1.垃圾回收机制
可达性分析:
当一个对象到 GC Roots 没有任何引用链时,即从 GC Roots 到这个对象不可达,则说明该对象不可用,可被垃圾回收器回收。
注:如果类实现了 finalize() 方法,则被回收前会先调用该方法,且只会调用一次。
垃圾收集算法:
标记清除 (Mark-Sweep)
标记出所有需要回收的对象,标记完成后统一回收被标记的对象。
主要缺点:效率不高;产生大量内存碎片。内存碎片太多可能会导致分配较大对象时,找不到连续内存而触发 GC。
复制 (Copying)
将内存划分为大小相等的两块,每次只使用其中一块。当这块内存用完了,则将存活对象复制到另一块上,然后将已使用的内存空间一次清理掉。适用于多用于新生代。
优点:算法简单高效,且无内存碎片
缺点:牺牲了空间
标记整理 (Mark-Compact)
标记出需要回收的对象,让所有存活的对象都向一端移动,然后清理掉端另一边的内存。
分代收集算法
根据对象存活周期的不同,将内存分为几块。一般为新生代和老年代(jdk 1.8移除了永久代)。新生代存活对象少,采用复制算法;老年代对象存活率高,采用标记-清除或标记-整理算法。
IBM 研究表明,新生代中 98% 对象存活率很低,所以不需要按照 1:1 的比例来划分内存空间,而是使用一块较大的 Eden 区和两块较小的 Survivor 区,每次 YGC 时将 Eden 区和其中一块 Survivor 区的存活对象复制到另一个 Survivor 区,再一次性清除 Eden 区和使用过的 Survivor 区。
Eden 区和 Survivor 区默认比例大小为 8:1,牺牲 Young 区10%的空间,可通过 SurvivorRatio 参数指定。
内存分配和回收策略
// TODO
2.垃圾收集器
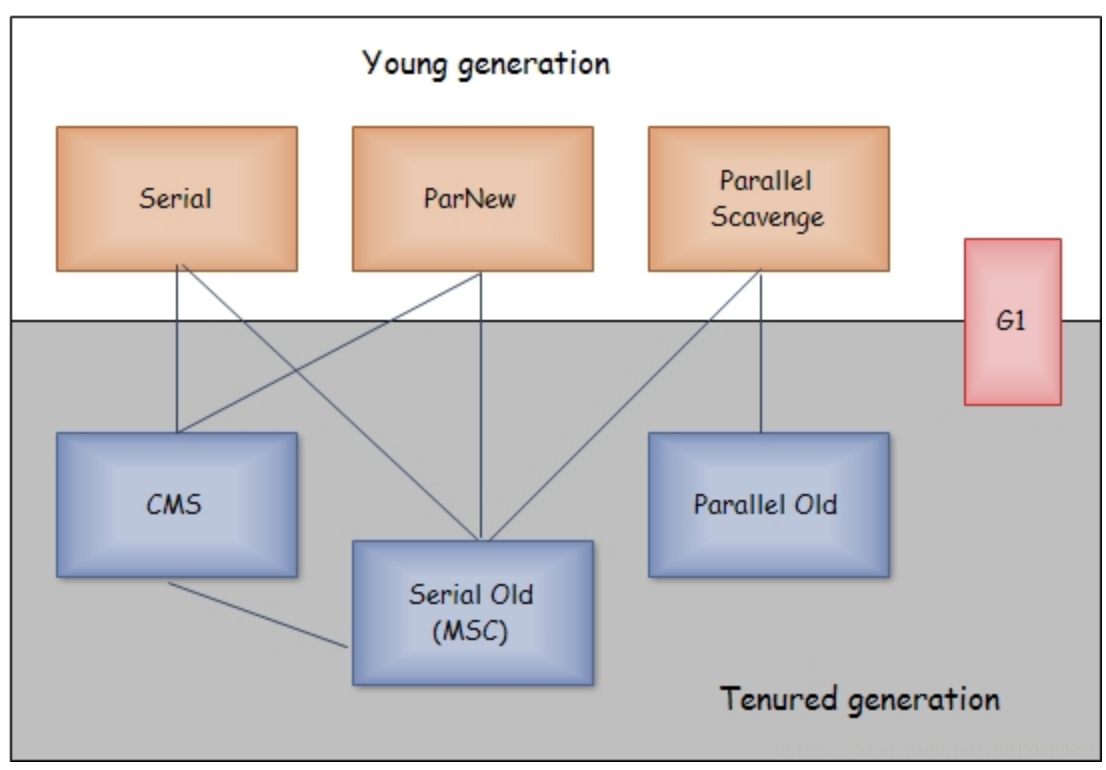
HotSpot 虚拟机的垃圾收集器(图片网上找的):
如果两个收集器之间存在连线,则说明它们可以搭配使用。
CMS GC 收集器
基于标记-清除算法。只有 CMS initial mark 和 CMS Final Remark 阶段会 Stop The World。
初始标记(CMS initial mark)
标记那些直接被 GC Roots 引用或者被年轻代存活对象所引用的所有对象,会 Stop The World。
并发标记(CMS concurrent mark)
遍历整个 old 区,并发标记存活对象。和应用线程并行执行,此时有些对象可能会改变可达状态。
并发预清理(CMS concurrent preclean)
并发阶段,和应用线程并行执行。在前面并发执行的阶段中,有些对象的引用可能会发生变化,JVM 会将包含该对象的区域 (Card) 标记为 Dirty (即 Card Marking)。
在 pre-clean 阶段,那些能从 Dirty Card 对象到达的对象也会被标记,标记完成之后,Dirty Card 标记会被清除。
此外,还会执行一些必要的清理和为 Final Remark 阶段做一些准备工作。
并发预清理(CMS concurrent abortable preclean)
并发执行,这个阶段会尽可能的减轻 Final Remark 阶段 Stop The World 的压力。
这个阶段的时间依赖于很多因素,会重复做相同的事情,直至满足一些条件,如:重复的次数、有效的工作量、始终时间等。
重新标记(CMS Final Remark)
完成标记整个 old 区所有的可达对象,会 Stop The World。
并发清除(CMS concurrent sweep)
并发移除不可达对象,并回收空间。
并发重置(CMS concurrent reset)
并发重置 CMS 内部数据结构,为下个周期做准备。
3.JDK 命令行工具
常用命令如下
jps
列出正在运行的虚拟机进程。
jps -v: 列出虚拟机进程启动时的 JVM 参数
jps -l: 输出主类全名,如果执行的是 jar 包,则输出 jar 包路径
jstat
监控虚拟机各种运行状态信息。
jstat -gc <pid>: 按实际大小输出 Java 堆信息
jstat -gcutil <pid>: 按百分比方式输出 Java 堆信息
jstat -class <pid>:输出类加载、卸载、总空间以及加载类所消耗的时间
jstat -gccapacity <pid>: 与 -gc 基本相同,主要输出各个区域使用到的最大、最小空间
jstat -gccause <pid>: 和 -gcutil 功能一样,会额外输出上一次 GC 的原因
jstat -gcnew <pid>: 新生代 GC
jstat -gcnewcapacity <pid>: 和 -gcnew 基本相同,主要关注使用到的最大、最小空间
jstat -gcold <pid>: 老年代 GC
jstat -gcoldcapacity <pid>: 和 -gcold 基本相同,主要关注使用到的最大、最小空间
jstat -compiler <pid>:输出 JIT 编译器编译过的方法、耗时等信息
jstat -printcompilation <pid>:输出已经被 JIT 编译过的方法
