 2 , … , x p )
y
y
y
(
x
i
1
,
x
i
2
,
…
,
x
i
p
;
y
i
)
(
i
=
1
,
2
,
…
,
n
)
(x_{i1},x_{i2},\dots,x_{ip};y_i)(i=1,2,\dots,n)
( x i 1 , x i 2 , … , x i p ; y i ) ( i = 1 , 2 , … , n )
y
i
y_i
y i
y
i
y_i
y i
p
i
p_i
p i
P
(
y
i
=
1
)
=
p
i
P(y_i=1)=p_i
P ( y i = 1 ) = p i
P
(
y
i
=
0
)
=
1
−
p
i
P(y_i=0)=1-p_i
P ( y i = 0 ) = 1 − p i
P
(
y
i
)
=
p
i
y
i
(
1
−
p
i
)
1
−
y
i
;
i
=
1
,
2
,
…
,
n
;
y
i
=
0
,
1
P(y_i)=p_i^{y_i}(1-p_i)^{1-y_i};i=1,2,\dots,n;y_i=0,1
P ( y i ) = p i y i ( 1 − p i ) 1 − y i ; i = 1 , 2 , … , n ; y i = 0 , 1
(
y
1
,
y
2
,
…
,
y
n
)
(y_1,y_2,\dots,y_n)
( y 1 , y 2 , … , y n )
L
=
∏
i
=
1
n
p
(
y
i
)
=
∏
i
=
1
n
p
i
y
i
(
1
−
p
i
)
1
−
y
i
−
−
−
−
(
3
)
L=\prod_{i=1}^{n} p(y_i)=\prod_{i=1}^{n}p_i^{y_i}(1-p_i)^{1-y_i}----(3)
L = i = 1 ∏ n p ( y i ) = i = 1 ∏ n p i y i ( 1 − p i ) 1 − y i − − − − ( 3 )
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1x_{i1}+\dots+w_p x_{ip})}}
p i = 1 + e − ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) 1
w
0
、
w
1
、
…
、
w
p
w_0 、w_1 、\dots、w_p
w 0 、 w 1 、 … 、 w p
L
L
L
l
n
L
=
l
n
(
∏
i
=
1
n
p
i
y
i
(
1
−
p
i
)
1
−
y
i
)
=
l
n
(
∏
i
=
1
n
p
i
y
i
)
+
l
n
(
∏
i
=
1
n
(
1
−
p
i
)
1
−
y
i
)
=
∑
i
=
1
n
y
i
l
n
p
i
+
∑
i
=
1
n
(
1
−
y
i
)
l
n
(
1
−
p
i
)
=
∑
i
=
1
n
l
n
(
1
−
p
i
)
+
∑
i
=
1
n
y
i
l
n
p
i
1
−
p
i
\begin{matrix} lnL&=&ln(\prod_{i=1}^{n}p_i^{y_i}(1-p_i)^{1-y_i})\\ &=&ln(\prod_{i=1}^{n}p_i^{y_i})+ln(\prod_{i=1}^{n}(1-p_i)^{1-y_i})\\ &=&\sum_{i=1}^{n}y_i lnp_i+\sum_{i=1}^{n}(1-y_i) ln(1-p_i)\\ &=&\sum_{i=1}^{n}ln(1-p_i) +\sum_{i=1}^{n}y_iln\frac{p_i}{1-p_i}\\ \end{matrix}
l n L = = = = l n ( ∏ i = 1 n p i y i ( 1 − p i ) 1 − y i ) l n ( ∏ i = 1 n p i y i ) + l n ( ∏ i = 1 n ( 1 − p i ) 1 − y i ) ∑ i = 1 n y i l n p i + ∑ i = 1 n ( 1 − y i ) l n ( 1 − p i ) ∑ i = 1 n l n ( 1 − p i ) + ∑ i = 1 n y i l n 1 − p i p i
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1x_{i1}+\dots+w_p x_{ip})}}
p i = 1 + e − ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) 1
l
n
Ω
=
l
n
p
1
−
p
=
w
0
+
w
1
∗
x
1
+
w
2
∗
x
2
+
w
3
∗
x
3
+
.
.
.
