本文主要使用python来实现七个经典的排序算法,分别是:冒泡排序、选择排序,插入排序,快速排序,希尔排序,堆排序和归并排序。
一、相关归纳总结
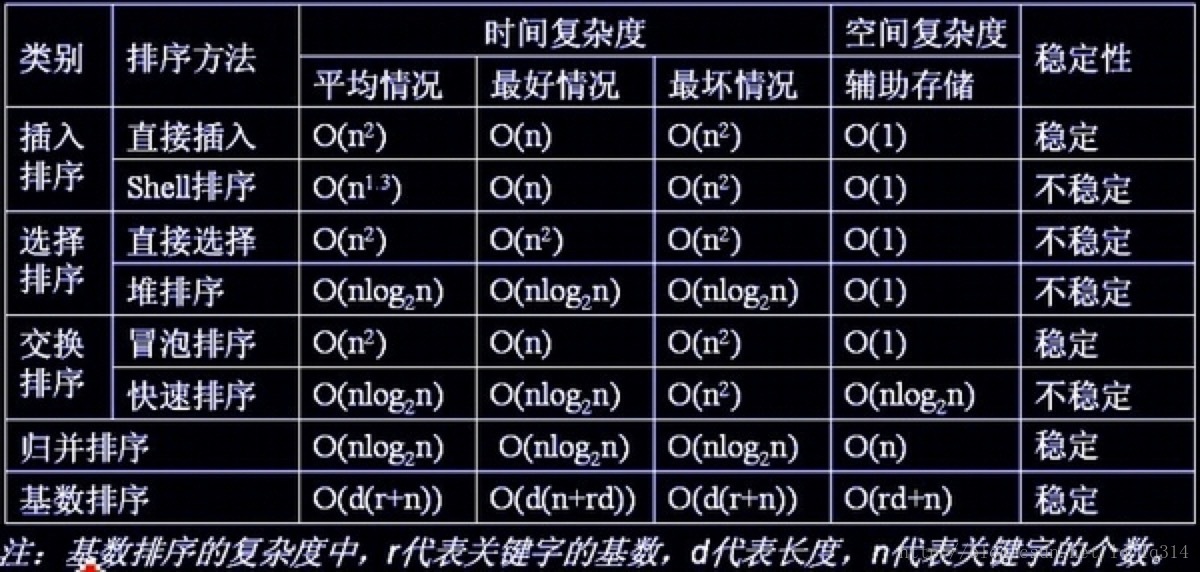
1、时间复杂度
O(N^2): 冒泡排序、选择排序,插入排序
O(N*logN): 快速排序,希尔排序,堆排序和归并排序
2、空间复杂度
O(1):插入排序,冒泡排序,选择排序,堆排序,希尔排序
O(logN)~O(N):快速排序
O(N):归并排序
3、稳定性:若待排序的序列中,存在多个相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的;若经过排序后,记录的相对次序发生了改变,则称该算法是不稳定的。
稳定的:冒泡排序,插入排序、归并排序和基数排序
不稳定的:选择排序,快速排序,希尔排序,堆排序
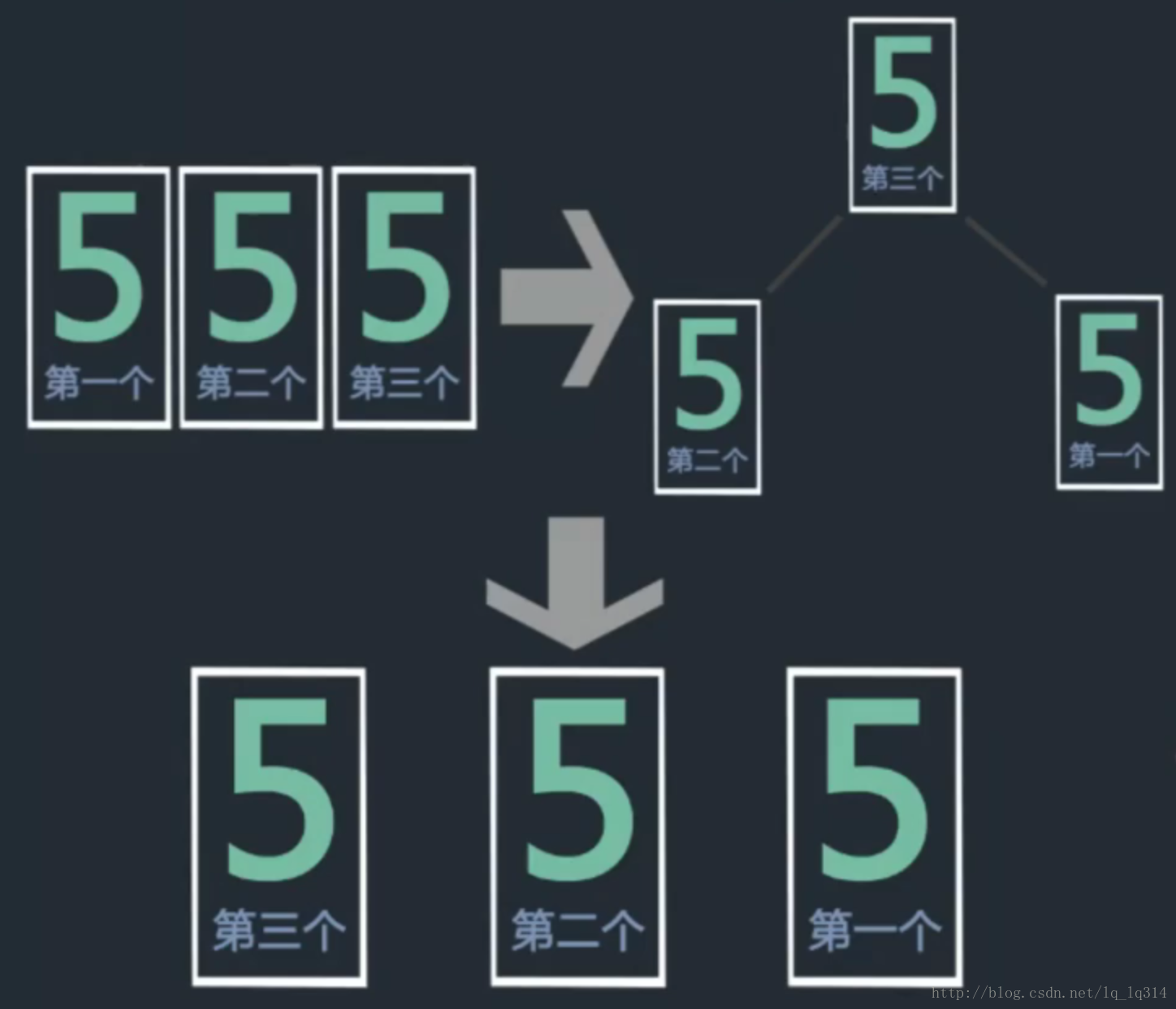
不稳定举例说明:
选择排序:


快速排序:
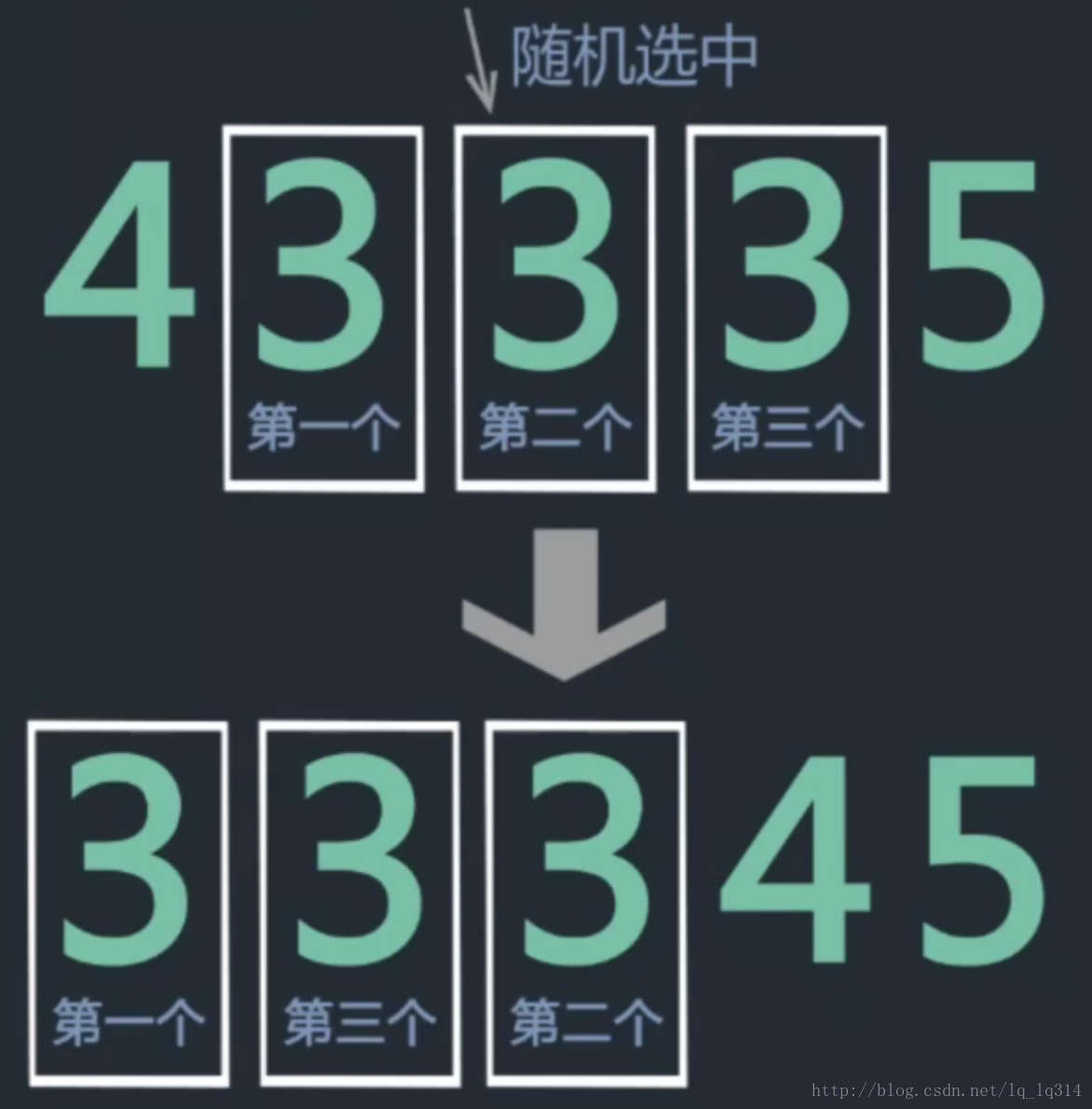
希尔排序:
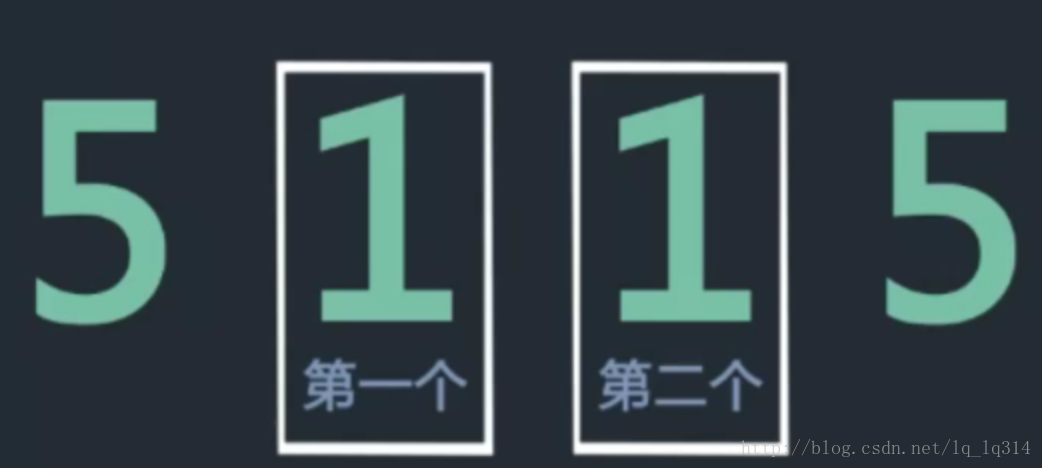

堆排序:
4、使用场景:
设待排序的元素个数为n:
当n较大,则应采用时间复杂度为O(NlogN)的排序算法:快速排序,堆排序或者归并排序
- 快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短。
- 堆排序:如果内存空间允许
- 归并排序:内存空间允许,且要求稳定性
当n较小,可采用直接插入和选择排序
- 直接插入排序:当元素分布有序,且要求稳定性(优先)
- 选择排序:当元素分布有序,且不要求稳定性
一般不使用或不直接使用传统的冒泡排序。
二、算法实现
1、冒泡排序:
基本思想:
假设待排序表长为n,从前往后(或从后往前)两两比较相邻元素的值,若为逆序(即A[i]>A[i+1]),则交换他们,直到序列比较完。我们称它为一趟冒泡,会将最大的元素交换到待排序的最后一个位置。下一趟冒泡时,前一趟确定的最大元素不再参加比较,待排序列减少一个元素,每趟冒泡的结果把序列中的最大元素方法了序列的最终位置。这样最多做n-1趟冒泡就能把左右的元素排好序。
