版权声明:个人博客网址 https://29dch.github.io/ 博主GitHub网址 https://github.com/29DCH,欢迎大家前来交流探讨和fork! https://blog.csdn.net/CowBoySoBusy/article/details/82919184
首先通过一幅漫画来了解一下(很经典的一幅图,从网上找的)
写数据到HDFS:

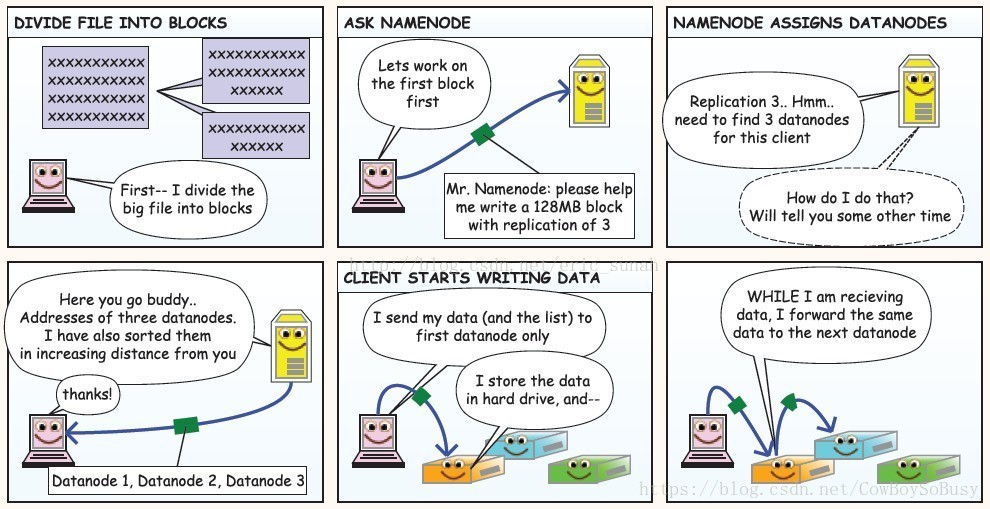
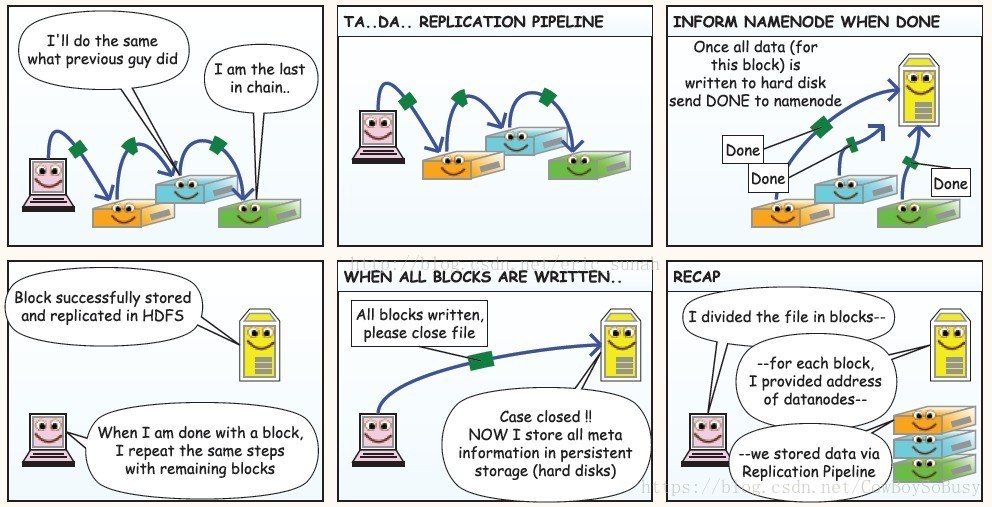
