转载自:https://blog.csdn.net/liubenlong007/article/details/54695167
更多学习和免费学习视频请关注公众号:Java编程指南
elasticsearch术语简介
Elasticsearch是一个分布式的文档(document)存储引擎。它可以实时存储并检索复杂数据结构——序列化的JSON文档
当然,我们不仅需要存储数据,还要快速的批量查询。虽然已经有很多NoSQL的解决方案允许我们以文档的形式存储对象,但它们依旧需要考虑如何查询这些数据,以及哪些字段需要被索引以便检索时更加快速。
在Elasticsearch中,每一个字段的数据都是默认被索引的。也就是说,每个字段专门有一个反向索引用于快速检索。而且,与其它数据库不同,它可以在同一个查询中利用所有的这些反向索引,以惊人的速度返回结果。
本文我们将探讨如何使用API来创建、检索、更新和删除文档
索引
在Elasticsearch中存储数据的行为就叫做索引(indexing)
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields- 1
- 2
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
倒排索引
传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。具体倒排索引后续再讲。
文档
什么是文档?简单来讲,一个文档就对应于关系型数据库中的一张表,field对应于数据库中的一个字段。可以参考《Elasticsearch学习笔记(二)Elasticsearch入门》中的对应关系。
- 文档元数据
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
_index |
文档存储的地方 |
_type |
文档代表的对象的类 |
_id |
文档的唯一标识 |
来看一下之前存入数据库中的数据,在我们存入数据的基础上,Elasticsearch额外添加了这三个字段:
- 索引名字必须是全部小写,不能以下划线开头,不能包含逗号。事实上,我们的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。
_type的名字可以是大写或小写,不能包含下划线或逗号- 当创建一个文档,你可以自定义
_id,也可以让Elasticsearch帮你自动生成。 - 元数据不仅仅只有3个,还有很多,后续再讲
创建索引
自定义ID
我们创建一个员工目录,我们将进行如下操作:
- 为每个员工的文档(document)建立索引,每个文档包含了相应员工的所有信息。
- 每个文档的类型为
employee。 employee类型归属于索引megacorp。megacorp索引存储在Elasticsearch集群中。
其实一条curl命令即可完成新建索引的工作:
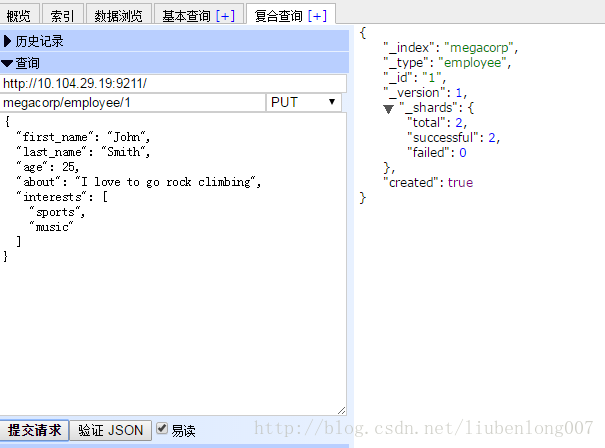
curl -XPUT 'http://10.104.29.19:9211/megacorp/employee/1' -d '
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'但是直接这样请求报错:index_not_found_exception,那我们就先创建一个index: curl -XPUT 'http://10.104.29.19:9211/megacorp/'
结果:
[root@vm-29-19-pro01-bgp config]# curl -XPUT 'http://10.104.29.19:9211/megacorp/'
{"acknowledged":true}然后在执行上面的创建索引命令即可。
当然除了直接用curl命令,也可以使用head插件:
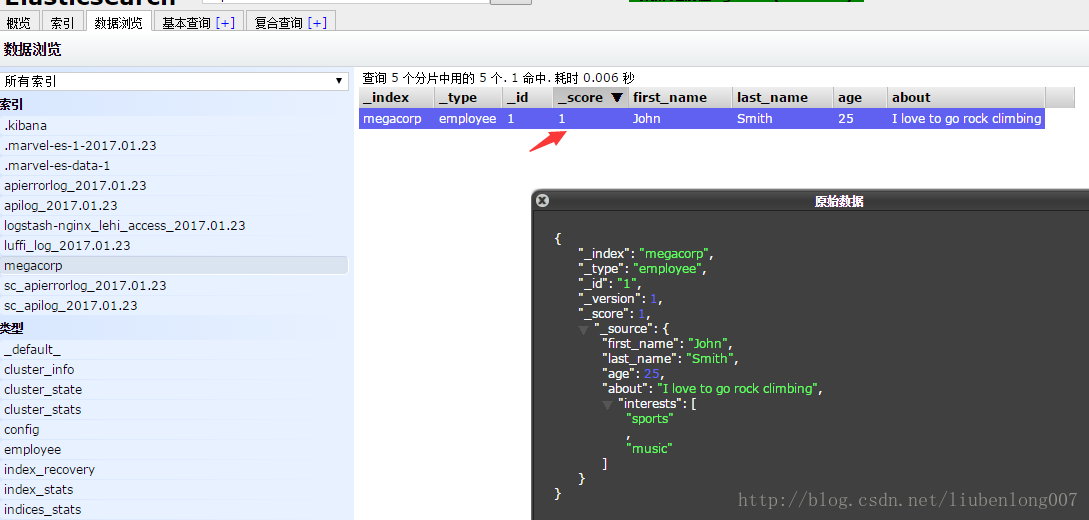
让我们来看下生成的索引:
可以看到elasticsearch自动添加了一个_score,score是评分相关的,是搜索引擎中很重要的一个参数。关于score后续再讲。
还有一个_version,Elasticsearch中每个文档都有版本号,每当文档变化(包括删除)都会使_version增加。后续我们将探讨如何使用_version号确保你程序的一部分不会覆盖掉另一部分所做的更改(多版本并发控制,线程安全)。
