1.简介
–网络爬虫(web crawler)是万维网浏览网页并按照一定规则提取信息的脚本或者程序,利用爬虫爬取信息就是模拟这个过程。用脚本模拟浏览器,向网站服务器发出浏览网页内容的请求,在服务器检验成功后,返回网页信息,并提取自己需要的数据,最后将提取到的数据保存。
- 使用requests库发起请求
- 服务器检验请求的原因:大量爬虫请求会造成服务器压力过大,可能使得网页响应速度变慢。所有网站一般会检验请求头中的User-Agent来判断发起请求的是不是机器人。我们可以通过自己设置UA来进行简单伪装(fake_useragent库)。也有网站设置有robots.txt来声明对爬虫的限制。
- 使用BeautifulSoup库和正则表达式来解析网页并提取数据。
- 根据数据格式的不同将内容保存在不同的文件( TXT, CSV…)中,对数据量大的内容,可以选择存入数据库(pandas库)。
- 深入传输原理通过HTTP协议了解。
2.入门实践
–2.1请求网页数据
—-1.发起请求
> import requests
>
> url = 'http://www.douban.com'
> # requests库的get方法,向URL(统一资源定位符)发起请求
> # 并将服务器返回内容存入变量data
> data = requests.get(url)
> print(data.text)
> # 运行结果是返回网页内容—-2.设置UA进行伪装
> import requests
>
> # 该网站会返回关于请求头的信息,
> url = 'http://httpbin.org/get '
> data = requests.get(url)
> print(data.text)
> # 返回结果中可看到UA显示是python,显然在没有UA的伪装下
> # 很容易被服务器识别出,而有些网站会拒绝爬虫的访问请求(1)直接伪装
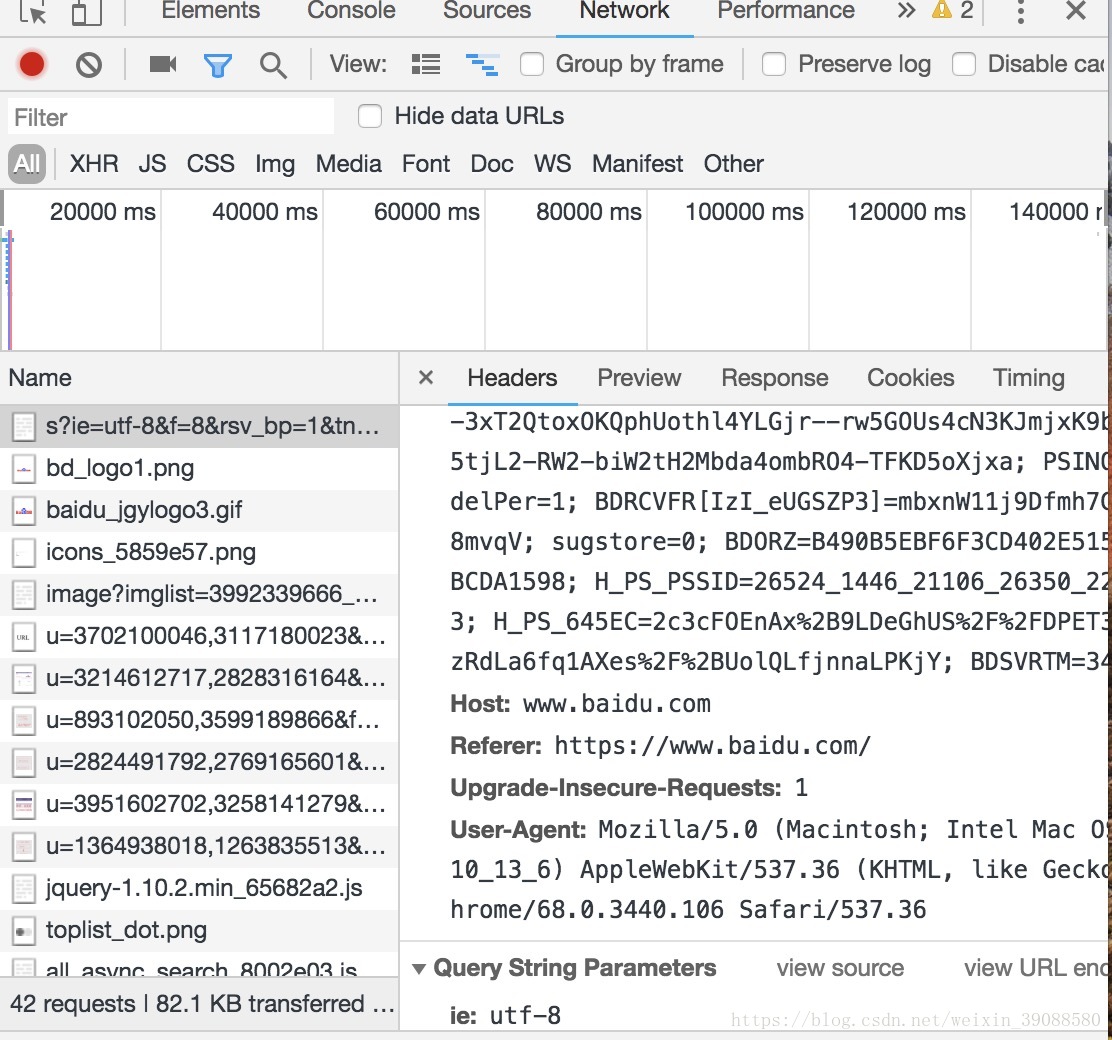
- 从网页查看User-Agent的方式
打开网页–>鼠标右键–>单击检查–>单击Network–>
刷新网页–>单击Header–>查看UA
- 实现
> import requests
>
> url = 'http://httpbin.org/get '
> headers = {'User-Agent': "复制网站的User-Agent粘贴至此处"}
> data = requests.get(url, headers=headers)
> print(data.text)
> # 运行结果可以看出此时的UA与浏览器的UA相同。(2)动态UA
> import requests
> from fake_useragent import UserAgent
>
> url = 'http://httpbin.org/get '
> ua = UserAgent()
> headers = ua.random
> data = requests.get(url, headers=headers)
> print(data.text)–2.2网页解析
提取自己需要的内容:在得到网页的整个内容之后进行解析。
以抓去豆瓣推出的新书信息为例。
> import requests
> from fake_useragent import UserAgent
> from bs4 import BeautifulSoup
>
> # 请求数据
> url = 'https://book.douban.com/latest'
> ua = UserAgent()
> headers = ua.random
> data = requests.get(url, headers=headers)
>
> # 解析数据
> # lxml是一种解析器
> soup = BeautifulSoup(data.text, 'lxml')
> # print(soup)
> # 针对BeautifulSoup对象,(从网页上)先检查元素,观察网页。
>
> # 观察到网页上的书籍按左右两边分布,按标签分别提取。
> # 查找网页中中标签为‘ul‘, 类为‘cover-col-4‘的第一个内容
> books_left = soup.find('ul', {'class': "cover-col-4 clearfix})
> # find_all用于找到所有符合要求的标签内容,返回一个列表
> # 这些返回的元素或列表元素都具有一些属性
> books_left = book_left.find_all('li')
