0、Spark MLlib介绍
机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足够收敛才会停止,迭代时如果使用Hadoop的MapReduce计算框架,每次计算都要读/写磁盘以及任务的启动等工作,这回导致非常大的I/O和CPU消耗。而Spark基于内存的计算模型天生就擅长迭代计算,多个步骤计算直接在内存中完成,只有在必要时才会操作磁盘和网络,所以说Spark正是机器学习的理想的平台。
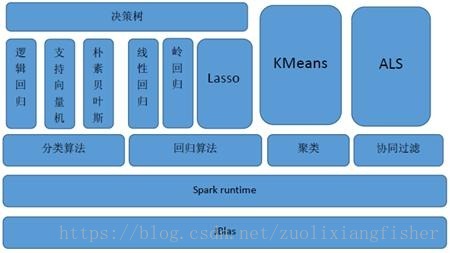
MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。Spark的设计初衷就是为了支持一些迭代的Job, 这正好符合很多机器学习算法的特点。MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤,MLlib在Spark整个生态系统中的位置如图下图所示。
注:本人才疏学浅,一边学习一边整理这些算法,部分内容是李航老师《统计学习方法》的原内容摘录,部分是自己的理解实践笔记,如有错误请不吝指正,谢谢!
朴素贝叶斯法(NaiveBayes)是基于贝叶斯定理和特征条件独立假设的分类方法,对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布,然后基于此模型,对给定的输入 , 利用贝叶斯定理求出后验概率最大的预测值 ,它属于生成模型
1、朴素贝叶斯法的学习与分类
1.1 基本方法
设输入空间 为 维向量的集合,输出空间为类标记集合 输入为特征向量 ,输出为类标记 , 是 和 的联合概率分布. 训练数据集
由 独立同分布产生。
朴素贝叶斯法通过训练数据学习先验概率分布 以及条件概率分布
我们可以看到,对于条件概率分布 ,它的参数是指数级的,比如假设 的取值有 个, , 的取值有 个,那么所求的参数就有 ,实际是不可行的。鉴于此,为了可以求解参数,朴素贝叶斯法对条件概率分布做了条件独立假设。因为这是一个较强的假设,朴素贝叶斯(Naive Bayes) 也因此得名。
朴素贝叶斯条件独立假设是指用于分类的特征在类确定的条件下都是条件独立的,这一假设使朴素贝叶斯法变得简单,不过有时会需要牺牲一定的分类准确率。
在分类的时候,对于给定的输入
,通过学习到的模型计算后验概率分布
,并将后验概率最大的类作为
的类输出,根据贝叶斯定理,我们计算后验概率:
将(1)式代入
因此,朴素贝叶斯分类器可以表示为:
由于上式分母对于所有的
都是一样的,所以分类器可以简化表示为:
1.2 后验概率最大化的含义
朴素贝叶斯法将样本分到后验概率最大的类别里,这等价于期望风险最小化
假设选中0-1损失函数
上式中
是分类决策函数,这时风险函数为:
期望是对连个分布 取的,由此取条件期望
为了使期望风险最小化,只需对 逐个极小化,由此得到:
由此根据期望最小化准则就得到了后验概率最大化准则
以上就是朴素贝叶斯法采取的原理
2、参数估计
2.1 极大似然估计
在朴素贝叶斯法里,学习就是估计
和
,可以应用极大似然估计法估计相应的概率,先验概率
的极大似然估计是
设第 个特征 可能取值的集合为 ,条件概率
的极大似然估计是
其中 , 是第 个样本的第 个特征, 是第 个特征可能取的第 个值; 为示性函数。
2.2 学习与分类算法
2.2.1 朴素贝叶斯算法
输入: 训练数据 ,其中 , 是第 个特征的第 个样本。 , 是第 个特征的第 个值,
输出: 样本 的分类
(1) 计算先验概率和条件概率:
(2) 对于给定的实例
,计算
(3) 确定
的分类

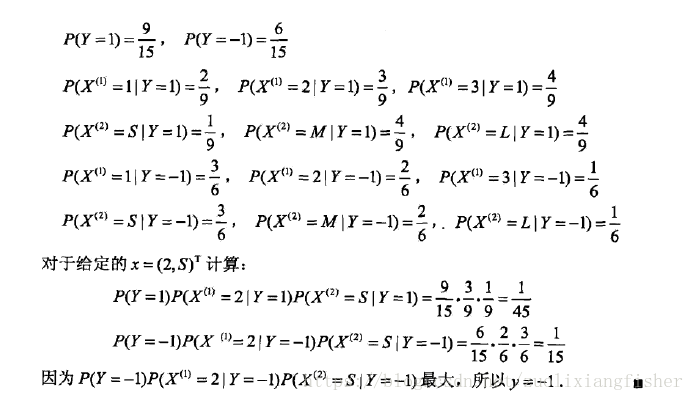
2.3 贝叶斯估计
用极大似然估计可能会出现所要估计的概率值为0的情况,这回影响后验概率的计算,使分类结果产生偏差,我们可以用贝叶斯估计来解决这个问题。
上式就是在随机变量各个取值的频数上加上一个正数
,当
时就是极大似然估计,一般
, 这时称为拉普拉斯平滑。此时,先验概率的贝叶斯估计是
3、spark MLlib实战练习
朴素贝叶斯算法在python和spark机器学习库中均有封装,我用的是spark mllib里的NaiveBayes模型。
当时用朴素贝叶斯做资讯文章分类,50w篇训练样本,20个大类,第一版整体的准确率在82%左右,召回在78%,后面因某些原因没有继续优化~
附上核心代码,scala入门较浅,写得比较粗糙,欢迎各位大神指导~~
/** NaiveBayes 多分类训练 */
private def NaiveBayesMultiClassifier(sc: SparkContext, params: Params) = {
import org.apache.spark.mllib.classification.{NaiveBayes, NaiveBayesModel}
import NaiveBayes.{Bernoulli, Multinomial}
/** load data in libsvm format */
val data = MLUtils.loadLibSVMFileNew(sc, params.inputPath)
/** split data into training and test part with ratio of 0.2:0.8 */
val splits = data.randomSplit(Array(0.8, 0.2))
val (training, test) = (splits(0), splits(1))
val model = NaiveBayes.train(training, lambda = 1.0, modelType = "multinomial")
/**
* Save model parameters to hdfs, including Pi,Theta
*/
val resultTheta = ArrayBuffer[String]()
for(i <- model.theta.indices){
val ll = model.labels(i)
for(j <- model.theta(i).indices){
val theta = model.theta(i)(j)
resultTheta.append(ll.toString + "|" + j.toString + "|" + theta)
}
}
sc.parallelize(resultTheta).saveAsTextFile(getModelPath(sc,"hdfs://10.240.131.10:9000/data/info/model/naivebayes/theta/20171112/"))
/** check the output pi is match the correct label */
/**
println("The length of Label is : " + model.labels.length)
for(i<- model.labels.indices){
println("The " + i.toString + "th of label is : " + model.labels(i).toString )
} */
val resultPi = ArrayBuffer[String]()
for(i <- model.pi.indices) {
val ll = model.labels(i)
val ss = model.pi(i)
resultPi.append(ll.toString + "|" + ss.toString)
}
sc.parallelize(resultPi).saveAsTextFile(getModelPath(sc,"hdfs://10.240.131.10:9000/data/info/model/naivebayes/pi/20171112/"))