+
w
n
∗
x
n
ln\Omega=ln\frac{p}{1-p}=w_0 +w_1*x_1 +w_2*x_2 +w_3*x_3 +...+w_n*x_n
l n Ω = l n 1 − p p = w 0 + w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 3 + . . . + w n ∗ x n
l
n
L
=
−
∑
i
=
1
n
l
n
(
1
+
e
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
)
+
∑
i
=
1
n
y
i
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
=
∑
i
=
1
n
[
y
i
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
−
l
n
(
1
+
e
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
)
]
\begin{matrix} lnL&=&-\sum_{i=1}^{n}ln(1+e^{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}) + \sum_{i=1}^{n} y_i (w_0+w_1x_{i1}+\dots+w_p x_{ip})\\ &=&\sum_{i=1}^{n} \left[y_i (w_0+w_1x_{i1}+\dots+w_p x_{ip})-ln(1+e^{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}) \right]\\ \end{matrix}
l n L = = − ∑ i = 1 n l n ( 1 + e ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) ) + ∑ i = 1 n y i ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) ∑ i = 1 n [ y i ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) − l n ( 1 + e ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) ) ]
w
=
(
w
0
,
w
1
,
…
,
w
p
)
T
,
x
i
=
(
1
,
x
i
1
,
…
,
x
i
p
)
T
,
x
i
中
添
加
了
1
是
为
了
与
w
相
匹
配
w=(w_0,w_1,\dots,w_p)^T,x_i=(1,x_{i1},\dots,x_{ip})^T,x_i中添加了1是为了与w相匹配
w = ( w 0 , w 1 , … , w p ) T , x i = ( 1 , x i 1 , … , x i p ) T , x i 中 添 加 了 1 是 为 了 与 w 相 匹 配
l
n
L
lnL
l n L
l
n
L
=
∑
i
=
1
n
[
y
i
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
−
l
n
(
1
+
e
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
)
]
=
∑
i
=
1
n
[
y
i
w
T
x
i
−
l
n
(
1
+
e
w
T
x
i
)
]
\begin{matrix} lnL&=&\sum_{i=1}^{n} \left[y_i (w_0+w_1x_{i1}+\dots+w_p x_{ip})-ln(1+e^{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}) \right]\\ &=&\sum_{i=1}^{n} \left[ y_i w^T x_i-ln(1+e^{w^T x_i})\right]\\ \end{matrix}
l n L = = ∑ i = 1 n [ y i ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) − l n ( 1 + e ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) ) ] ∑ i = 1 n [ y i w T x i − l n ( 1 + e w T x i ) ]
w
0
、
w
1
、
…
、
w
p
w_0 、w_1 、\dots、w_p
w 0 、 w 1 、 … 、 w p
l
n
L
lnL
l n L
J
(
w
)
=
−
l
n
L
(
w
)
J(w)=- lnL(w)
J ( w ) = − l n L ( w )
β
β
β
w
=
w
−
α
∂
J
(
w
)
∂
w
=
w
−
α
∂
(
−
l
n
L
(
w
)
)
∂
w
w = w -\alpha \frac{\partial J(w)}{\partial w}= w -\alpha \frac{\partial (-lnL(w))}{\partial w}
w = w − α ∂ w ∂ J ( w ) = w − α ∂ w ∂ ( − l n L ( w ) )
∂
(
−
l
n
L
(
w
)
)
∂
w
=