> books_right = soup.find('ul', {'class': 'cover-col-4 pl20 clearfix'})
> books_right = book_right.find_all('li')
> # 对每一个图书去块进行相同的操作,获取图书信息
> img_urls = []
> titles = []
> ratings = []
> authors = []
> details = []
> for book in books:
> # 图书封面图片URL地址
img_url = book.find_all('a')[0].find('img').get('src')
img_urls = append(img_url)
> # 图书标题
title = book.find_all('a')[0].get_text()
titles = append(title)
> # 评价
rating = book.find('p', {'class': 'rating'}).get_text()
rating = rating.replace('\n', '').replace(' ', '')
ratings = append(rating)
> # 作者及出版信息
author = book.find('p', {'class': 'color-gray'}).get_text()
author = author.replace('\n', '').replace(' ', '')
authors = append(author)
> # 图书简介
detail = book.find_all('p')[2].get_text()
detail = detail.replace('\n', '').replace(' ', '')
>print("img_urls: ", img_urls)
>print("titles: ", titles)
>print("ratings: ", ratings)
>print("authors: ", authors)
>print("details: ", details)注:以上代码不是一下子就写出来的,是经过不断的测试的。在写程序的时候,要保证抓去的正确性,就是写抓去规则的时候,不断测试。有对包或函数的不理解及时查看官方文档或者百度理解。
–2.3数据存储
import pandas as pd
# DtaFrame数据框是一种数据存储的格式
result = pd.DataFrame()
result['img_urls'] = img_urls
retult['authors'] = authors
# 将对应数据填充至数据框
# 调用to_csv方法,将DataFrame直接转化为CSV格式
# CSV格式简单清晰,且可被大部分第三方库直接调入
result.to_csv('result.csv', index=None)–2.4小结
完整的数据爬取流程:请求并获取网页数据,解析网页提取有价值的数据,以及存储爬取的数据。整理代码为:
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import pandas as pd
# 请求并获取网页数据
def get_data():
url = 'https://book.douban.com/latest'
# 隐藏请求身份
ua = UserAgent()
headers = ua.random
data = requests.get(url, headers=headers)
# print(data.text)
return data
# 解析数据提取有价值的数据
def parse_data(data):
# 将网页数据转为BeautifulSoup对象,并将该对象命名为soup
soup = BeautifulSoup(data.text, "lxml")
# print(soup)
# 解析操作是针对BeautifulSoup对象:先检查元素,观察网页
# 观察到网页上的书籍是按左右两边分布,按照标签分别提取
# 获取左半边书籍列表内容;提取左边列表所有书籍的内容
# 'ul'是标签, 'class'索引'cover-col-4 clearfix'
books_left = soup.find('ul', {'class': 'cover-col-4 clearfix'})
books_left = books_left.find_all('li')