val trainAndLabel = training.map{p => (model.predict(p.features), p.label)}
/** total training accuracy of model */
val trainingAccuracy = 1.0 * trainAndLabel.filter(x => x._1 == x._2).count() / training.count()
/** accuracy of each class */
val trainingClassNum = trainAndLabel.map{x =>
if (x._1.toDouble ==x._2) (x._2.toString,(1,1))
else (x._2.toString, (1,0))
}
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.map{case (key,(num, rightNum))=>
(key, rightNum, num, rightNum.toDouble/num.toDouble)
}
trainingClassNum.collect().foreach{ line =>
println(s"Training result: the class of ${line._1} has total ${line._3} items, and ${line._2} been right classified, the accuracy is ${line._4} ")
}
logger.info(s"The total training accuracy of Multinomial Model of NaiveBayes is : ${trainingAccuracy}")
val predictAndLabel = test.map{p => (model.predict(p.features), p.label)}
/** total test accuracy of model */
val testAccuracy = 1.0 * predictAndLabel.filter(x => x._1==x._2).count() / test.count()
/** each class accuracy */
val testClassNum = predictAndLabel.map{x =>
if (x._1==x._2) (x._2.toString,(1,1))
else (x._2.toString, (1,0))
}
.reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.map{case (key,(num, rightNum))=>
(key, rightNum, num, rightNum.toDouble/num.toDouble)
}
// here can't use .map{line => } ,there is nothing print
testClassNum.collect().foreach{ line =>
println(s"Test result: the class of ${line._1} has total ${line._3} items, and ${line._2} been right classified, the accuracy is ${line._4}")
}
logger.info(s"The total test accuracy of Multinomial Model of NaiveBayes is : {$testAccuracy}")
/** save model to special path */
model.save(sc, getModelPath(sc,params.saveModelPath))
}训练方法里导入数据的 loadLibSVMFileNew 方法是重写了原生的 loadLibSVM方法
/** NaiveBayes 多分类预测 */
private def NaiveBayesPredict(sc: SparkContext, params: Params) = {
// load model
val model = NaiveBayesModel.load(sc, params.saveModelPath)
println("<------- Model parameter ------->")
println(model.toString())
val numFeatures = model.theta(0).length
// load predict data,last parameter is the number of features in model
val data = MLUtils.loadLibSVMFileWithItem(sc, params.inputPath, numFeatures)
val predictResult = data.map { case (LabeledPoint(label, features), itemid) =>
try{
val prediction = model.predict(features)
(itemid, label, prediction)
}catch {
case e: IndexOutOfBoundsException =>
logger.error(e.getLocalizedMessage,e)
("0", 0.0, 0.0)
}
}
// val outputPath = "hdfs://10.240.131.10:9000/data/info/model/naivebayes/result/20170908/"
// val outputPath = "hdfs://10.49.136.150:9000/user/hive/warehouse/u_wsd.db/t_md_info_ctr_file/ds=%YYYYMMDD%"
predictResult.map{case (itemid, label, prediction) =>
itemid + "|" + prediction + "|" + label
}
.saveAsTextFile(getModelPath(sc, params.predictResultPath))
// the accuracy of each class in prediction
val predAndTrue = predictResult.map{ x =>
if(x._2.toDouble == x._3.toDouble) (x._2.toString, (1,1))
else (x._2.toString, (1,0))
}
.reduceByKey((x,y) => (x._1 + y._1,x._2 + y._2))
.map{case (key, (num ,rightNum)) =>
(key, num, rightNum, rightNum.toDouble/num.toDouble)
}
predAndTrue.collect().foreach{x => println(s"""Prediction: the class of ${x._1} has total ${x._2} items, and ${x._3} been classified correctly, ${x._4} !""")}
}参考资料:
1、李航《统计学习方法》
2、http://spark.apache.org/docs/latest/