∂
(
−
∑
i
=
1
n
[
y
i
w
T
x
i
−
l
n
(
1
+
e
w
T
x
i
)
]
)
∂
w
=
∂
(
∑
i
=
1
n
[
l
n
(
1
+
e
w
T
x
i
)
−
y
i
w
T
x
i
]
)
∂
w
=
∑
i
=
1
n
(
e
w
T
x
i
1
+
e
w
T
x
i
−
y
i
)
∂
(
w
T
x
i
)
∂
w
=
∑
i
=
1
n
(
1
1
+
e
−
w
T
x
i
−
y
i
)
∂
(
w
T
x
i
)
∂
w
=
∑
i
=
1
n
(
1
1
+
e
−
w
T
x
i
−
y
i
)
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w}&=&\frac{\partial (-\sum_{i=1}^{n} \left[ y_iw^T x_i-ln(1+e^{w^T x_i})\right])}{\partial w}\\ &=&\frac{\partial (\sum_{i=1}^{n} \left[ ln(1+e^{w^T x_i}) - y_i w^T x_i\right])}{\partial w}\\ &=&\sum_{i=1}^{n}(\frac{e^{w^T x_i}}{1+e^{w^T x_i}}-y_i)\frac{\partial{(w^T x_i)}}{\partial{ w}}\\ &=&\sum_{i=1}^{n}(\frac{1}{1+e^{-w^T x_i}}-y_i)\frac{\partial{(w^T x_i)}}{\partial{w}}\\ &=&\sum_{i=1}^{n}(\frac{1}{1+e^{-w^T x_i}}-y_i)\frac{\partial{(w_0+w_1x_{i1}+\dots+w_p x_{ip})}}{\partial{w}}\\ \end{matrix}
∂ w ∂ ( − l n L ( w ) ) = = = = = ∂ w ∂ ( − ∑ i = 1 n [ y i w T x i − l n ( 1 + e w T x i ) ] ) ∂ w ∂ ( ∑ i = 1 n [ l n ( 1 + e w T x i ) − y i w T x i ] ) ∑ i = 1 n ( 1 + e w T x i e w T x i − y i ) ∂ w ∂ ( w T x i ) ∑ i = 1 n ( 1 + e − w T x i 1 − y i ) ∂ w ∂ ( w T x i ) ∑ i = 1 n ( 1 + e − w T x i 1 − y i ) ∂ w ∂ ( w 0 + w 1 x i 1 + ⋯ + w p x i p )
1
1
+
e
−
w
T
x
i
−
y
i
=
e
i
\frac{1}{1+e^{-w^T x_i}}-y_i=e_i
1 + e − w T x i 1 − y i = e i
e
i
e_i
e i
∂
(
−
l
n
L
(
w
)
)
∂
w
=
∑
i
=
1
n
e
i
∂
(
w
T
x
i
)
∂
w
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w} &=&\sum_{i=1}^n e_i \frac{\partial (w^Tx_i)}{\partial w}\\ &=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w}\\ \end{matrix}
∂ w ∂ ( − l n L ( w ) ) = = ∑ i = 1 n e i ∂ w ∂ ( w T x i ) ∑ i = 1 n e i ∂ w ∂ ( w 0 + w 1 x i 1 + ⋯ + w p x i p )
∂
(
−
l
n
L
(
w
)
)
∂
w
\frac{\partial (-lnL(w))}{\partial w}
∂ w ∂ ( − l n L ( w ) )
∂
(
−
l
n
L
(
w
)
)
∂
w
0
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
0
=
∑
i
=
1
n
e
i
∗
1
∂
(
−
l
n
L
(
w
)
)
∂
w
1
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
1
=
∑
i
=
1
n
e
i
∗
x
i
1
⋯
=
⋯
=
⋯
∂
(
−
l
n
L
(
w
)
)
∂
w
p
=
∑
i
=
1
n
e
i
∂
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
∂
w
p
=
∑
i
=
1
n
e
i
∗
x
i
p
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w_0}&=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w_0}&=&\sum_{i=1}^n e_i *1\\ \frac{\partial (-lnL(w))}{\partial w_1}&=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w_1}&=&\sum_{i=1}^n e_i *x_{i1}\\ \cdots&=&\cdots&=&\cdots\\ \frac{\partial (-lnL(w))}{\partial w_p}&=&\sum_{i=1}^n e_i \frac{\partial (w_0+w_1x_{i1}+\cdots+w_p x_{ip})}{\partial w_p}&=&\sum_{i=1}^n e_i *x_{ip}\\ \end{matrix}
