Kafka是一个可水平扩展、高吞吐量、分布式的发布-订阅消息系统,一个分布式流式处理平台,其核心模块使用Scala语言开发,支持多种语言的客户端。
基本概念
主题
一组消息抽象归纳为一个主题,即一个主题就是对消息的一个分类。
消息(Record)
Kafka通信的基本单位,由一个固定长度的消息头和一个可变长度的消息体构成。消息支持Gzip、Snappy、LZ4这三种压缩方式。
分区和副本
一个主题可被分成一个或多个分区,每个分区由一系列有序、不可变的消息组成,是一个有序队列,每个分区在物理上对应为一个文件夹。
Leader副本和Follower副本
一个分区可以有多个副本,其数据需保持一致,其中有一个作为Leader,其他作为Follower,各Follower从Leader同步数据来保证数据一致性,在Leader失效后,在Follower之间选举一个新的分区副本作为Leader。
偏移量
每条消息在日志文件中的位置都会对应一个按序递增的偏移量,偏移量是一个分区下严格有序的逻辑值,不表示消息在磁盘上的物理位置。
日志段
日志可被划分为多个日志段,它是Kafka日志对象分片的最小单位,是一个逻辑概念。
代理(Broker)
一个Kafka集群由多个Kafka实例构成,在集群中,每个Kafka实例称为代理,每个代理都有唯一的标识id。代理是无状态的,即代理不记录消息是否被消费,消息偏移量的管理交由消费者自己或组协调器来维护。
生产者
生产者负责将消息发生给代理。
消费者和消费组
消费者以pull方式拉取数据,每个消费者都属于一个特定消费组,默认消费组为test-consumer-group,每个消费组都有唯一的标识id。
同一个主题的一条消息只能被同一个消费组下某一个消费者消费,但是不同消费组的消费者可同时消费该消息。
ISR(In-sync Replica)
Kafka在ZooKeeper中动态维护了一个ISR,即保存同步的副本列表,该列表保存的是与Leader副本保持消息同步的所有副本对应的代理节点的id。
ZooKeeper
ZooKeeper是一个分布式应用程序协调服务框架,分布式应用程序可以基于ZookKeeper来实现同步服务、配置维护、命名服务等,Kafka利用ZooKeeper保存相应元数据信息,Kafka元数据信息包括如代理节点信息、Kafka集群信息、主题信息等等。
安装与配置
1. 首先需要JDK1.8,安装很简单,不做介绍。

2. 远程登录免密码配置
2.1 创建RSA密钥对
ssh-keygen -t rsa
2.2 将2.1步骤生成的id_rsa.pub内容追加到授权的key文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
此时,已经可在本机免密登录本机。
2.3 在集群环境中,2.2步骤生成的authorized_keys文件拷贝到其他电脑,如B机器,然后在B机器重复2.1步骤和2.2步骤。
2.4 在集群环境中,接着步骤2.3,将2.3步骤的authorized_keys文件拷贝到C机器,重复步骤2.1和2.2,类似接力,这样,集群各个电脑就可以互相免密登录了。
3. ZooKeeper安装配置
下载压缩包解压配置环境变量就可以了,很简单:

配置文件在子目录conf下有一个模板,我们改个名字即可:

配置文件内容很简单,如下:

配置文件内容说明:
- tickTime : ZooKeeper的一个时间单元,其所有时间都以这个为基准,默认2S。
- initLimit : Follower在启动过程会从Leader同步所有最新数据,从而确定自己能够对外服务的起始状态。如果在10*2000ms还没完成数据同步,则Follower启动失败。
- syncLimit : Leader和Follower之间通信请求和应答的时间长度,可以说是心跳。
- dataDir : 存储快照文件的目录,默认日志也会存放同一个目录,建议增加配置dataLogDir来分开存储
- clientPort : 对外端口
对于单机环境的ZooKeeper,只需修改一个配置文件,然后启动即可。
对于集群环境,按如下配置:
A. 如有3台机: 192.168.11.1, 192.168.11.2, 192.168.11.3,以在192.168.11.1配置为例:
修改文件/etc/hosts文件,增加配置:
192.168.11.1 server-1
192.168.11.2 server-2
192.168.11.3 server-3
B. 修改zoo.cfg文件,增加配置:
server.1=server-1:3277:3288
server.2=server-2:3277:3288
server.3=server-3:3277:3288
其中,server.1的1是ZooKeeper的服务器id,3277是该服务器与Leader交换信息的端口,3288是选举时服务器相互通信的端口。
C. 在dataDir目录下新建文件: myid,内容为1
D. 其他两台服务器类似配置即可。
4. 启动,这里我就配置单机环境吧,直接在Mac上搞

