第一部分:ES简介
1.首先理解Lucene是什么?
Lucene是一个全文搜索的框架,就像个jar,暴露出很多的接口和方法供开发者使用,是一项技术。而不是应用产品。因此它并不像http://www.baidu.com/ 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
2.lucene能做什么 ?
本质就是给搜索内容定位
ES就是在Lucene基础上的封装。
第二部分:ES搭建
规划节点:node01、node02、node03
一、新建普通用户
useradd chen
echo “XXX” | passwd –stdin chen
二、新建es文件夹
别忘了转换文件夹的权限:
chown jw: /opt/sxt/es
三、上传es安装包到es文件夹并unzip解压
注意必须是jw的普通用户下解压。
unzip elasticsearch-2.2.1.zip
四、修改配置
vim config/elasticsearch.yml
cluster.name: bjsxt-es
node.name: node01
network.host: 192.168.159.36
// 集群的发现方式配置
添加防脑裂配置: 如果不配不知道具体数量,不好控制脑裂
discovery.zen.ping.multicast.enabled: false #不使用广播这种慢发现方式,之所以慢,主要如果还不写出具体节点,只用广播的方式,是在超时间内,达到了就只认为就这么多节点。开始选主。这样慢发方式在这并不好,所以屏蔽掉
discovery.zen.ping.unicast.hosts: [“192.168.133.6”,”192.168.133.7”, “192.168.133.8”] #规定集群这样节点启动后会尝试和其他节点通信,这样就避免了广播的无目标的方式
discovery.zen.ping_timeout: 120s # 超时时间
client.transport.ping_timeout: 60s #客户端超市时间
备:es的主从,在节点之间通信的时候,比如健康检查、切片、分发等,会临时选出一个主,类似zookeeper选主一样。但是在客户端查询的时候是无主的模型。
五、ES插件支持
Head插件,由于ES开发的时候使用的Rest风格的。走的数据交互基本都是json格式的。既,通过rest方式请求的时候返的都是json字符串。所以Head插件提供了转换json字符串的界面。
下载文件目录。
./bin/plugin install mobz/elasticsearch-head
下载完成后多出plugins目录,里面的head目录就是需要的目录文件。
六、分发es文件夹到其他节点
然后分别修改其他节点的hostname以及地址。
七、分别启动es
./elasticsearch #注意以普通用户登录启动
八、测试访问
http://node01:9200 #看到的是json格式的界面
http://node01:9200/_plugin/head/ #带head的UI界面
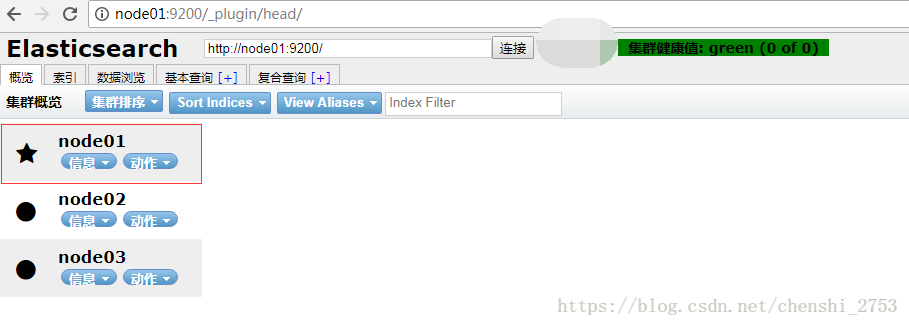
node01是master。
第三部分:ES的CURL
首先看下CURL命令规范:
简单认为是可以在命令行下访问url的一个工具
curl是利用URL语法在命令行方式下工作的开源文件传输工具,使用curl可以简单实现常见的get/post请求。
curl
-X 指定http请求的方法
HEAD GET POST PUT DELETE
-d 指定要传输的数据
创建索引库:
curl -XPUT http://192.168.159.36:9200/jw/ #curl的作用就是发送http协议的数据包到36上。
此时在UI界面上刷新查看。
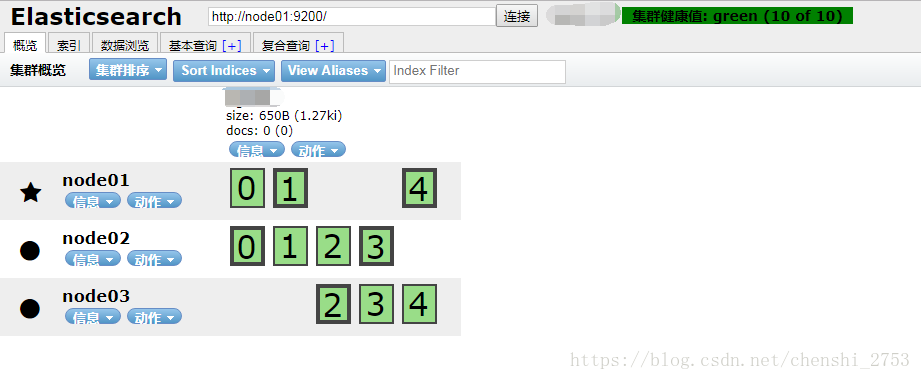
副本数怎么看? 看边框,粗的为主,细的副本。所以副本数为1。模数为5.(5个Lucene片)
此时把主节点干掉,停止node01的服务。再从node02上查看UI页面,经过一会的时间,连接情况如下,
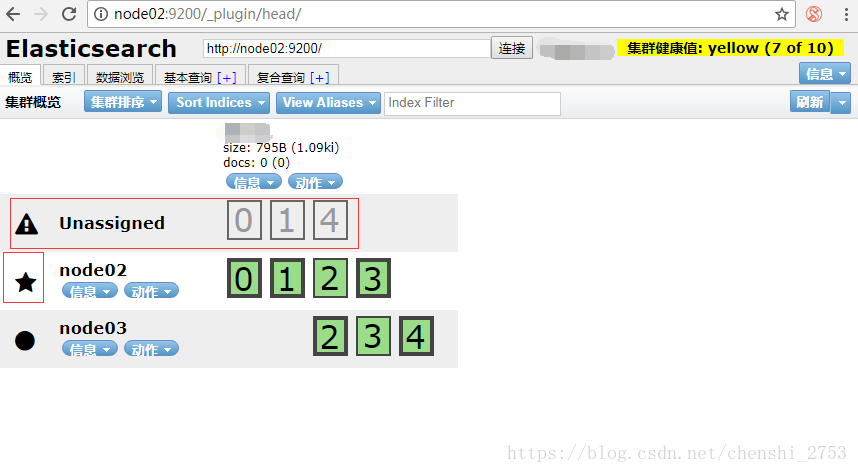
会重新选出主为node02,同时显示异常的情况。显示灰色的对应的数字都是主。