让ES自动生成ID
想让ES自动生成ID简单,只需要使用POST即可:
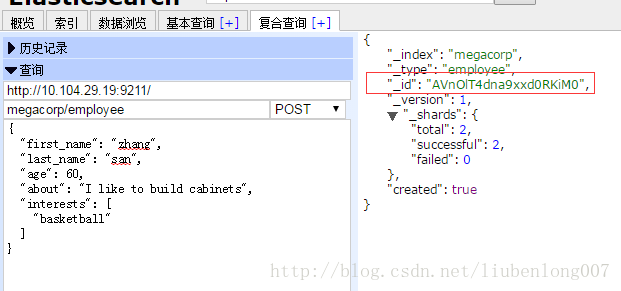
自动生成的ID有22个字符长,URL-safe, Base64-encoded string universally unique identifiers, 或者叫 UUIDs。
查询索引
简单查询
可以使用curl命令直接查询
[root@vm-29-19-pro01-bgp config]# curl -i -XGET '10.104.29.19:9211/megacorp/employee/1'
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 205
{"_index":"megacorp","_type":"employee","_id":"1","_version":1,"found":true,"_source":{"first_name":"John","last_name":"Smith","age":25,"about":"I love to go rock climbing","interests":["sports","music"]}}也可以使用head插件来查:
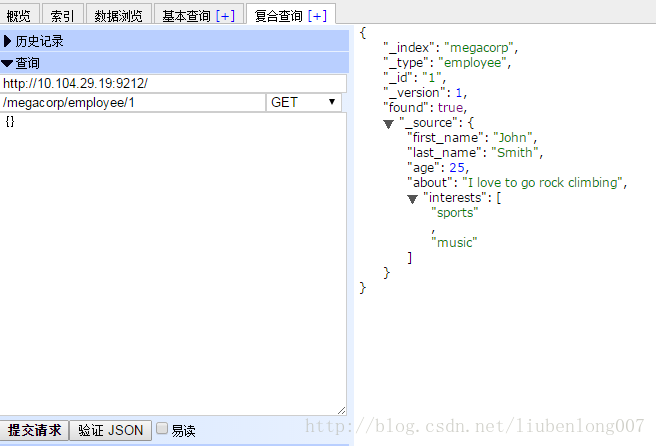
GET请求返回的响应内容包括
{"found": true}。这意味着文档已经找到。如果我们请求一个不存在的文档,依旧会得到一个JSON,不过found值变成了false。我们通过HTTP方法
GET来检索文档,同样的,我们可以使用DELETE方法删除文档,使用HEAD方法检查某文档是否存在。如果想更新已存在的文档,我们只需再PUT一次。
检查索引是否存在
一种方式是通过上面的查询返回结果中的found字段判断,另一种是通过查看curl的返回头部信息(其实当found=false时就会返回404错误码):
[root@vm-29-19-pro01-bgp whatslive-api]# curl -i -XHEAD http://10.104.29.19:9211/website/blog/124
HTTP/1.1 404 Not Found
es.resource.id: website
es.resource.type: index_expression
es.index: website
Content-Type: text/plain; charset=UTF-8
Content-Length: 0带参数查询
/megacorp/employee/_search
接下来除非特殊情况,就不截图了,还是直接列出请求和结果比较好。
请求curl -i -XGET '10.104.29.19:9211/megacorp/employee/_search'
结果:
{
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.0,
"hits": [{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1.0,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": ["music"]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1.0,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": ["sports",
"music"]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_score": 1.0,
"_source": {
"first_name": "Douglas",
"last_name": "Fir",
"age": 35,
"about": "I like to build cabinets",
"interests": ["forestry"]
}
}]
}
}查询结果中有集群的信息shards和命中数,也就是查询结果数。
- 搜索姓氏中包含“Smith”的员工
curl -XGET '10.104.29.19:9211/megacorp/employee/_search?q=last_name:Smith'