∂ w 0 ∂ ( − l n L ( w ) ) ∂ w 1 ∂ ( − l n L ( w ) ) ⋯ ∂ w p ∂ ( − l n L ( w ) ) = = = = ∑ i = 1 n e i ∂ w 0 ∂ ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) ∑ i = 1 n e i ∂ w 1 ∂ ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) ⋯ ∑ i = 1 n e i ∂ w p ∂ ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) = = = = ∑ i = 1 n e i ∗ 1 ∑ i = 1 n e i ∗ x i 1 ⋯ ∑ i = 1 n e i ∗ x i p
∂
(
−
l
n
L
(
w
)
)
∂
w
\frac{\partial (-lnL(w))}{\partial w}
∂ w ∂ ( − l n L ( w ) )
∂
(
−
l
n
L
(
w
)
)
∂
w
=
[
∑
i
=
1
n
e
i
∗
1
∑
i
=
1
n
e
i
∗
x
i
1
⋯
∑
i
=
1
n
e
i
∗
x
i
p
]
=
[
e
1
+
e
x
+
⋯
+
e
n
e
1
x
11
+
e
2
x
21
+
⋯
+
e
n
x
n
1
⋯
e
1
x
1
p
+
e
2
x
2
p
+
⋯
+
e
n
x
n
p
]
=
[
1
+
x
11
+
x
12
+
⋯
+
x
1
p
1
+
x
21
+
x
22
+
⋯
+
x
2
p
⋯
1
+
x
n
1
+
x
n
2
+
⋯
+
x
n
p
]
T
∗
[
e
1
⋯
e
n
]
\begin{matrix} \frac{\partial (-lnL(w))}{\partial w} &=& \left[ \begin{matrix} \sum_{i=1}^n e_i *1\\ \sum_{i=1}^n e_i *x_{i1}\\ \cdots\\ \sum_{i=1}^n e_i *x_{ip}\\ \end{matrix}\right]\\ &=& \left[ \begin{matrix} e_1+e_x+\cdots+e_n\\ e_1x_{11}+e_2x_{21}+\cdots+e_nx_{n1}\\ \cdots\\ e_1x_{1p}+e_2x_{2p}+\cdots+e_nx_{np}\\ \end{matrix}\right]\\ &=& \left[ \begin{matrix} 1+x_{11}+x_{12}+\cdots+x_{1p}\\ 1+x_{21}+x_{22}+\cdots+x_{2p}\\ \cdots\\ 1+x_{n1}+x_{n2}+\cdots+x_{np}\\ \end{matrix}\right]^T* \left[ \begin{matrix} e_1\\ \cdots\\ e_n\\ \end{matrix}\right]\\ \end{matrix}
∂ w ∂ ( − l n L ( w ) ) = = = ⎣ ⎢ ⎢ ⎡ ∑ i = 1 n e i ∗ 1 ∑ i = 1 n e i ∗ x i 1 ⋯ ∑ i = 1 n e i ∗ x i p ⎦ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎡ e 1 + e x + ⋯ + e n e 1 x 1 1 + e 2 x 2 1 + ⋯ + e n x n 1 ⋯ e 1 x 1 p + e 2 x 2 p + ⋯ + e n x n p ⎦ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎡ 1 + x 1 1 + x 1 2 + ⋯ + x 1 p 1 + x 2 1 + x 2 2 + ⋯ + x 2 p ⋯ 1 + x n 1 + x n 2 + ⋯ + x n p ⎦ ⎥ ⎥ ⎤ T ∗ ⎣ ⎡ e 1 ⋯ e n ⎦ ⎤
[
1
,
x
11
,
x
12
,
⋯
 
,
x
1
p
1
,
x
21
,
x
22
,
⋯
 
,
x
2
p
⋯
1
,
x
n
1
,
x
n
2
,
⋯
 
,
x
n
p
]
=
X
\left[ \begin{matrix} 1,x_{11},x_{12},\cdots,x_{1p}\\ 1,x_{21},x_{22},\cdots,x_{2p}\\ \cdots\\ 1,x_{n1},x_{n2},\cdots,x_{np}\\ \end{matrix}\right] =X
⎣ ⎢ ⎢ ⎡ 1 , x 1 1 , x 1 2 , ⋯ , x 1 p 1 , x 2 1 , x 2 2 , ⋯ , x 2 p ⋯ 1 , x n 1 , x n 2 , ⋯ , x n p ⎦ ⎥ ⎥ ⎤ = X
[
e
1
⋯
e
n
]
=
E
\left[ \begin{matrix} e_1\\ \cdots\\ e_n\\ \end{matrix}\right]=E