再经过一段时间会恢复正常,如下图
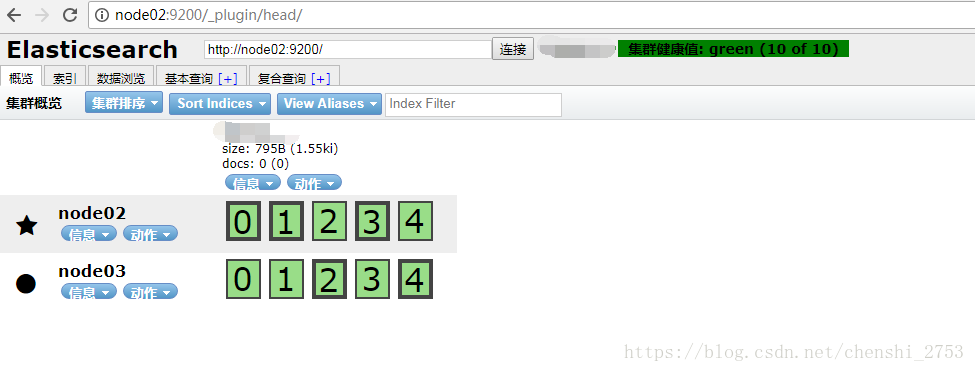
可以看出总的Lucene片不变。
如果再恢复node01的服务,最后会重新选主。
//创建document:
curl -XPOST http://192.168.159.36:9200/jw/employee -d ’
{
“first_name” : “bin”,
“last_name” : “tang”,
“age” : 33,
“about” : “I love to go rock climbing”,
“interests”: [ “sports”, “music” ]
}’
在UI页面上点击“数据浏览”
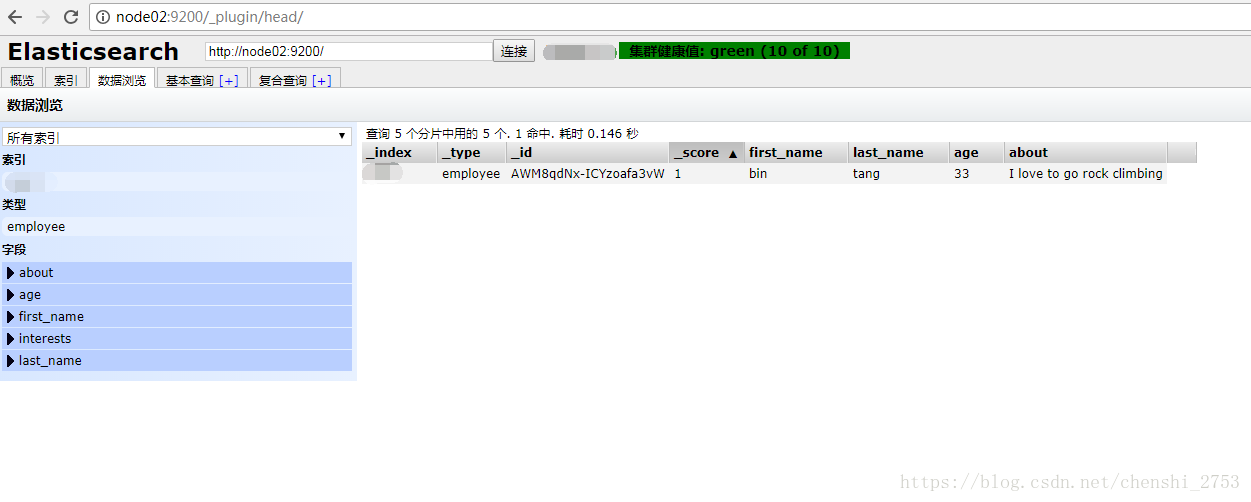
对document扩展,比如新增爱好、年龄等属性
curl -XPOST http://192.168.159.36:9200/jw/employee -d ’
{
“first_name” : “bin”,
“last_name” : “tang”,
“age” : 33,
“about” : “I love to go rock climbing”,
“interests”: [ “sports”, “music” ],
“hobby”:”play basketball”,
“age”:”26”
}’
然后点击F5页面刷新,不要点UI自己的刷新按钮。不生效的。

//更新document:
curl -XPUT http://192.168.159.36:9200/jw/employee/1 -d ’
{
“first_name” : “bin”,
“last_name” : “pang”,
“age” : 30,
“about” : “I love to go rock climbing”,
“interests”: [ “sports”, “music” ]
}’
区别POST和PUT。
PUT需要给出库和Id,而POST只需要给出库即可。
就PUT而言,多次推送,如果id相同则更新,反之插入。对更新而言,并没有直接的删掉多余项目,只是暂时不可查,后期会进行清理。类似HBase的delete。
GET获取资源:
//根据document的id来获取数据:(without pretty)
curl -XGET http://192.168.159.36:9200/jw/employee/1?pretty // pretty 除source外的属性格式化作用
//根据field来查询数据:
curl -XGET http://192.168.159.36:9200/jw/employee/_search?q=first_name=“bin”
//根据field来查询数据:match
curl -XGET http://192.168.159.36:9200/jw/employee/_search?pretty -d ’
{
“query”:
{“match”:
{“first_name”:”bin”}
}
}’
//对多个field发起查询:multi_match
curl -XGET http://192.168.133.6:9200/bjsxt/employee/_search?pretty -d ’
{
“query”:
{“multi_match”:
{
“query”:”bin”,
“fields”:[“last_name”,”first_name”],
“operator”:”and”
}
}
}’
//多个term对多个field发起查询:bool(boolean)
组合查询,must,must_not,should
must + must : 交集
must +must_not :差集
should+should : 并集
curl -XGET http://192.168.133.6:9200/bjsxt/employee/_search?pretty -d ’
{
“query”:
{“bool” :
{
“must” :
{“match”:
{“first_name”:”bin”}
},
“must” :
{“match”:
{“age”:33}
}
}
}
}’