或head插件中:
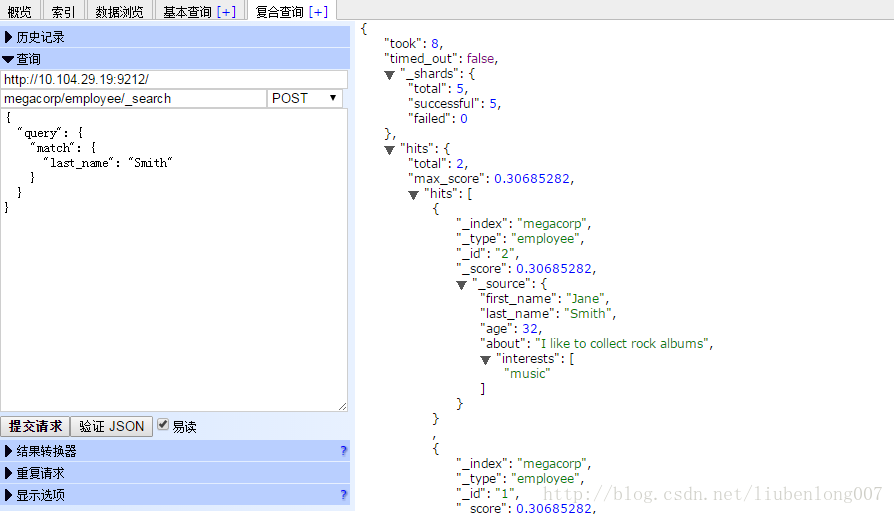
DSL(Domain Specific Language特定领域语言)
DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。其实上面使用head插件截图的查询方式就是DSL。
复杂查询
复杂查询一般使用DSL来构建
我们查询“last_name=Smith并且30岁以上的员工”
{
"query": {
"filtered": {
"filter": {
"range": {
"age": {
"gt": 30
}
}
},
"query": {
"match": {
"last_name": "Smith"
}
}
}
}
}- 这部分查询属于区间过滤器(range filter),它用于查找所有年龄大于30岁的数据——
gt为”greater than”的缩写。 - 这部分查询与之前的
match语句(query)一致。
结果:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.30685282,
"hits": [{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.30685282,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": ["music"]
}
}]
}
}只查询一部分字段
- 只显示数据,不显示其他额外信息
megacorp/employee/1/_source
{
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": ["sports",
"music"]
}- 只查询一部分字段
megacorp/employee/1?_source=about,age
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"age": 25,
"about": "I love to go rock climbing"
}
}全文搜索
在关系型数据库中想要进行全文搜索比较困难,当然现在MySQL最新版本已经支持全文索引了,不过性能还有待考究。
示例:搜索所有喜欢“rock climbing”的员工
{
"query": {
"match": {
"about": "rock climbing"
}
}
}查询出两条结果:
{
"took": 25,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.16273327,
"hits": [{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.16273327,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": ["sports",
"music"]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.016878016,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": ["music"]
}
}]
}
}结果分析:
默认情况下,Elasticsearch根据结果相关性评分来对结果集进行排序,所谓的「结果相关性评分」就是文档与查询条件的匹配程度[上面搜索结果中的_score字段]。很显然,排名第一的John Smith的about字段明确的写到“rock climbing”。
但是为什么Jane Smith也会出现在结果里呢?原因是“rock”在她的abuot字段中被提及了。因为只有“rock”被提及而“climbing”没有,所以她的_score要低于John。
短语搜索
短语搜索的意思就是要求要搜索的短语完全匹配。上面的查询结果中
id=2的员工就没有完全匹配,因为其about字段中并没有包含climbing。要想全部匹配只需要使用match_phrase即可
{
"query": {
"match_phrase": {
"about": "rock climbing"
}
}
}搜索结果中只剩下了id=1的记录.