⎣ ⎡ e 1 ⋯ e n ⎦ ⎤ = E
∂
(
−
l
n
L
(
w
)
)
∂
w
=
X
T
E
\frac{\partial (-lnL(w))}{\partial w}=X^TE
∂ w ∂ ( − l n L ( w ) ) = X T E
w
=
w
−
α
X
T
E
w=w-\alpha X^TE\\
w = w − α X T E
通过定一个阈值,比如
p
0
=
0.5
p_0=0.5
p 0 = 0 . 5
p
≥
p
0
p\geq p_0
p ≥ p 0
p
<
p
0
p< p_0
p < p 0
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
≥
0.5
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }} \geq 0.5
p i = 1 + e − ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) 1 ≥ 0 . 5
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
<
0.5
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }} < 0.5
p i = 1 + e − ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) 1 < 0 . 5
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
>
0
w_0+w_1 x_i1+⋯+w_p x_ip>0
w 0 + w 1 x i 1 + ⋯ + w p x i p > 0
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
<
0
w_0+w_1 x_{i1}+⋯+w_p x_{ip}<0
w 0 + w 1 x i 1 + ⋯ + w p x i p < 0
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w 0 + w 1 x i 1 + ⋯ + w p x i p
将测试数据代入方程
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }}
p i = 1 + e − ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) 1
p
i
>
0.5
p_i>0.5
p i > 0 . 5
来源:https://blog.csdn.net/szu_hadooper/article/details/78619001
是直接根据每个类别,都建立一个二分类器,带有这个类别的样本标记为1,带有其他类别的样本标记为0。假如我们有个类别,最后我们就得到了个针对不同标记的普通的logistic分类器。
X
∈
R
m
×
n
X\in R^{m\times n}
X ∈ R m × n
Y
∈
R
k
Y\in R^k
Y ∈ R k
我们挑选出标记为
c
(
c
≤
k
)
c(c\leq k)
c ( c ≤ k )
h
c
(
x
)
h_c(x)
h c ( x )
按照上面的步骤,我们可以得到k个不同的分类器。针对一个测试样本,我们需要找到这个分类函数输出值最大的那一个,即为测试样本的标记:
a
r
g
m
a
x
c
h
c
(
x
)
,
c
=
1
,
2
,
⋯
 
,
k
arg~max_c h_c(x),c=1,2,\cdots,k
a r g m a x c h c ( x ) , c = 1 , 2 , ⋯ , k
是修改logistic回归的损失函数,让其适应多分类问题。这个损失函数不再笼统地只考虑二分类非1就0的损失,而是具体考虑每个样本标记的损失。这种方法叫做softmax回归,即logistic回归的多分类版本。Softmax函数与交叉熵
在Logistic regression二分类问题中,我们可以使用sigmoid函数将输入
W
x
+
b
Wx+b
W x + b
a
1
,
a
2
,
.
.
.
,
a
C
a_1,a_2,...,a_C
a 1 , a 2 , . . . , a C
i
i
i
y
i
=
e
a
i
∑
k
=
1
C
e
a
k
∀
i
∈
1...
C
y_i=\frac{e^{a_i}}{∑^C_{k=1}e^{a_k}}~~~~~ ∀_i∈1...C
y i = ∑ k = 1 C e a k e a i ∀ i ∈ 1 . . . C
∑
i
=
1
C
y
i
=
1
∑^C_{i=1} y_i=1
∑ i = 1 C y i = 1 Softmax函数求导
损失函数:对数似然函数
x
x
x
t
t
t
θ
θ
θ
p
(
t
∣
x
)
p(t|x)
p ( t ∣ x )
p
(
t
∣
x
)
=
(
y
)
t
(
1
−
y
)
1
−
t
p(t|x)=(y)^t(1−y)^{1−t}
p ( t ∣ x ) = ( y ) t ( 1 − y ) 1 − t
y
=
f
(
x
)
y=f(x)
y = f ( x )
t
t
t
p
(
t
∣
x
)
=
∏
i
=
1
C
P
(
t
i
∣
x
)
t
i
=
∏
i
=
1
C
y
i
t
i
