说到mysql的引擎就必须要提一下B+树了。
计算机有一个局部性原理,就是说,当一个数据被用到时,其附近的数据也通常会马上被使用。
所以当你用红黑树的时候,你一次只能得到一个键值的信息,而用B树,可以得到最多M-1个键值的信息。这样来说B树当然更好了。
B+树是在B树基础上提出的,相比于B树能够更加方便的遍历。B+树简单的说就是变成了一个索引一样的东西。 B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),B+树的性能相当于是给叶子节点做一次二分查找。
B+树只有叶子节点存的是Key-value,非叶子节点只需要存储key就好了。
B+树的查找算法:当B+树进行查找的时候,你首先一定需要记住,就是B+树的非叶子节点中并不储存节点,只存一个键值方便后续的操作,所以非叶子节点就是索引部分,所有的叶子节点是在同一层上,包含了全部的关键值和对应数据所在的地址指针。这样其实,进行 B+树的查找的时候,只需要在叶子节点中进行查找就可以了。
1.MyISAM
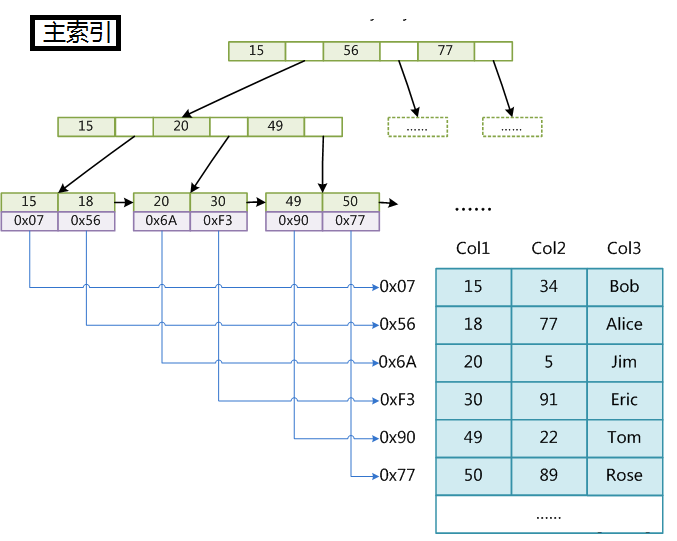
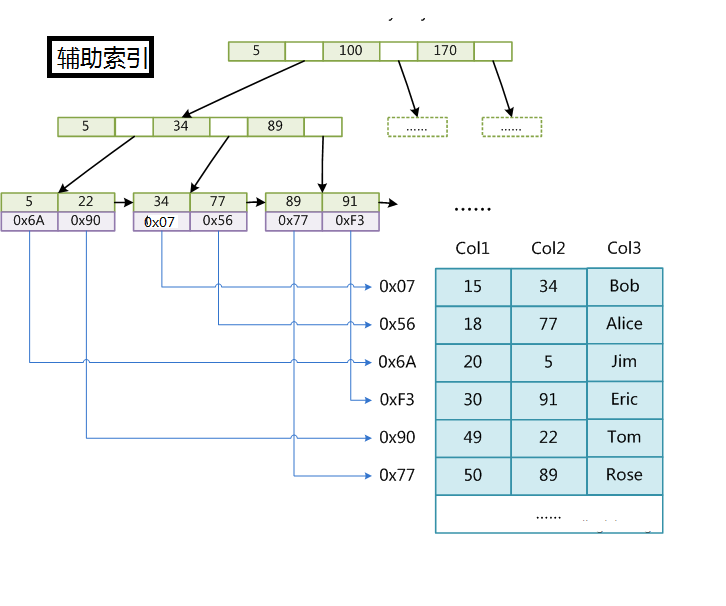
MyISAM中有两种索引,分别是主索引和辅助索引,在这里面的主索引使用具有唯一性的键值进行创建,而辅助索引中键值可以是相同的。MyISAM分别会存一个索引文件和数据文件。它的主索引是非聚集索引。当我们查询的时候我们找到叶子节点中保存的地址,然后通过地址我们找到所对应的信息。myisam索引与数据没有存储在一起,属于非聚集索引。
2.InnoDB
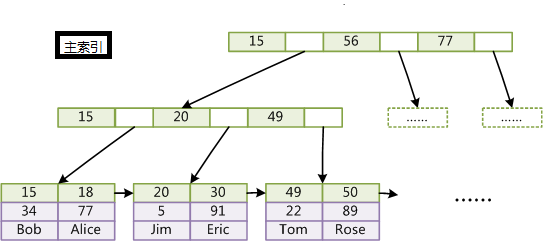
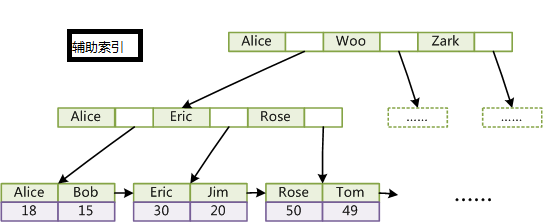
innodb的索引存储图中,我们会发现,叶子节点下面直接存储有数据,而次索引下存储的是主键的id。通过主键查找数据的时候,就会很快查找到数据,但是通过次索引查找数据的时候,需要先查找到对应的主键id,然后才能查找到对应的数据,属于聚集索引。
聚蔟索引与非聚蔟索引:
聚蔟索引相当于汉语字典正文,索引就是拼音,从a到z按顺序排列,数据就是字也按照从a到z的顺序排列。索引顺序与数据顺序排列一致。
非聚蔟索引相当于偏旁部首,最终偏旁部首索引项的数结构存放的是目录,也就是数据的物理地址,而且偏旁部首索引顺序与数据的索引顺序不一致,没有关系。
区别:
1、myisam不支持事务,innodb支持,innodb有外键,myisam支持全文索引,查询效率更高。myisam只有表锁,innodb支持行锁。
2、InnoDB索引和MyISAM最大的区别是它只有一个数据文件,在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点数据域保存了完整的数据记录。所以我们又把它的主索引叫做聚集索引。而它的辅助索引和MyISAM也会有所不同,它的辅助索引都是将主键作为数据域。所以,这样当我们查找的时候通过辅助索引要先找到主键,然后通过主索引再找到对于的主键,得到信息。