第四部分:ES的客户端API操作
直接上代码:
public class TestES {
public static Client client;
@Before
public void conn() {
Settings settings = Settings.settingsBuilder().put("cluster.name", "jw-es").build();
try {
client = TransportClient.builder().settings(settings).build()
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("node01"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("node02"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("node03"), 9300));
} catch (Exception e) {
e.printStackTrace();
}
}
// 建立Lucene片 副本数为2
@Test
public void test01() {
IndicesExistsResponse resp = client.admin().indices().prepareExists("javatest").execute().actionGet();
if (resp.isExists()) {
client.admin().indices().prepareDelete("javatest").execute();
}
Map<String, Object> sets = new HashMap<String, Object>();
sets.put("number_of_replicas", 2);
client.admin().indices().prepareCreate("javatest").setSettings(sets).execute();
}
// 推送数据
@Test
public void test02() {
Map<String, Object> data = new HashMap<String, Object>();
data.put("content", "bigData is good");
data.put("years", 111);
IndexResponse resp = client.prepareIndex("javatest", "test").setSource(data).execute().actionGet();
System.out.println(resp.getId());
}
// 获取数据并设置高亮
@Test
private void test03() {
MatchQueryBuilder query = new MatchQueryBuilder("content", "bigData");
SearchResponse resp = client.prepareSearch("javatest").setTypes("test").addHighlightedField("content")
.setHighlighterPreTags("<font color=red>").setHighlighterPostTags("</font>").setQuery(query).setFrom(0)
.setSize(1).execute().actionGet();
SearchHits hits = resp.getHits();
for (SearchHit hit : hits) {
System.out.println(hits.getTotalHits());
System.out.println(hit.getSource().get("content"));
System.out.println(hit.getSourceAsString());
System.out.println(hit.getHighlightFields().get("content").getFragments()[0]);
}
}