实现代码:
def bubble_sort(list):
for i in range(len(list)-1):
for j in range(len(list)-i-1):
if list[j]>list[j+1]:
list[j+1],list[j] = list[j],list[j+1]
return list基本思想:
每一趟(例如第i趟)在后面n-i+1(i=1,2,...,n-1)个待排序元素中选取关键字最小的元素,作为有序子序列的第i个元素,直到n-1趟做完,就不用再选了。
实现代码
def select_sort(list):
for i in range(len(list)-1):
min = i
for j in range(i+1,len(list)):
if list[j]<list[min]:
min = j
list[i],list[min] = list[min],list[i]
return list基本思想:
将一个记录插入到一排序好的有序表中,从而得到一个新的,记录数增1的有序表。即:现将序列的第一个记录看成是一个有序的子序列,然后从第二个记录进行插入,直至整个序列有序为止。
实现代码:
def insert_sort(list):
for i in range(1,len(list)):
key = list[i]
for j in range(i-1,-1,-1):
if list[j]>key:
list[j+1] = list[j]
list[j] = key
return list基本思想:
- 选择一个基准元素,通常选择第一个元素或者最后一个元素
- 通过一趟排序将待排序的记录分割成独立的两部分,其中一部分的记录值均比基准元素小,另一部分元素值均比基准元素大
- 此时基准元素在其排好序后的正确位置
- 然后分别堆这两部分用同样的方法继续进行排序,直到整个序列有序
实现代码:
def quick_sort(list,left,right):
if left<right:
mid = partition(list,left,right)
quick_sort(list,0,mid-1)
quick_sort(list,mid+1,right)
