亚马逊、谷歌、微软、facebook——这些公司和其他许多公司都在争相创建最丰富、最容易的机器学习和深度学习库。竞争是好的!我们在机器学习领域的2018年“Bossie”获奖者包括最先进的框架、用于构建和培训模型的其他前沿工具,以及在集群中传播深度学习的平台。
目录
TensorFlow
TensorFlow自从我在2018年1月回顾了被广泛采用的深层神经网络框架以来,TensorFlow又收到了5个版本的升级,甚至更容易、更强大。主要的新特性和改进包括与Google Cloud Bigtable集成作为数据源,这是一个更好的tf.keras模块,更好的生成用于移动设备的优化模型,改进数据加载和文本处理,预取GPU内存的新数据,以及通过Google Cloud TPUs改进性能,并将eager执行模式提升到完全支持状态。您可能还记得,eager执行提供了一种命令式编程风格,它比构建和执行图形更容易理解。——马丁海勒
Keras

Keras就像一个深度神经网络框架一样简单,一层一行的Python代码,调用每个模块来编译和训练一个模型,使用顺序模型。Keras还通过它的功能API提供了任意拓扑的支持。Keras使用TensorFlow、Theano、和CNTK 2作为后端,并获得它们对GPU的良好支持(以及Google Cloud上的TPUs)。Keras的培训使用Numpy数组作为输入,尽管它可以通过Python生成器接口支持其他格式。Keras有各种各样的部署选项,从云服务到移动设备。——马丁海勒
PyTorch
PyTorch是一个高级的深层神经网络,它使用Python作为脚本语言,并使用了一个演化的Torch C/CUDA后端。Caffe2的生产特性也被纳入到PyTorch项目。PyTorch的特点是动态神经网络,这意味着网络拓扑本身可以在训练过程中从迭代到迭代训练。
为了支持动态网络,这两种网络比静态网络更容易调试和更快地迭代。PyTorch程序敏捷的创建一个图表。然后反向传播使用动态创建的图表,自动计算从保存的张量状态下的梯度。鉴于在成熟的Torch框架基础上,已经有了强大的神经网络层,优化算法和损失函数。——马丁海勒
fast.ai
fast.ai不仅仅是一个深度学习的MOOC;它也是一个建立在PyTorch之上的深度学习库。该fast.ai框架不仅为构建和培训模型提供了一套包装器,而且还采用了一些用于培训深度学习模型的前沿技术(如循环学习率。并为NLP问题域转移学习技术)。换句话说,fast.ai将帮助你为Kaggle的竞赛和实际的生产应用程序建立模型。最重要的是,这可能是进入深度学习的最简单的方式!
