好久没有写博客了,每天都过得诚惶诚恐,遂下定决心今天无论如何都要写一篇。这篇博客主要总结和罗列一下,linux一些常用的性能分析指标,算是个扫盲吧。一般来说Linux系统出现了性能问题,都会有专门的运维人员去检查,但是开发人员还是需要掌握一些基础的命令,比如可以通过top、iostat、vmstat、netstat、sar等命令来初步查看和定位问题。这些命令都比较基础,很多网站上都能找到,我学习的时候也参照了很多资料,这里只列出这几个我用过的命令,后续还会增加。
Top
作用:能够实时显示系统中各个进程的资源占用状况。类似于Windows的任务管理器。
命令参数:
- d: 指定每两次屏幕信息刷新之间的时间间隔
- p: 通过指定监控进程ID来仅仅监控某个进程的状态
- q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行
- S: 指定累计模式
- s : 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险
- i: 使top不显示任何闲置或者僵死进程
- c: 显示整个命令行而不只是显示命令名
终端输入top,显示如下
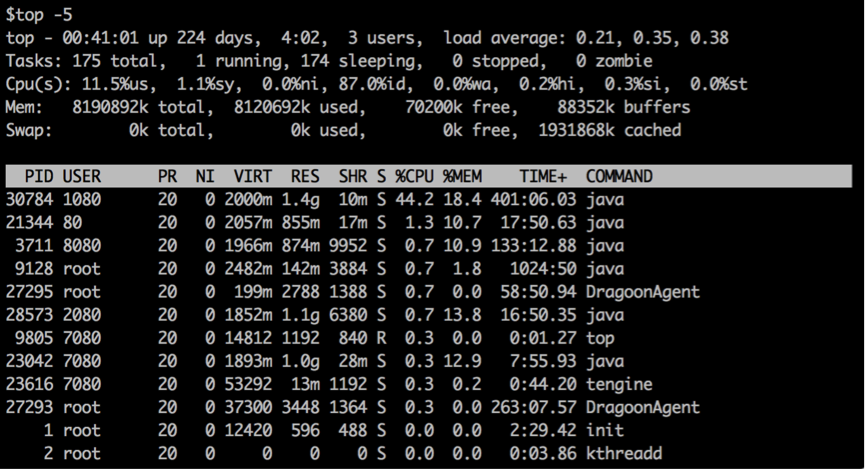
下面我们来看一下上图中这些参数的含义。
第一行:表示的项目依次为当前时间、系统启动时间、当前系统登录用户数目、平均负载(最近1,5,15分钟)。
第二行:显示的是所有启动的进程、目前运行的、挂起(Sleeping)的和无用(Zombie)的进程。
第三行:显示的是目前CPU的使用情况,包括系统占用的比例、用户使用比例、闲置(Idle)比例。
第四行:显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。
第五行:显示交换分区使用情况,包括总的交换分区、使用的、空闲的和用于高速缓存的大小。
第六行:显示的项目最多,内容如下:
| 命令 | 含义 |
|---|---|
| PID | 进程id |
| USER | 进程所有者的用户名 |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| SHR | 共享内存大小,单位kb |
| S | 进程状态:D=不可中断的睡眠状态;R=运行;S=睡眠;T=跟踪/停止; Z=僵尸进程 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| %MEM | 进程使用的物理内存百分比 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| COMMAND | 命令名/命令行= |
当你输入top之后,还可以根据你的需要进行排序,查看对应信息,如:
shift +M:按照内存使用进行排序
shift+P:按照cpu时间排序
shift+T:按照cpu累计使用时间
推荐参考资料性能优化
vmstat
作用:
虚拟内存的统计。vmstat可以实时监控cpu运行队列和系统关键的性能指标,如磁盘,上下文交换,cpu使用率等。
命令参数:
- -a:显示活跃和非活跃内存
- -f:显示从系统启动至今的fork数量
- -m:显示slabinfo
- -n:只在开始时显示一次各字段名称
- -s:显示内存相关统计信息及多种系统活动数量
- delay:刷新时间间隔。如果不指定,只显示一条结果
- count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷
- -d:显示磁盘相关统计信息