查看状态:

standalone即为标准的单机模式。

5. Kafka安装配置

同样是下载压缩包然后配置环境变量,然后配置$KAFKA_HOME/config/server.properties文件即可。



这里ZooKeeper和Kafka安装在一台机,所以这里保持默认:

如果是连接到集群,则如下:
zookeeper.connect=server-1:2181,server-2:2181,server-3:2181
6. 启动Kafka
首先确保ZooKeeper已启动运行。

登录ZooKeeper看看:
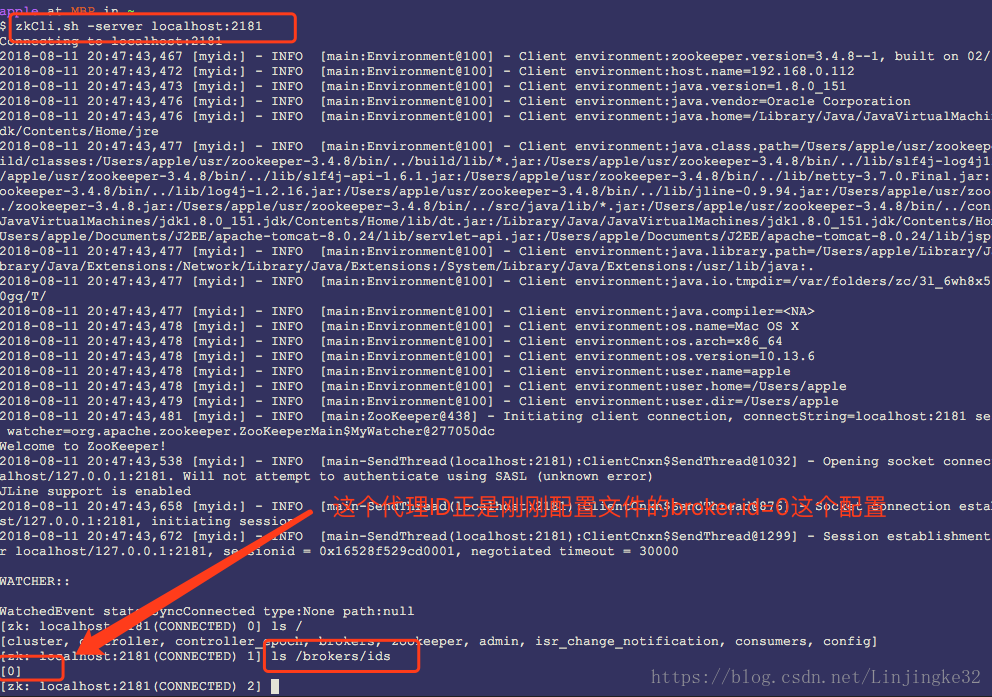
7. 管理页面安装
为了方便了解Kafka运行情况,这里采用源码编译安装Kafka Manager网页工具,当然,这次编译后的文件以后可以直接拷贝到其他电脑进行安装运行,也节省时间:

编译Kafka manager:

发生错误:

自己去网上下载然后放到指定目录下:

重新编译,额,还是好慢啊~我们增加下配置:

文件内容如下:
[repositories]
local
aliyun: http://maven.aliyun.com/nexus/content/groups/public
typesafe: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly重新编译,速度快很多啊~~~
把编译好的放到特定目录下:

修改配置文件conf/applicatino.conf

启动:

上面的命令可以后台运行。

点击这里跳到增加集群的窗口:
输入相关信息:

这里只输入了这两个信息,其他默认。添加后可以看到代理的信息如下所示:
最后,注意到如下这个文件:
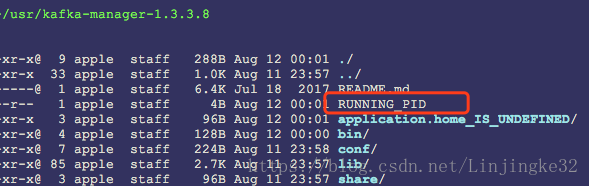
Kafka Manager关闭进程可以通过kill -9 {进程ID},但是记得也删了这个文件,以免下次启动失败。