版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/programmingfool5/article/details/82354234
Batch Normalization
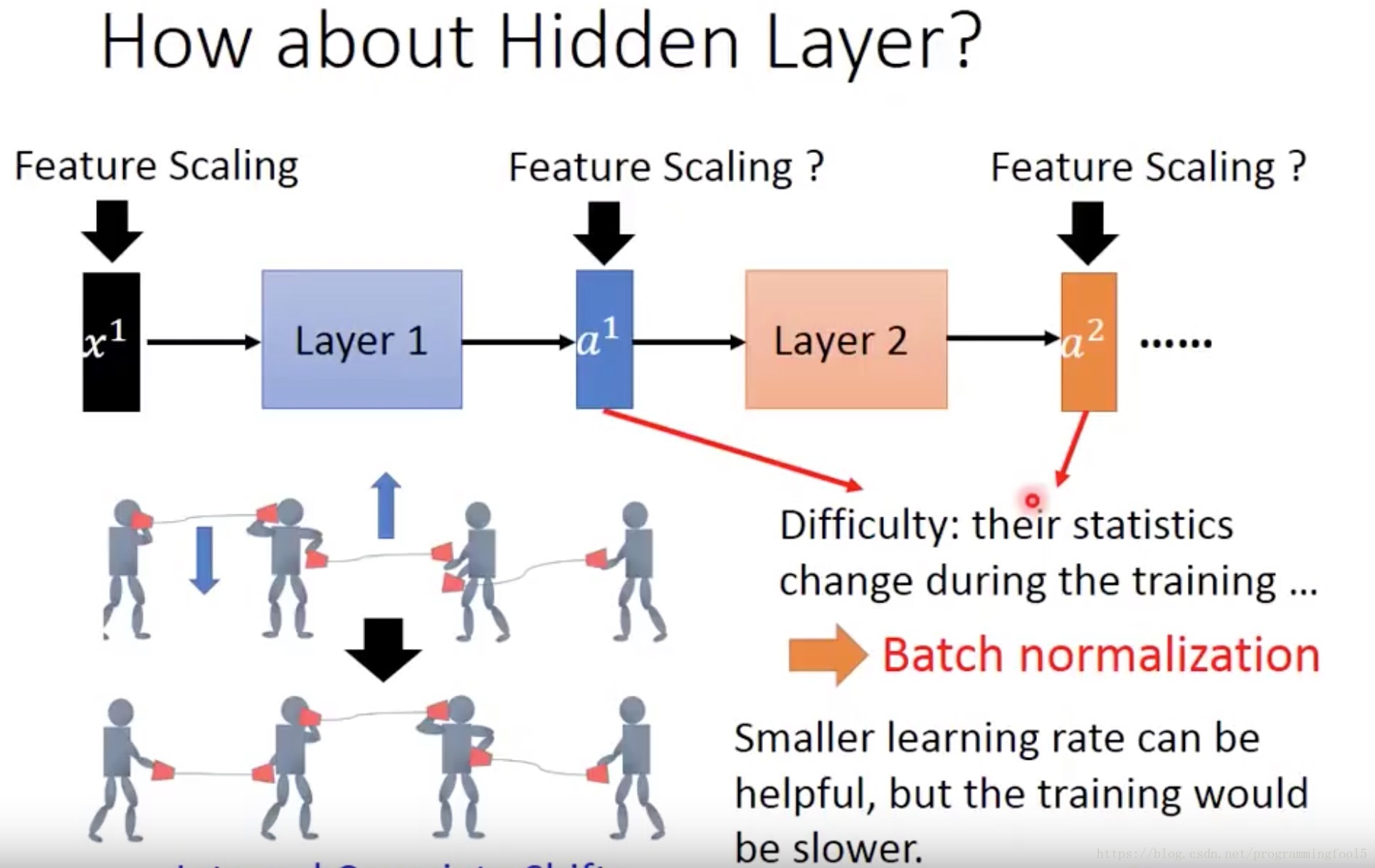
因为在深度神经网络中随着训练得进行,每一个隐层的参数不断的发生变化导致每一层的激活函数的输入发生改变,这与机器学习领域的假设:训练数据和测试数据的同分布是不符合的。所以会造成以下的问题:
(如果不scaling) 激活输入值分布的偏移,导致数据向线性函数的取值区间的上下线两端靠近,导致梯度消失/爆炸的问题,这就是问什么会训练速度降低的原因。(可以采用小的learning rate改善)