注:上述命令后加[interval [s|ms]] [count] 表示查询间隔和次数。
jinfo
jmap
生成堆转储快照,即 dump 文件。
-dump:
-heap:
-histo:
实例: jmap -dump:format=b,file=<FilePath> <pid>
注:jmap 命令可能引起 Stop The World,其中 -histo:live 会触发 FGC。
jstack
查看
4.GC 日志
GC 日志 JVM 配置
-XX:+PrintGCDetails // 输出GC的详细日志
-XX:+PrintHeapAtGC // 在 GC 前后打印堆内存信息
-XX:+PrintGCDateStamps // 以日期的形式输出GC的时间戳,如2018-09-29T16:00:43.652+0800,下面实例中未配置该参数
-Xloggc:/tmp/gc/gc.log // 指定 gc 日志文件路径
YGC/Minor GC 日志
{Heap before GC invocations=8 (full 1):
par new generation total 306688K, used 285903K [0x0000000080000000, 0x0000000094cc0000, 0x0000000094cc0000)
eden space 272640K, 100% used [0x0000000080000000, 0x0000000090a40000, 0x0000000090a40000)
from space 34048K, 38% used [0x0000000090a40000, 0x0000000091733e10, 0x0000000092b80000)
to space 34048K, 0% used [0x0000000092b80000, 0x0000000092b80000, 0x0000000094cc0000)
concurrent mark-sweep generation total 1756416K, used 15848K [0x0000000094cc0000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 44197K, capacity 45500K, committed 46108K, reserved 1089536K
class space used 5199K, capacity 5366K, committed 5472K, reserved 1048576K
23.587: [GC (Allocation Failure) 23.587: [ParNew: 285903K->33786K(306688K), 0.1286737 secs] 301751K->49634K(2063104K), 0.1287772 secs] [Times: user=0.05 sys=0.11, real=0.13 secs]
Heap after GC invocations=9 (full 1):
par new generation total 306688K, used 33786K [0x0000000080000000, 0x0000000094cc0000, 0x0000000094cc0000)
eden space 272640K, 0% used [0x0000000080000000, 0x0000000080000000, 0x0000000090a40000)
from space 34048K, 99% used [0x0000000092b80000, 0x0000000094c7e838, 0x0000000094cc0000)
to space 34048K, 0% used [0x0000000090a40000, 0x0000000090a40000, 0x0000000092b80000)
concurrent mark-sweep generation total 1756416K, used 15848K [0x0000000094cc0000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 44197K, capacity 45500K, committed 46108K, reserved 1089536K
class space used 5199K, capacity 5366K, committed 5472K, reserved 1048576K
}
展示了 YGC 前后堆内存信息,以及 YGC 日志。
23.587: [GC (Allocation Failure) 23.587: [ParNew: 285903K->33786K(306688K), 0.1286737 secs] 301751K->49634K(2063104K), 0.1287772 secs] [Times: user=0.05 sys=0.11, real=0.13 secs]
23.587:GC发生的时间。含义为自 JVM 启动以来经过的秒数。