从HDFS上读数据:
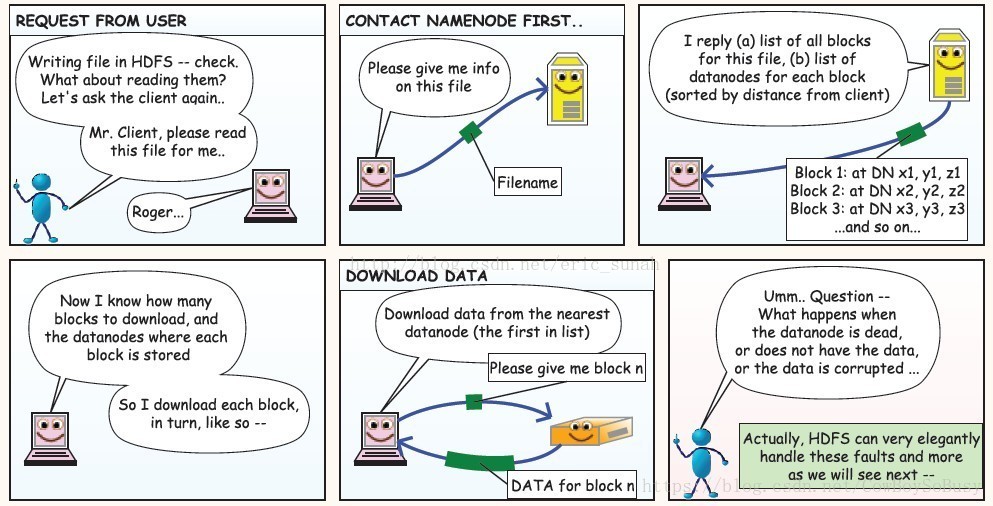
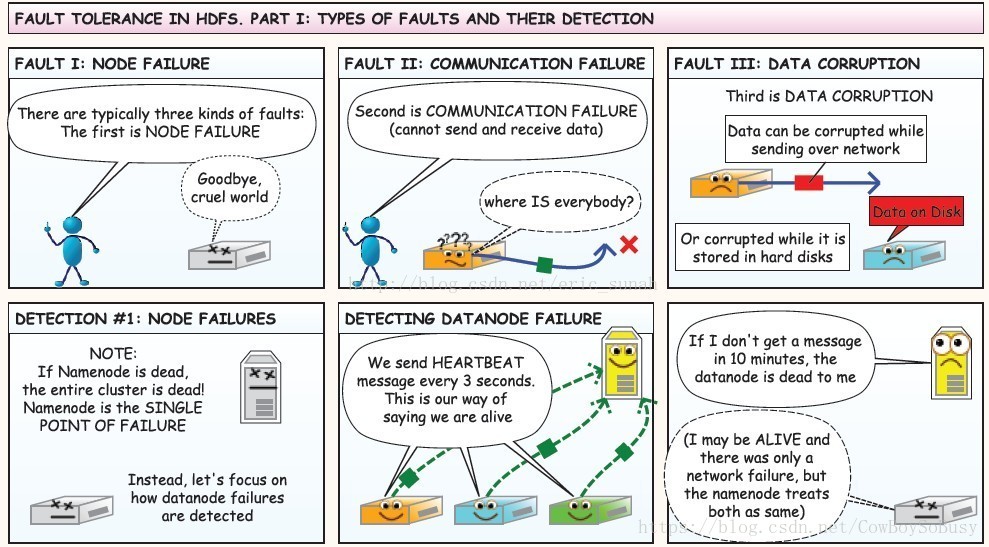

HDFS优点:
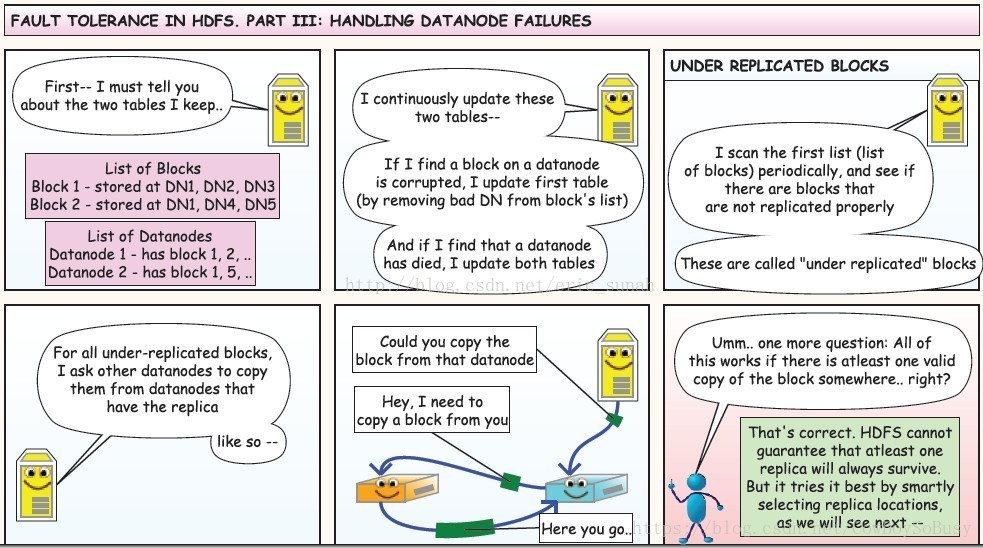
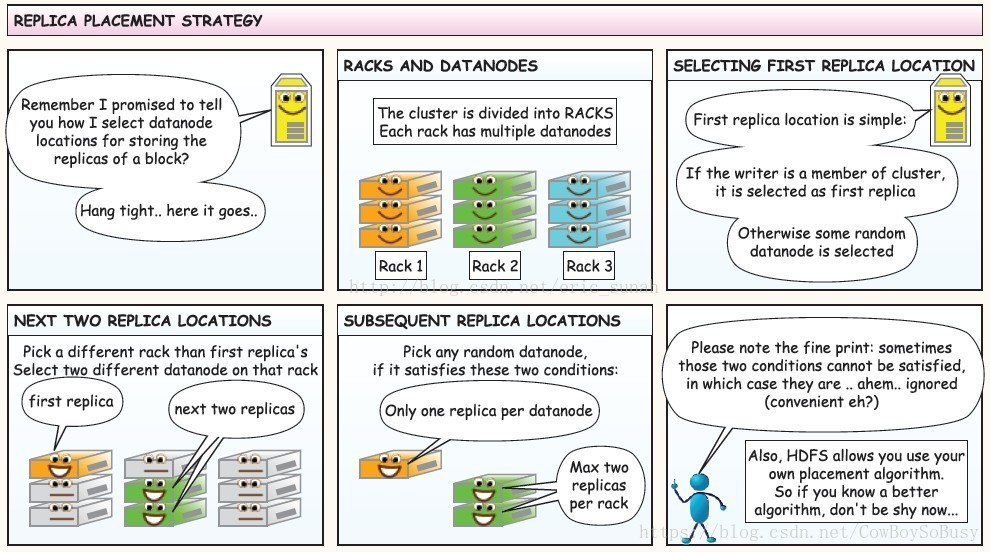
数据冗余,硬件容错
处理流式(一次写入,多次读取的操作)的数据访问
面向大规模数据集,能够进行批处理、能够横向扩展
适合存储大文件
构建在廉价机器上,成本较低
缺点:
不支持低延迟的数据访问
不适合大量小文件的存储(元数据meta data占用内存过大导致NameNode压力也越大)
不支持并发写入,一个文件只能有一个写入者
不支持文件随机修改,仅支持追加写入
更多内容可以了解
https://blog.csdn.net/github_36444580/article/details/77840481
https://blog.csdn.net/qq_26442553/article/details/78529212
https://blog.csdn.net/whdxjbw/article/details/81072207