Chainer

Chainer是一个灵活的神经网络的Python框架。与首先定义和修复神经网络拓扑的框架不同,最后对其进行培训。Chainer使用一个逐个运行的方案。这意味着网络是通过实际的前向计算动态定义的;反向传播计算计算梯度数组,并调用优化器来查找更新后的权重。
Chainer使用CuPy作为GPU计算的后端,后者又调用CUDA和cuDNN。特别是,cupy.ndarray类是Chainer的GPU阵列实现。CuPy支持一个具有兼容接口的NumPy特性的子集。Chainer已经影响了其他最近的神经网络框架。PyTorch也使用动态神经网络,而TensorFlow的eager执行模式也是如此——马丁海勒
H20
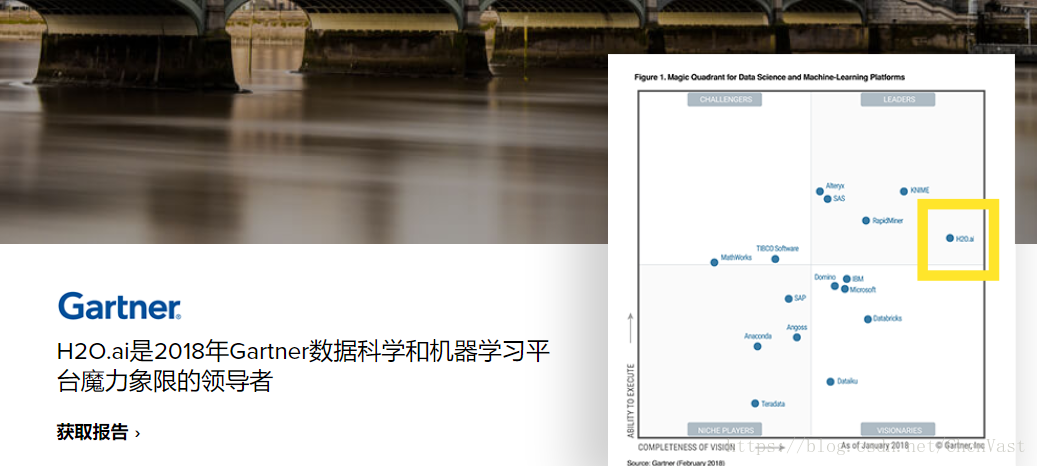
当我在2017年晚些时候回顾H20.ai的无人驾驶技术时。我喜欢它是一个自动驱动的机器学习系统,它也有工程和注释功能。我解释说,它是建立在开源的H2O堆栈之上的,它为无人驾驶的Al提供了所有的机器学习,并且还提供了它自己的auto ML和数据准备模块。
H20是一个具有线性可伸缩性的分布式内存机器学习平台。它支持最广泛使用的统计和机器学习算法,包括梯度提升机、广义线性模型和深度学习。H2O支持在R、Python、Scala、Java和它自己的交互式笔记本上的编程。——马丁海勒
Microsoft Cognitive Toolkit
Microsoft Cognitive Toolkit(或者更简单的CNTK)—是一个深度学习工具包,它是微软服务的基础,包括Skype、Cortana、Bing和Xbox。它处理来自Python、C++或BrainScript的多维密度或稀疏数据,并包含各种各样的神经网络类型:前馈(FFN)、卷积(CNN)、递归/长短期记忆(RNN/LSTM)、批量归一化和注意顺序序列。
Cognitive Toolkit支持强化学习、生成对抗网络、监督和非监督学习、自动超参数调优,以及在GPU上添加新的、用户定义的核心组件的能力。它能够在多个GPU和机器上实现并行性,甚至可以将最大的模型应用到GPU内存中。——马丁海勒
MXNet
当这个深度学习框架在2016年出现时,它的有趣之处在于两个原因:它在大量的网络实例上扩展了多个GPU,这是亚马逊最首选的深层神经网络框架。但正如我所评论说的那样,MXNet的边缘很粗糙。
MXNet在2017年初迁移到Apache Software Foundation保护伞下运作,在v1.2.1中仍然被认为是“孵化”。然而,它的边缘不再是粗糙了。