如果不采用这种多层之间协调(学习均值和方差)更新的策略,而使用逐层的白化操作,即在每个梯度下降更新参数后重新标准化,那么一层中参数的变化会造成其他参数层的剧烈变化,那么学习算法会反复改变均值和方差(w发生了变化),然后再用标准化反复抵消这种变化,导致训练速度降低甚至无法收敛。
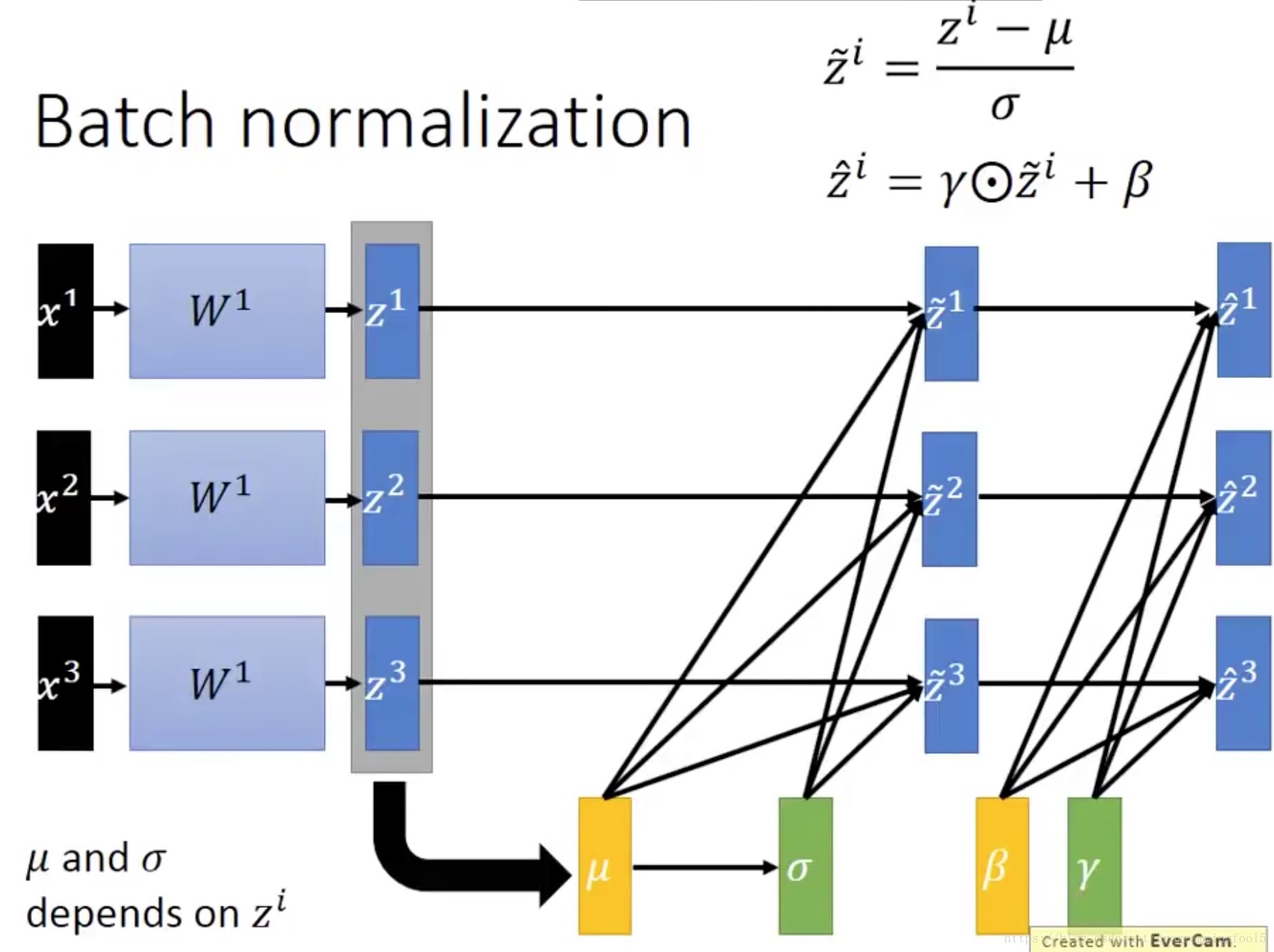
而BN算法就是(通过学习参数)将数据强行拉到均值为0,方差为1的比较标准的正态分布。但是这样子导致的问题是:只利用到了线性区域而导致深层无意义,使得模型的表达能力下降。为了保证非线性的获得,用y = scale*x + shift,将数据移动或者伸缩。