GC:表示是 Minor GC 还是 Full GC,此处为 Minor GC。
Allocation Failure:GC 原因。
ParNew: GC 发生的区域。该名称和使用的垃圾收集器密切相关,此处表示使用的是 ParNew 收集器,即 Parallel New Generation。Serial 收集器对应 DefNew,Parallel Scavenge 收集器对应 PSYoungGen。
285903K->33786K(306688K), 0.1286737 secs: GC 前该内存区域已使用容量 -> GC 后该内存区域已使用容量(该内存区域总容量),GC 时间为 0.1286737 秒。
301751K->49634K(2063104K):GC 前 Java 堆已使用容量 -> GC 后 Java 堆已使用容量(Java 堆总容量)
[Times: user=0.05 sys=0.11, real=0.13 secs] :与 Linux time 命令输出的时间含义一致,分别为 用户态消耗的 CPU 时间、内核态消耗的 CPU 时间、操作从开始到结束所经过的时钟时间。CPU 时间和时钟时间区别在于,时钟时间包括各种非计算的等待耗时,如线程阻塞时间。
CMS GC日志
7.428: [GC (CMS Initial Mark) [1 CMS-initial-mark: 0K(1756416K)] 120764K(2063104K), 0.0254557 secs] [Times: user=0.08 sys=0.00, real=0.03 secs]
7.453: [CMS-concurrent-mark-start]
7.466: [CMS-concurrent-mark: 0.013/0.013 secs] [Times: user=0.03 sys=0.01, real=0.01 secs]
7.467: [CMS-concurrent-preclean-start]
7.476: [CMS-concurrent-preclean: 0.010/0.010 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
7.476: [CMS-concurrent-abortable-preclean-start]
11.917: [CMS-concurrent-abortable-preclean: 2.707/4.441 secs] [Times: user=11.40 sys=0.32, real=4.44 secs]
11.917: [GC (CMS Final Remark) [YG occupancy: 167918 K (306688 K)]11.917: [Rescan (parallel) , 0.0353793 secs]11.953: [weak refs processing, 0.0000242 secs]11.953: [class unloading, 0.0089659 secs]11.962: [scrub symbol table, 0.0050880 secs]11.967: [scrub string table, 0.0005698 secs][1 CMS-remark: 0K(1756416K)] 167918K(2063104K), 0.0521882 secs] [Times: user=0.15 sys=0.00, real=0.05 secs]
11.970: [CMS-concurrent-sweep-start]
11.970: [CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
11.970: [CMS-concurrent-reset-start]
12.000: [CMS-concurrent-reset: 0.030/0.030 secs] [Times: user=0.06 sys=0.03, real=0.03 secs]
展示了 CMS GC 的各个阶段,各阶段内容见上面简介。
7.428: [GC (CMS Initial Mark) [1 CMS-initial-mark: 0K(1756416K)] 120764K(2063104K), 0.0254557 secs] [Times: user=0.08 sys=0.00, real=0.03 secs]
CMS Initial Mark 阶段日志。
CMS-initial-mark:表明阶段0K(1756416K)]:Old区占用和容量120764K(2063104K):堆占用和容量- 0.0254557 secs] [Times: user=0.08 sys=0.00, real=0.03 secs]:阶段执行时间
