Abstract
FlowNet算法证明了光流计算可以被转换为学习问题。在小位移以及现实场景之下,flownet还无法与传统方法比较。 本文提出了3点改进:在训练的不同阶段使用不同的训练集是重要的。第二:提出了warp操作,使用中间预测出来的粗光流应用于第二张图片之上。第三:使用一个子模块专门处理小位移。
Introduction
由Dosovitskiy et al.(A. Dosovitskiy, P. Fischer, E. Ilg, P. Häusser, C. Hazırba¸s,V. Golkov, P. v.d. Smagt, D. Cremers, and T. Brox. Flownet:Learning optical flow with convolutional networks.)等人设计的FlowNet使得对于光流的计算有了一种全新的思路:即使用简单的卷积神经网络(CNN)体系结构直接从数据中学习光流概念,这一想法与所有已建立的变分法完全不同。FlowNet2.0是对现有的flownet模型的巩固与提升。flownet2.0继承了原始flownet的优点,如:匹配大位移,对于光流场细节的把控,能学习特定场景的先验知识等。与此同时,解决了原始flownet中小位移、多伪影(noisy artifacts)的复杂情况。在堆叠多个网络的同时使用变形操作可以有效改善网络的性能。创建了一份新的数据集与一个特定的网络,使用此数据训练的网络能够有效处理小位移情况,在最后,创建一个网络,这个网络的功能为融合处理小位移的网络与之前的网络。
Related Work
FLownet之后也有很多论文使用cnn预测光流,然后并没有达到flownet的精度。还有一种替代选择就是使用块匹配,能达到良好的精度,但是需要exhaustive matching of patches,并且速度非常慢,且基于小块的方法存在固有的不足:无法使用整张图片的信息。
用来预测像素级任务的cnn通常会产生噪声以及模糊现象。可以通过现成的方法来优化CNN网络的预测(对于光流预测来说,可以使用变分法来优化)。warp层的作用为:补偿在第二幅图像中已经估计到的一些初步运动,在Lucas & Kanade的(An iterative image registration technique with an application to stereo vision.)中首次提出,并广泛应用于各种变分光流计算中。
将机器学习模型训练成一系列逐渐增加的任务的策略称为课程学习(Curriculum learning论文)。
Dataset Schedules
最初的FlowNets是在flyingchair数据集上训练的(我们称之为chair)。这个相当简单的数据集包含了大约22k张椅子的图像对,它们叠加在Flickr上的随机背景图像上。将随机仿射变换应用于椅子和背景,得到第二幅图像和地面真实流场。数据集只包含平面运动。
flyingthing3d(A large dataset to trainconvolutional networks for disparity, optical flow, and scene Flow estimation.)可以想象成3D版本的椅子,与椅子相比,这些图像显示了真实的3D运动和灯光效果,而且物体模型的多样性也更多。
使用椅子训练再用things3D微调的网络效果最好,我们推测,更简单的椅数据集可以帮助网络学习颜色匹配的一般概念,而不会过早地开发出3D运动和现实照明的混淆先验知识。只单单使用这种策略,就可以使得flownets提高25%,flownetc提高30%。
Stacking Networks
Stacking Two Networks for Flow Refinement
在堆叠结构中,第一层的输入为图片的第一帧与第二帧,
,输出光流
。第二层中的输入为
,
,
。为了使得评价之前的误差以及计算增量更新变得更为容易,通过对
进行变形得到
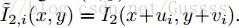
的同时使用的双线性插值)
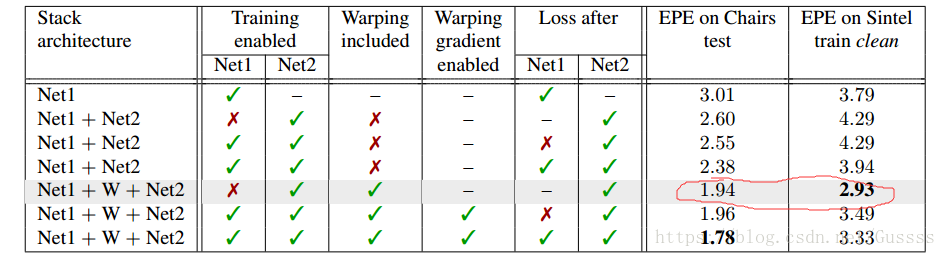
经过实验如下图,固定住net1的权重,随机初始化net2的值,然后使用策略,使用椅子数据集来训练net2可以得到最好的效果。

Stacking Multiple Diverse Networks
我们进行了这个实验,发现多次使用相同权重的网络堆叠并对这个重复部分进行微调并不能改善结果
堆叠的时候,因为flownet的Siamese structure比较难处理,所以只把flownet放在第一层。
每一个新的网络都是先固定住之前的网络,在用在椅子上训练,然后用
(椅子->Things3D)。发现CSS效果最好
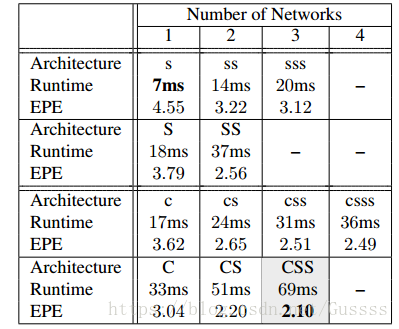
并且可以使通道数下降,以使得 速度与精度之间取折中。
Small Displacements
5.1. Datasets
UCF101数据集中的运动通常小于一个像素点,因此我们创建一个数据集,就是椅子数据集的风格,但是里面包含的运动都是小位移的运动,运动直方图也与UCF101非常类似,把这种数据集称为ChairsSDHom。
5.2. Small Displacement Network and Fusion
在FlowNet-CSS上微调网络(具体情况为在整个网络结构上使用Things3D与ChairsSDHom的混合数据集训练,并对误差应用非线性以降低大位移的比例)为了使得网络能够处理小位移情况。发现提升了处理小位移的效果,但是没有降低大位移下的表现。此网络称为FlowNet2-CSS-ft-sd
然而,在subpixel运动的情况下,噪声仍然是一个问题,我们推测出flownet不擅长处理这种问题。为了解决这个问题,对flownets进行一些小小的改动,把第一层的stride=2去除,并把初始的7x7,5x5滤波器改为多个3x3滤波器,使得网络更深。因为对于小位移来说,噪声会称为一个大问题,所以在 upconvolutions层中添加了卷积操作来获得更平滑的光流估计。此网络称为FlowNet2-SD;
最后创建一个网络把FlowNet2-CSS-ft-sd与FlowNet2-SD融合,这个网络接受the flows, the flow magnitudes and the errors in brightness after warping as input.这个融合层先把分辨率降低两倍,然后提升至全分辨率。最后发现可以产生清晰的运动边界,小位移以及大位移同样出色。