- -p:显示指定磁盘分区统计信息
- -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
- -V:显示vmstat版本信息
例子:
输入vmstat可以看到如下界面:

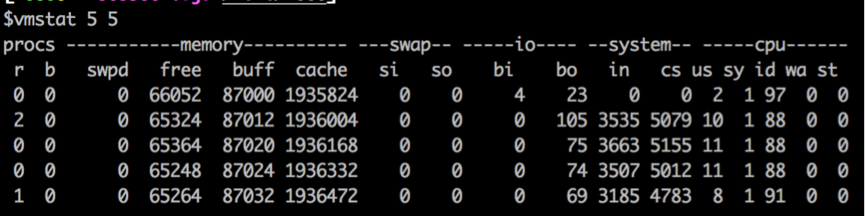
解释下图中各个参数的含义:
procs
r 列表示等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
memory
swpd 切换到内存交换区的内存数量,或者说是现在可用的交换内存(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示) ,空闲内存
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量。
so由内存交换区进入内存数量。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。如果bi,bo 长期不等于0,表示物理内存容量太小。
system
显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
cpu
表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比,如果id经常小于40,表示中央处理器的负荷很重
最好使用vmstat t [n]命令,例如 vmstat 5 5,表示在T(5)秒时间内进行N(5)次采样。如果只使用vmstat,无法反映真正的系统情况。如下:
iostat
顾名思义,iostat主要用于监控系统设备的IO负载情况。
如下:
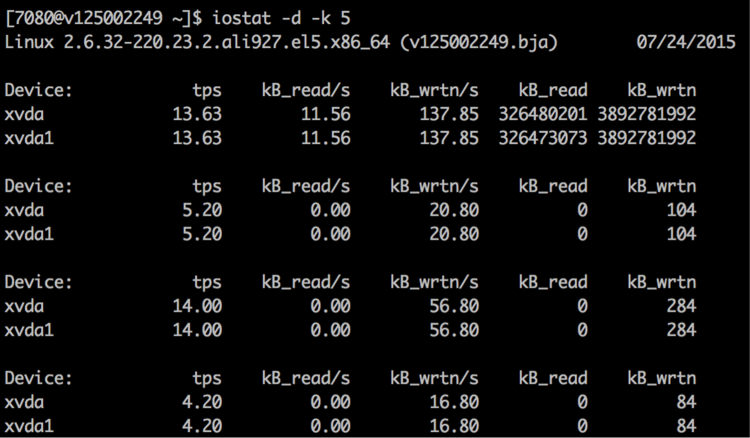
具体参数的含义可以参见iostat,这里写的比较详细。
Netstat
输入 man netstat可以看到解释:
Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Memberships) 等等。
这里找了一篇参考资料,总结的还是比较详细的:netstat
sar
sar这个命令还是比较复杂的,实际中用的还是比较广的。在命令行输入sar,可以看到下图:
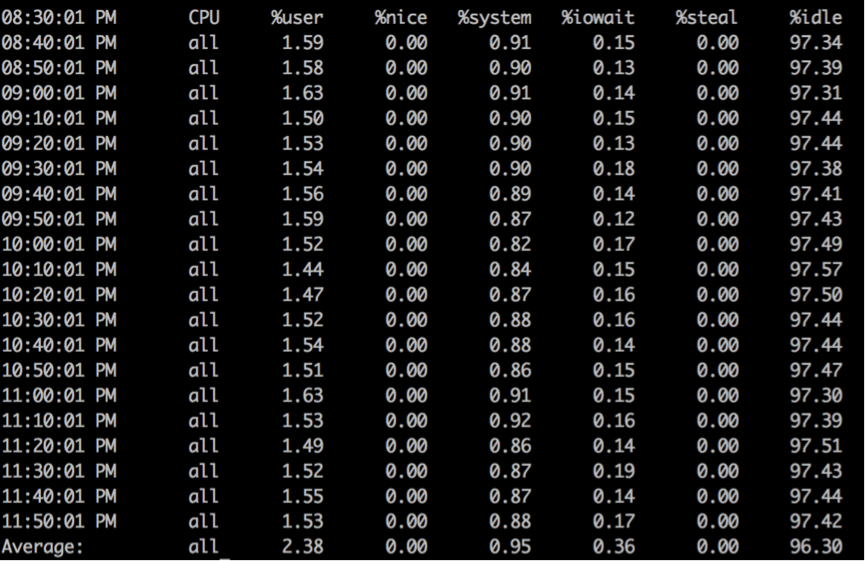
解释下参数:
%user : 用户模式下消耗的CPU时间的比例;
%nice:通过nice改变了进程调度优先级的进程,在用户模式下消耗的CPU时间的比例;
%system:系统模式下消耗的CPU时间的比例;
**%iowait:**CPU等待磁盘I/O而导致空闲状态消耗时间的比例。如果过高,表示存在I/O瓶颈。
*%steal:利用Xen等操作系统虚拟化技术时,等待其他虚拟CPU计算占用的时间比例;
**%idle:**CPU没有等待磁盘I/O等的空闲状态消耗的时间比例。
如果 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
如果 %idle 的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
Sar的命令太过复杂,我也没有什么实际的运维经验,所以我这里就列下参考资料吧:http://baike.baidu.com/view/2816483.htm (其实百度百科总结的还是很详细的嘛,O(∩_∩)O哈哈~)
好了,linux性能分析命令-扫盲篇暂时就先这样,等有了实际的例子再来分享下。平常没事,大家可以输入玩一玩,比较参数看多了就知道是神马意思了。