p(t|x)=∏_{i=1}^CP(t_i|x)^{t_i}=∏_{i=1}^Cy^{t_i}_i
p ( t ∣ x ) = i = 1 ∏ C P ( t i ∣ x ) t i = i = 1 ∏ C y i t i
t
i
t_i
t i
y
i
y_i
y i
l
C
E
=
−
l
o
g
p
(
t
∣
x
)
=
−
l
o
g
∏
i
=
1
C
y
i
t
i
=
−
∑
i
=
i
C
t
i
l
o
g
(
y
i
)
l_{CE}=−log~ p(t|x)=−log∏_{i=1}^C y^{t_i}_i=−∑_{i=i}^C t_ilog(y_i)
l C E = − l o g p ( t ∣ x ) = − l o g i = 1 ∏ C y i t i = − i = i ∑ C t i l o g ( y i ) 损失函数求导
l
C
E
l_{CE}
l C E
a
j
a_j
a j
∂
l
C
E
∂
a
j
=
−
∑
i
=
1
C
∂
t
i
l
o
g
(
y
i
)
∂
a
j
=
−
∑
i
=
1
C
t
i
∂
l
o
g
(
y
i
)
∂
a
j
=
−
∑
i
=
1
C
t
i
1
y
i
∂
y
i
∂
a
j
\frac{∂l_{CE}}{∂_{a_j}}=−∑_{i=1}^C \frac{∂t_ilog(y_i)}{∂a_j}=−∑_{i=1}^C t_i\frac{∂log(y_i)}{∂a_j}=−∑_{i=1}^C t_i\frac{1}{y_i}\frac{∂ y_i}{∂a_j}
∂ a j ∂ l C E = − i = 1 ∑ C ∂ a j ∂ t i l o g ( y i ) = − i = 1 ∑ C t i ∂ a j ∂ l o g ( y i ) = − i = 1 ∑ C t i y i 1 ∂ a j ∂ y i
∂
y
i
∂
a
j
\frac{∂ y_i}{∂a_j}
∂ a j ∂ y i
i
=
j
i=j
i = j
∂
y
i
∂
a
j
=
y
i
(
1
−
y
j
)
\frac{∂ y_i}{∂a_j}=y_i(1−y_j)
∂ a j ∂ y i = y i ( 1 − y j )
i
≠
j
i≠j
i ̸ = j
∂
y
i
∂
a
j
=
−
y
i
y
j
\frac{∂ y_i}{∂a_j}=−y_iy_j
∂ a j ∂ y i = − y i y j
所以,将求导结果代入上式:
−
∑
i
=
1
C
t
i
1
y
i
∂
y
i
∂
a
j
=
−
t
i
y
i
∂
y
i
∂
a
j
−
∑
i
≠
j
C
t
i
y
i
∂
y
i
∂
a
j
=
−
t
j
y
i
y
i
(
1
−
y
j
)
−
∑
i
≠
j
C
t
i
y
i
(
−
y
i
y
j
)
=
−
t
j
+
t
j
y
j
+
∑
i
≠
j
C
t
i
y
j
=
−
t
j
+
∑
i
=
1
C
t
i
y
j
=
−
t
j
+
y
j
∑
i
=
1
C
t
i
=
−
t
j
+
y
j
\begin{matrix} −∑_{i=1}^C t_i\frac{1}{y_i}\frac{∂ y_i}{∂a_j} &=&-\frac{t_i}{y_i}\frac{∂ y_i}{∂a_j}−∑_{i\neq j}^C \frac{t_i}{y_i}\frac{∂ y_i}{∂a_j}\\ &=&-\frac{t_j}{y_i}y_i(1−y_j)−∑_{i\neq j}^C \frac{t_i}{y_i}(−y_iy_j)\\ &=&-t_j+t_jy_j+∑_{i\neq j}^C t_iy_j\\ &=&-t_j+∑_{i=1}^C t_iy_j\\ &=&-t_j+y_j∑_{i=1}^C t_i\\ &=&-t_j+y_j\\ \end{matrix}
− ∑ i = 1 C t i y i 1 ∂ a j ∂ y i = = = = = = − y i t i ∂ a j ∂ y i − ∑ i ̸ = j C y i t i ∂ a j ∂ y i − y i t j y i ( 1 − y j ) − ∑ i ̸ = j C y i t i ( − y i y j ) − t j + t j y j + ∑ i ̸ = j C t i y j − t j + ∑ i = 1 C t i y j − t j + y j ∑ i = 1 C t i − t j + y j
也可参考:Deep Learning 学习随记(三)Softmax regression
逻辑回归主要用于分类,稍加改造也可以用于回归模型,但只适用于极特殊的分布函数,感觉没什么应用价值。
p
i
=
1
1
+
e
−
(
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
)
p_i=\frac{1}{1+e^{-(w_0+w_1 x_{i1}+⋯+w_p x_{ip} ) }}
p i = 1 + e − ( w 0 + w 1 x i 1 + ⋯ + w p x i p ) 1
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w 0 + w 1 x i 1 + ⋯ + w p x i p
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w 0 + w 1 x i 1 + ⋯ + w p x i p
w
0
+
w
1
x
i
1
+
⋯
+
w
p
x
i
p