books_right = soup.find('ul', {'class': "cover-col-4 pl20 clearfix"})
books_right = books_right.find_all(" li")
# 将所有单个图书信息块存储到一个列表中,便于后续统一操作
books = list(books_left) + list(books_right)
# 对每一个图书块进行相同的操作,获取图书信息
img_urls = []
titles = []
ratings = []
authors = []
details = []
for book in books:
# 图书封面图片url地址
img_url = book.find_all('a')[0].find('img').get('src')
img_urls.append(img_url)
# 由网页代码可以看出图片地址是在标签'a'第一个中
# 并通过索引[0]提取第一个a标签的内容
# get('src)是获取'src'对应的值,即为要找的url地址.
# 图书标题
title = book.find_all('a')[1].get_text()
titles.append(title)
# get_text()方法去除find对象中的html标签,返回纯文本
# 且纯文本中的换行和空格不易阅读,故以替换
# 评价星级
rating = book.find('p', {'class': 'rating'}).get_text()
rating = rating.replace('\n', '').replace(' ', '')
ratings.append(rating)
# 作者及出版社信息
author = book.find('p', {'class': 'color-gray'}).get_text()
author = author.replace('\n', '').replace(' ', '')
# 图书简介
detail = book.find_all('p')[2].get_text()
detail = detail.replace('\n', '').replace(' ', '')
details.append(detail)
print("img_urls: ", img_urls)
print("titles: ", titles)
print("ratings: ", ratings)
print("authors: ", authors)
print("details: ", details)
return img_urls, titles, ratings, authors, details
# 存储数据
def save_data(img_urls, titles, ratings, authors, details):
# 创建空的DataFrame数据框,便于数据的存储。数据框就是一种数据存取的格式
result = pd.DataFrame()
# 对应数据填制对应数据框
result['img_urls'] = img_urls
result['titles'] = titles
result['ratings'] = ratings
result['authors'] = authors
result['details'] = details
# 调用to_csv方法,将数据框直接转化为csv格式
# csv:格式简单清晰;大部分第三方库可直接导入csv格式文件
result.to_csv('result.csv', index=None)
# 开始爬取
def run():
data = get_data()
img_urls, titles, ratings, authors, details = parse_data(data)
save_data(img_urls, titles, ratings, authors, details)
# 一般写法:作为程序入口,涉及多个文件想互相调用时起作用。
if __name__ == '__main__':
run()
注:soup.find() 和 soup.find_all ()的区别:
soup.find()只返回第一个符合条件的对象,后直接跟.text
或get_text()来获取标签中的文本;soup.find_all()找到
所有符合条件的结果与soup.select()相同,返回列表。
在测试过程中的多余的print代码注释掉,以免影响程序效率。
本人为小菜鸟,其中可能会有些小错误,望指出。