11.917: [GC (CMS Final Remark) [YG occupancy: 167918 K (306688 K)]11.917: [Rescan (parallel) , 0.0353793 secs]11.953: [weak refs processing, 0.0000242 secs]11.953: [class unloading, 0.0089659 secs]11.962: [scrub symbol table, 0.0050880 secs]11.967: [scrub string table, 0.0005698 secs][1 CMS-remark: 0K(1756416K)] 167918K(2063104K), 0.0521882 secs] [Times: user=0.15 sys=0.00, real=0.05 secs]
CMS Final Remark 阶段日志:
YG occupancy: 167918 K (306688 K):Young区当前占用和容量Rescan (parallel) , 0.0353793 secs: 在应用停止的时候,并发标记存活对象weak refs processing, 0.0000242 secs: 子阶段,处理弱引用class unloading, 0.0089659 secs: 子阶段,卸载无用的类scrub symbol table, 0.0050880 secs: 清理symbol table,包含类的元数据scrub string table, 0.0005698 secs: 清理string table,包含内部字符串CMS-remark: 0K(1756416K)] 167918K(2063104K), 0.0521882 secs: 这个阶段执行完后,Old区的占用和容量
5.CMS GC, Full GC, System.gc()
CMS GC
分为 background, foreground 两种模式。
background 模式:后台运行。触发条件如 old 区内存超过一定阈值,会经历 CMS GC 的所有阶段,有暂停,有并行,效率较高。
foreground 模式:前台运行。触发条件如线程请求分配内存时,但是内存不够,这个时候必须等内存分配到了,线程才继续往下走,因此全程 Stop The World,但只走其中的几个阶段,效率较低。
Full GC
分为正常 Full GC,并行 Full GC 两种
正常 Full GC:整个 GC 过程,包括 YGC 和 CMS GC(但调用 Full GC接口,两种 GC 不一定都会执行),其中 CMS GC 为 forebackground 模式
并行 Full GC:效率较高,CMS GC 为 background 模式
System.gc()
System.gc() 是一次 Full GC,会暂停整个进程,因此线上一般会通过 -XX:+DisableExplicitGC 禁用。在 CMS 收集器中可以通过 -XX:+ExplicitGCInvokesConcurrent 指定 并行 Full GC 方式,来做一次效率更高的 GC。
6.HeapByteBuffer 和 DirectByteBuffer
Java NIO 使用 Buffer 作为和 Channel 交互的工具。而 ByteBuffer 主要有两个子类: HeapByteBuffer, DirectByteBuffer。通过 ByteBuffer 申请方式:
// 申请 HeapByteBuffer
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
// 申请 DirectByteBuffer
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
DirectByteBuffer
使用 malloc() 在 Java 堆外分配内存。
通过 Unsafe 接口 os:malloc 分配内存,将内存地址和大小存在 DirectByteBuffer 对象中,直接操作内存。只有在 DirectByteBuffer 对象被回收了,才能回收这些内存。因此,如果这些对象移到了 Old 区,而没有执行 CMS GC 或 Full GC,则物理内存可能会被耗尽。可通过 JVM 参数:-XX:MaxDirectMemorySize 设置最大直接内存大小,到达阈值时执行 System.gc(),前提是未被禁用。
HeapByteBuffer
封装 byte[] 数组,在 Java 堆内存分配。
当使用 HeapByteBuffer 进行网络通信等 IO 操作时,由于只有“本地”内存才能传递给操作系统调用,此时会将数据复制到一个临时的 DirectByteBuffer 对象中,JDK 会为每个线程缓存这个临时对象,且不限制内存大小。因此,如果程序有多个线程生成很多大 HeapByteBuffer 对象时,且线程一直存活,则会导致进程会占用大量的本地内存,造成内存泄露。
代码重现
// TODO
解决
- JDK 9提供了 JVM 参数:
-Djdk.nio.maxCachedBufferSize=262144,来限制这个缓存的大小; - 直接使用
DirectByteBuffer,或考虑Netty等 NIO 框架。
7.参考资料
《深入理解Java虚拟机》作者 周志明
Fixing Java’s ByteBuffer native memory “leak”
JVM源码分析之SystemGC完全解读
garbage-collection-algorithms
CMS垃圾回收分析