w_0+w_1 x_{i1}+⋯+w_p x_{ip}
w 0 + w 1 x i 1 + ⋯ + w p x i p
逻辑回归方程的显著性检验的目的是检验所有自变量与logitP的线性关系是否显著,是否可以选择线性模型。原假设是假设各回归系数同时为0,自变量全体与logitP的线性关系不显著。如果方程中的诸多自变量对logitP
的线性解释有显著意义,那么必然会使回归方程对样本的拟合得到显著提高。可通过对数似然比测度拟合程度是否有所提高。
我们通常采用似然比检验统计量
−
l
n
(
L
L
x
i
)
2
−ln(\frac{L}{L_{x_i}})^2
− l n ( L x i L ) 2
L
L
L
x
i
x_i
x i
L
x
i
L_{x_i}
L x i
x
i
x_i
x i
x
i
x_i
x i
p
p
p
l
o
g
i
t
P
logitP
l o g i t P 怎样用SPSS做二项Logistic回归分析?结果如何解释? Wald检验: 似然比检验 比分检验 spss二分类的logistic回归的操作和分析方法 利用R语言+逻辑回归实现自动化运营
逻辑回归系数的显著性检验是检验方程中各变量与
l
o
g
i
t
P
logitP
l o g i t P
x
i
x_i
x i
l
o
g
i
t
P
logitP
l o g i t P
w
i
=
0
w_i=0
w i = 0
来源:2016年07月14日 18:09:35 正确率 TP、FP、FN、TN
误检率: fp rate = sum(fp) / (sum(fp) + sum(tn))
查准率: precision rate = sum(tp) / (sum(tp) + sum(fp))
查全率: recall rate = sum(tp) / (sum(tp) + sum(fn))
漏检率:miss rate = sum(fn) / (sum(tp) + sum(fn))
ROC曲线、AUC Kappa statics Mean absolute error 和 Root mean squared error
Relative absolute error 和 Root relative squared error
当模型的参数过多时,很容易遇到过拟合的问题。而正则化是结构风险最小化的一种实现方式,通过在经验风险上加一个正则化项,来惩罚过大的参数来防止过拟合。
正则化是符合奥卡姆剃刀(Occam’s razor)原理 的:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单的才是最好的模型。
我们来看一下underfitting,fitting跟overfitting的情况:
J
(
w
)
=
>
J
(
w
)
+
λ
∣
∣
w
∣
∣
p
J(w)=>J(w)+λ||w||_p
J ( w ) = > J ( w ) + λ ∣ ∣ w ∣ ∣ p
L1范数: 是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization) 。那么,参数稀疏 有什么好处呢?
一个关键原因在于它能实现 特征的自动选择 。一般来说,大部分特征
x
i
x_i
x i
x
i
x_i
x i
y
i
y_i
y i
L2范数: 它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression)重点内容 ,有人也叫它“权值衰减”(weight decay)。
它的强大之处就是它能 解决过拟合 问题。我们让 L2 范数的规则项$ ||w||_2$ 最小,可以使得 w 的每个元素都很小,都接近于0,但与 L1范数不同,它不会让它等于0,而是接近于0,这里还是有很大区别的。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。咦,你为啥说越小的参数表示的模型越简单呢? 其实我也不知道,我也是猜,可能是因为参数小,对结果的影响就小了吧。
为了更直观看出两者的区别,我再放一张图:
w
1
w^1
w 1
w
2
w^2
w 2
w
1
w^1
w 1
w
2
w^2
w 2
和
右
边
的
圆
形
和右边的圆形
和 右 边 的 圆 形
一句话总结就是:L1 会趋向于产生少量的特征,而其他的特征都是0,而 L2 会选择更多的特征,同时很多特征都会接近于0。
来源:
M
∗
N
M*N
M ∗ N
图3 样本标签向量 & 样本矩阵
如果将样本矩阵按行划分,将样本特征向量分布到不同的计算节点,由各计算节点完成自己所负责样本的点乘与求和计算(比如一个节点分到一个样本,那么它负责计算
e
1
、
e
1
x
11
、
…
、
e
1
x
1
p
e_1、e_1x_{11}、\dots、e_1x_{1p}
e 1 、 e 1 x 1 1 、 … 、 e 1 x 1 p
e
2
、
e
2
x
21
、
…
、
e
2
x
2
p
e_2、e_2x_{21}、\dots、e_2x_{2p}
e 2 、 e 2 x 2 1 、 … 、 e 2 x 2 p
e
1
+
⋯
+
e
n
;
e
1
x
11
+
e
2
x
21
+
⋯
+
e
n
x
n
1
;
…
e_1+\dots+e_n;e_1x_{11}+e_2x_{21}+\dots+e_nx_{n1};\dots
e 1 + ⋯ + e n ; e 1 x 1 1 + e 2 x 2 1 + ⋯ + e n x n 1 ; …
