版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/yeyustudy/article/details/82353144
训练与调优
激活函数
1、sigmoid函数不再适用的原因:1)在某些情况下梯度会消失,不利于反向传播,例如,当输如的值过大或过小时,根据函数的图像,返回的梯度都会是0,阻断了梯度的反向传播。2)不是以0为中心,梯度更新低效
2、tanh函数:第二个问题可以避免,但第一个避免不了
3、relu:又快又简单,最接近神经元的工作过程,但仍有缺点,例如不以0为中心,负半轴容易出现梯度的消失
4、leaky relu:
prelu:
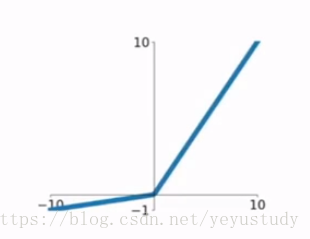
这样可以消除梯度消失的影响。
5、erelu:
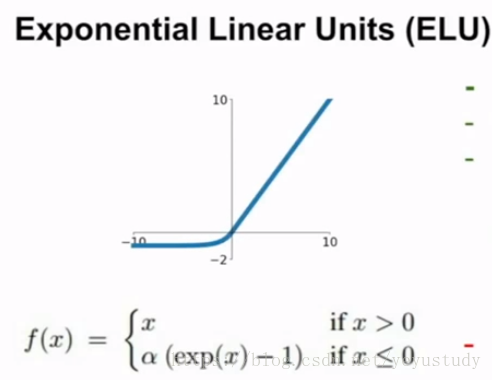
6、maxout neural:
会避免前面许多缺点,但参数加倍
数据预处理
1、在图像处理中,我们一般会做零均值化,但一般不会做归一化,这跟大多数的机器学习问题不同,不需要将所有的特征都投影到相同的范围内,在图像中,我们还是想针对图像本身进行操作。
优化算法
1、SGD:当在某些方向梯度变化敏感,某些方向不敏感,梯度可能在敏感的方向做之字形运动,如下:
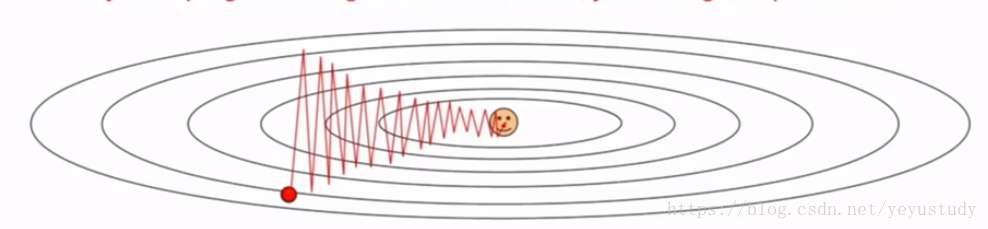
这在高维上可能会更加敏感;而且,SGD容易卡在鞍点。
2、Nesterov momentum:

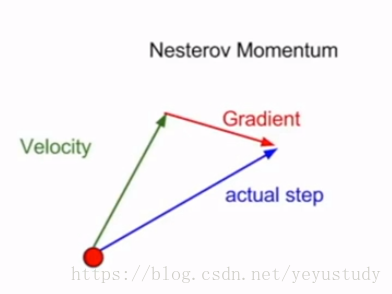
由于这种形式不能同时计算梯度跟损失,故进行改写为:
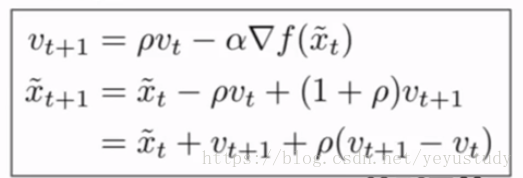
3、adagrad:每一步都累加梯度的平方,更新参数时再除以这个平方的开方
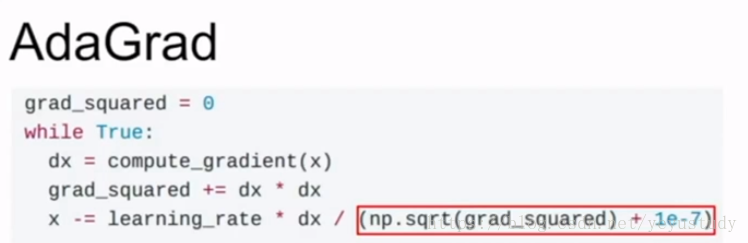
但随着训练的进行,步长会越来越小,因此出现了其改进:

Adam算法进一步综合了二者的优点,一般也是现在默认的算法
正则化
1、dropconnect:不是随机将激活函数置零,而是随机将部分权值置零。
2、随机最大池化:在池化过程中,随机进行区域池化(不常用,也不太懂)
3、随机深度:训练时随机丢掉部分层,测试时使用全部层(不常用)