return list
def partition(list,left,right):
temp = list[left]
while left<right:
while left<right and list[right]>=temp:
right -= 1
list[left] = list[right]
while left<right and list[left]<=temp:
left += 1
list[right] = list[left]
list[left] = temp
return left5、希尔排序
希尔排序也叫缩小增量排序
基本思想:
- 首先取一个正数d1 = n/2,将元素分为d1个组,每组相邻元素之间的距离为d1,在各组内进行直接插入排序
- 取第二个正数d2 = d1 / 2,重复上述分组排序过程,直到di = 1,即所有的元素都在同一组进行直接插入排序。
- 希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序,最后一趟排序使得所有数据有序
实现代码:
def shell_sort(list):
#dk为步长
dk = len(list)/2
while dk>=1:
for i in range(dk,len(list)):
temp = list[i]
j = i-dk
while j>=0 and temp<list[j]:
list[j+dk] = list[j]
j -= dk
list[j+dk] = temp
dk = dk/2
return list6、堆排序
堆排序是一种树形选择排序方法
基本思想
- 建立堆
- 得到堆顶元素,为最大元素
- 去掉堆顶元素,将堆最后一个元素放到堆顶,此时可通过一次调整重新使堆有序
- 堆顶元素为第二大元素
- 重复步骤3,直到堆变空
实现代码:
#堆排序
def heap_sort(list):
#初始建堆
build_max_heap(list,len(list))
#n-1趟的交换和建堆过程
for i in range(1,len(list))[::-1]:
#将堆顶元素list[0]和最后一个元素list[i]交换
list[i],list[0] = list[0],list[i]