MXNet拥有对设备数据结构放置的良好控制。多GPU训练、自动微分和优化的预定义神经网络层。它在Gluon中有一个易于使用的界面,可以用来快速训练。在使用Gluon之前,您可以在MXNet中编写简单的命令式代码或快速符号代码。但不能同时编译两种。——马丁海勒
Featuretools

Featuretools是一个用于自动化特性工程的开源Python库。如果您曾经做过任何严肃的数据科学,您就会知道手动将原始数据转换成有意义的、规范化的特性是多么的棘手和耗时。从H2O中获得的专有的无人驾驶AI暂时了自动化特征工程,几乎达到了一个Kaggle的大师水平。
Featuretools实现了深度特性的合成。您可以将原始数据与您所知道的数据结合起来,为机器学习和预测建模构建有意义的特性。特性工具提供了APl以确保只使用有效的数据进行计算,使特性向量避免常见的标签泄漏问题。——马丁海勒
Horovod
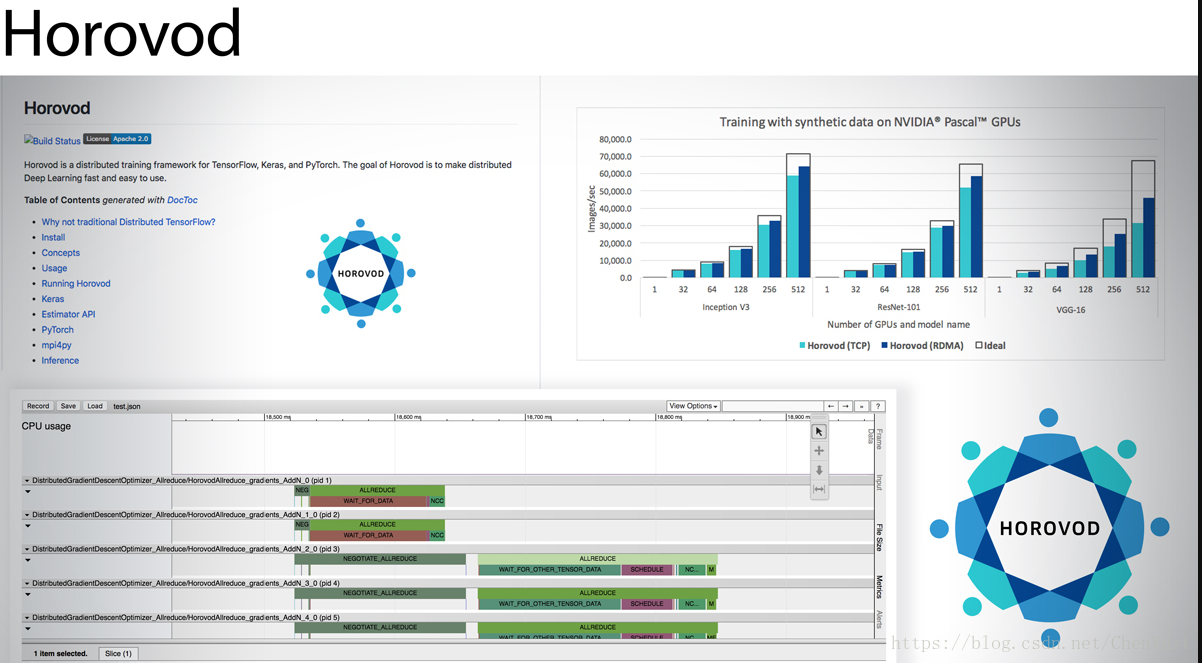
Horovod创建于Uber。Horovod是一种用于TensorFlow、Keras和PyTorch的分布式训练框架。Horovod的目标是使分布式的深度学习变得快速和易于使用。Horovod借鉴了百度的TensorFlow ring-allreduce算法的实现,并以此为基础。
Horovod使用Open MPI(或另一个MPI实现)来传递节点间的消息。以及Nvidia的集体通信库(NCCL),用于其高度优化的ring-allreduce版本。Horovod使用了多达512个 Nvidia Pascal GPU,在Inception V3和ResNet-101中实现了90%的扩展效率,VGG-16的扩展效率为68%。——马丁海勒
Fabric Deep Learning(FfDL)
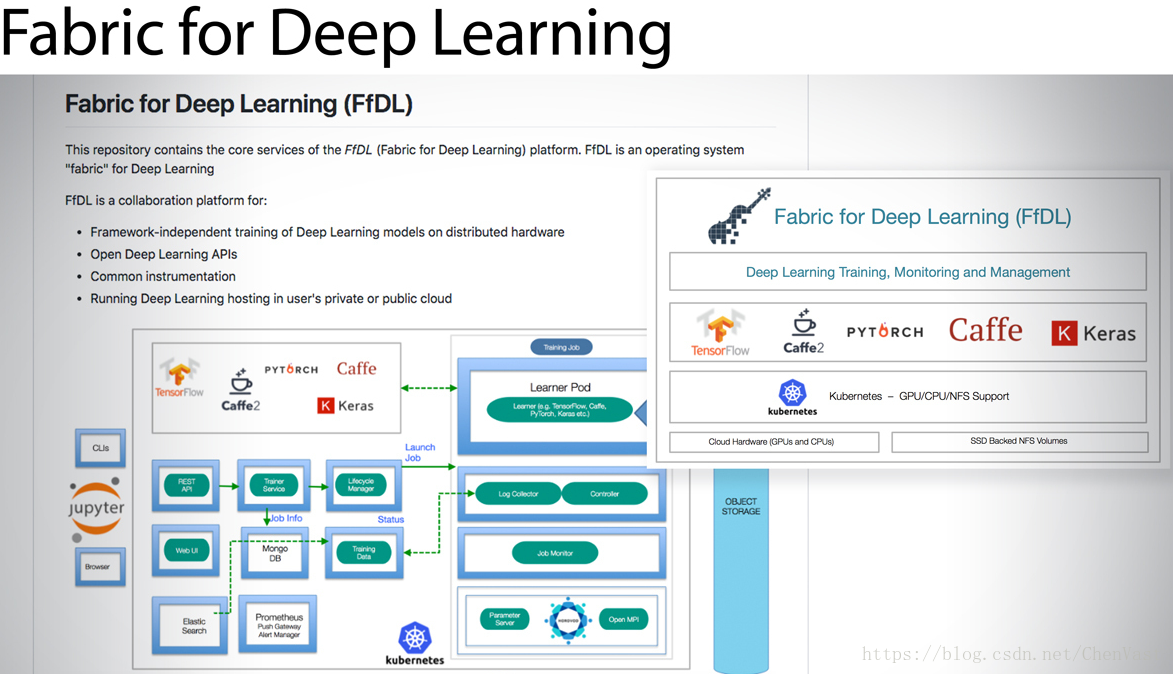
Fabric Deep Learning(FfDL),发音为“fiddle”是一个深度学习平台,提供TensorFlow、Caffe、PyTorch、Keras和H2O,作为Kubernetes的服务。FfDL最初是为IBM Cloud开发的,但也可以在支持Kubernetes集群的其他云中运行,也可以在Docker通过Kubeadm-DIND在本地运行。如果您在Kubernetes中使用设备插件,并且您选择启用GPU-enabled,那么FfDL将支持GPU的深度学习框架的构建。FfDL只在MacOS和Linux下进行测试。——马丁海勒