高亮我们的搜索
如果直接使用lucene进行高亮搜索的话,还要写一段代码来实现(当然这样做自由度更高),使用elasticsearch则只需要简单的命令即可
{
"query": {
"match_phrase": {
"about": "rock climbing"
}
},
"highlight": {
"fields": {
"about": {}
}
}
}在查询的时候添加highlight参数,再返回结果中会增加一个highlight字段,里面的内容是高亮的数据:增加了<em>标识。
{
"took": 145,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.23013961,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": ["sports",
"music"]
},
"highlight": {
"about": ["I love to go <em>rock</em> <em>climbing</em>"]
}
}]
}
}聚合aggregations
先忽略语法,简单看看输出结果,语法后续再讲
查询员工中相同共同点及人数
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}会在原有结果基础上添加一个aggregations字段:
"aggregations": {
"all_interests": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [{
"key": "music",
"doc_count": 2
},
{
"key": "forestry",
"doc_count": 1
},
{
"key": "sports",
"doc_count": 1
}]
}
}从上面结果可以看出,喜欢music的有2人,喜欢sports的有1人,喜欢forestry的有1人。
当然我们也可以添加其他查询条件,比如统计”last_name=smith”的员工中相同爱好及人数
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}此时查询结果中就只剩下last_name=smith的数据了。
"aggregations": {
"all_interests": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [{
"key": "music",
"doc_count": 2
},
{
"key": "sports",
"doc_count": 1
}]
}
}聚合也允许分级汇总。例如,让我们统计每种兴趣下职员的平均年龄:
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}结果:
"aggregations": {
"all_interests": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [{
"key": "music",
"doc_count": 2,
"avg_age": {
"value": 28.5
}
},
{
"key": "sports",
"doc_count": 1,
"avg_age": {
"value": 25
}
}]
}
}可以看到返回结果中多了“avg_age”平均年龄字段。
请求参数中的
avg_age是我们自己定义的
更新文档
记住lucene中文档是不可以被修改的,修改文档的过程其实是一个新建一个文档并且version+1,并将旧的文档标记为删除,之后会被清理掉。
我们把之前创建的文档id=1的年龄改为33岁:
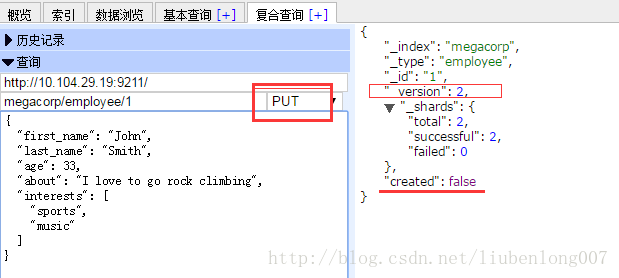
从上面的结果中可以看得version变为了2,并且created=false,因为之前应存在id=1的文档了
删除文档
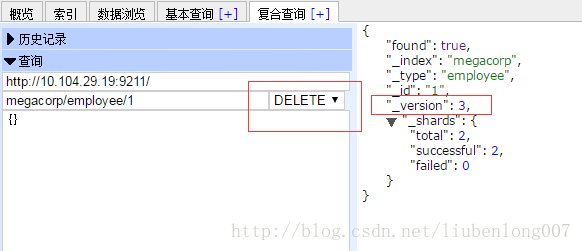
这里我们把id=1的文档删除,注意返回结果中version又加了1,这是因为这里的删除和更新一样,并没有立即删除,而是做了个标记,之后才会真正被删除。
更多学习和免费学习视频请关注公众号:Java编程指南