#把剩余的i-1个元素整理成堆
adjust_down(list,0,i)
return list
#创建堆
# n个节点的完全二叉树,最后一个节点是第n/2个节点的孩子。
#对于大根堆,若根节点的关键字小于左右子女中关键字较大者,则交换,使该子树成为堆。
#之后向前依次对各节点((size/2)-1~1)为根的子树进行筛选。
def build_max_heap(list,size):
#从size/2~1,反复调整堆。
for i in range(0,size/2)[::-1]:
adjust_down(list,i,size)
#调整堆
def adjust_down(list,i,size):
max= i
lchild = 2*i + 1
rchild = 2*i + 2
if rchild < size :
if lchild < size and list[lchild] > list[max]:
max = lchild
if rchild < size and list[rchild] > list[max]:
max = rchild
if max!= i:
list[max],list[i] = list[i],list[max]
#继续向下调整堆
adjust_down(list,max,size)7、归并排序
基本思想:
归并排序是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列
图例:
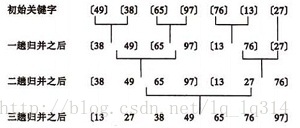
实现代码:
def merge_sort(list):
if len(list)<=1:
return list
mid = len(list)/2
left = merge_sort(list[:mid])
right = merge_sort(list[mid:])
return merge(left,right)
def merge(left,right):
i,j = 0,0
#新建一个数组,用来存储将left和right排好序的值
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result