假设所有计算节点排列成m行n列(m*n个计算节点),按行将样本进行划分,每个计算节点分配M/m个样本特征向量和分类标签;按列对特征向量进行切分,每个节点上的特征向量分配N/n维特征。如图4所示,同一样本的特征对应节点的行号相同,不同样本相同维度的特征对应节点的列号相同。
图4 并行LR中的数据分割
一个样本的特征向量被拆分到同一行不同列的节点中,即:
X
r
,
k
=
<
X
(
r
,
1
)
,
k
>
,
…
,
<
X
(
r
,
c
)
,
k
>
,
…
,
<
X
(
r
,
n
)
,
k
>
X_{r,k}=<X_{(r,1),k}>,\dots,<X_{(r,c),k}>,\dots,<X_{(r,n),k}>
X r , k = < X ( r , 1 ) , k > , … , < X ( r , c ) , k > , … , < X ( r , n ) , k >
其中
X
r
,
k
X_{r,k}
X r , k
X
(
r
,
c
)
,
k
X_{(r,c),k}
X ( r , c ) , k
X
r
,
k
X_{r,k}
X r , k
W
c
W_c
W c
W
=
<
W
1
,
…
,
W
c
,
…
,
W
n
>
W=<W_1,\dots,W_c,\dots,W_n>
W = < W 1 , … , W c , … , W n >
观察目标函数的梯度计算公式(公式(2)),其依赖于两个计算结果:特征权重向量
W
t
W_t
W t
X
j
X_j
X j
[
δ
(
y
i
W
t
T
X
j
)
−
1
]
y
i
[\delta(y_iW_t^TX_j)-1]y_i
[ δ ( y i W t T X j ) − 1 ] y i
X
j
X_j
X j
d
(
r
,
c
)
,
k
,
t
=
W
c
,
t
T
X
(
r
,
c
)
,
k
∈
R
d_{(r,c),k,t}=W_{c,t}^{T}X_{(r,c),k}\in R
d ( r , c ) , k , t = W c , t T X ( r , c ) , k ∈ R
k
=
1
,
2
,
…
,
M
/
m
k=1,2,…,M/m
k = 1 , 2 , … , M / m
d
(
r
,
c
)
,
k
,
t
d_{(r,c),k,t}
d ( r , c ) , k , t
W
c
,
t
W_{c,t}
W c , t
图5 点乘结果归并
③ 各节点独立算标量与特征向量相乘:
$G_{(r,c),t}$可以理解为由第r行节点上部分样本计算出的目标函数梯度向量在第c列节点上的分量。
④ 对列号相同的节点进行归并:
G
c
,
t
G_{c,t}
G c , t
G
t
G_t
G t
图6 梯度计算结果归并
综合上述步骤,并行LR的计算流程如图7所示。比较图2和图7,并行LR实际上就是在求解损失函数最优解的过程中,针对寻找损失函数下降方向中的梯度方向计算作了并行化处理,而在利用梯度确定下降方向的过程中也可以采用并行化(如L-BFGS中的两步循环法求牛顿方向)。
图7 并行LR计算流程
利用MPI,分别基于梯度下降法(MPI_GD)和L-BFGS(MPI_L-BFGS)实现并行LR,以Liblinear为基准,比较三种方法的训练效率。Liblinear是一个开源库,其中包括了基于TRON的LR(Liblinear的开发者Chih-Jen Lin于1999年创建了TRON方法,并且在论文中展示单机情况下TRON比L-BFGS效率更高)。由于Liblinear并没有实现并行化(事实上是可以加以改造的),实验在单机上进行,MPI_GD和MPI_L-BFGS均采用10个进程。
实验数据是200万条训练样本,特征向量的维度为2000,正负样本的比例为3:7。采用十折交叉法比较MPI_GD、MPI_L-BFGS以及Liblinear的分类效果。结果如图8所示,三者几乎没有区别。
图8 分类效果对比
将训练数据由10万逐渐增加到200万,比较三种方法的训练耗时,结果如图9,MPI_GD由于收敛速度慢,尽管采用10个进程,单机上的表现依旧弱于Liblinear,基本上都需要30轮左右的迭代才能达到收敛;MPI_L-BFGS则只需要3~5轮迭代即可收敛(与Liblinear接近),虽然每轮迭代需要额外的开销计算牛顿方向,其收敛速度也要远远快于MPI_GD,另外由于采用多进程并行处理,耗时也远低于Liblinear。
图9 训练耗时对比
来源:https://blog.csdn.net/u013719780/article/details/52277616 多分类算法 。
https://blog.csdn.net/cyh_24/article/details/50359055
简单粗暴 的回答是:逻辑回归跟最大熵模型没有本质区别。逻辑回归是最大熵对应类别为二类时的特殊情况,也就是当逻辑回归类别扩展到多类别时,就是最大熵模型。
最大熵模型是约束条件下的熵最大化,可以通过拉格朗日乘子进行推导。可得到最大似然的形式。
scikit-learn 逻辑回归类库使用小结
来源:https://blog.csdn.net/han_xiaoyang/article/details/49797143
其他参考资料:
深入解读Logistic回归结果(一):回归系数,OR
逻辑回归的前世今生 Logistic Regression 的前世今生(理论篇)
《Logistic Regression 模型简介》,来源:FIN ·2015-05-08 10:00 Python实现逻辑回归(Logistic Regression in Python)