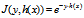梯度下降法、正则化与逻辑回归
1.梯度下降法
在介绍梯度下降法之前,先介绍下泰勒公式,泰勒公式的基本形式如下:
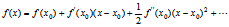
令x=wt+1,wt+1代表第t+1次参数向量的值;令x0=wt,代表第t次参数向量的值;其中w共有k个参数,w=[w1,w2,…,wk];令x-x0=△w,取一阶泰勒公式,则:

由于是梯度下降,所以f(wt+1)<=f(wt),所以

令函数f为损失函数J,则
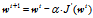
故第t+1次参数向量的值等于第t次参数向量的值减去损失函数偏导乘以学习率α。
2.正则化
为了防止过拟合,一般采用正则化,正则化一般分为L1正则化和L2正则化,分别为:
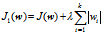
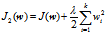
分别对wi求偏导,得

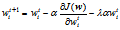
最后,
L1正则化: 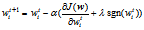
L2正则化: 
从以上公式可以发现L1正则化相对于L2正则化更容易产生数据稀疏性,并且两则都可以防止过拟合。
3.逻辑回归
逻辑回归是建立在线性回归的基础上,一般采用sigmoid函数来拟合,即

其中,wTx=w1x1+w2x2+…+wnxn,x为样本特征,w为样本对应的系数,在已知样本特征x和最终分类结果y(1或者0)的前提下,求系数w使得损失函数最小。
假设有m个样本,则相应的极大似然函数为
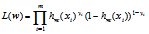
两边取对数化简得损失函数J(w),求使损失函数最小的参数:

经化简:
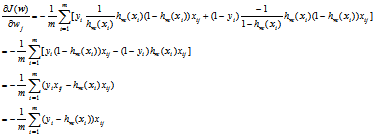
其中,xij是第i个样本xi的第j个特征,故
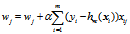
如果m是全量样本,则为批量梯度下降法(BGD),如果m是部分样本,则为小批量梯度下降法(MBGD),如果m是一个样本(每次迭代从所有样本中随机选择一个样本代替所有样本),则为随机梯度下降法(SGD)。所以,逻辑回归的m个样本对第j个特征的梯度为:
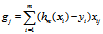
如果是一个样本,则
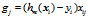
注:
1.sigmoid函数: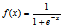 有如下性质:
有如下性质:
(1).
(2).
2.指数损失函数: