思维导图

概述
一个数据库是否存在性能问题,基本上在系统设计的时候就决定了,这个系统设计包括软件的设计、数据库的设计和硬件的设计.其中更细节的分类参考目录。
在一个系统的设计阶段,其中任何一个环节存在设计不当之处,都可能导致系统的性能下降,而系统的性能在多数情况下又反映为数据库的性能问题。
软件设计对数据库的影响
软件架构设计对数据库性能的影响
软件系统的架构对数据库的影响是非常直接的。 比如一套并发量非常大的系统,一般都会采用一套软件来搭建一个中间层,用来构建缓冲池,在数据库之前多大量的并发进行处理,以便于每次只有少数的用户连接到数据库中,其他的用户在缓冲池的队列中等待,同时,很多这种中间件软件还提供了负载均衡的功能。
Oracle自身也提供了一种MTS技术,很少用,大部分都是采用中间件服务。
软件代码的编写对数据库性能的影响
软件代码对数据库的影响,通常指的是应用程序中对数据库操作的代码部分对数据库产生的影响。
具体来讲就是SQL或者PL/SQL包。
SQL语句
SQL造成的影响
- 一种是 SQL语句本身在逻辑上就效率低下
- 另外一种SQL语句没有绑定变量。
性能底下的SQL语句,比如使用不合适的Hint,不合适的外关联,谓词的隐含转换,优化器的选择等等,特别是多表关联的情况下,影响更是显著。 它主要体现为SQL语句的执行收到了人为的约束,比如数据的访问方式(索引还是全表扫描),以及表关联方式的选择上.
人为的在SQL中加入Hint来约束SQL的执行计划
对于高版本的数据库(10g以上),CBO(基于成本的优化器)技术已经比较成熟,我们还是应该让数据库自己根据表、索引的统计分析信息来决定SQL的执行计划,因为表中的数据是变化的,人为强制的干预,必然会在某个时候出现问题。
不必要的外连接操作
外连接是一个代价非常昂贵的执行过程,如果业务需要,这种操作是必须的,但是有时候会出现人为的在SQL中使用不必要的外连接的情形,因为有的开发者担心遗漏一些数据而刻意使用它,让SQL执行计划变的非常耗时。
栗子
--创建t
create table t as select rownum a , rownum+100 b from dba_users u where rownum <10 ;
--批量向t表中写入10万数据,每5000次提交一次
begin
for i in 10 .. 100000 loop
insert into t (a, b) values (i, i);
if mod(i, 5000) = 0 then
commit;
end if;
end loop;
end;
--创建t2
create table t2 as select decode(mod(rownum ,2),0,rownum) c ,rownum+1000 d from dba_users u where rownum<10;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
查询
--左连接方式
select a, b, c, d
from t, t2
where t.a = t2.c(+)
and t2.d > 1000;
这个sql的含义是:得到t表上的所有行,然后用a和t2的c列关联,同时t2的d>1000
--内连接
select a, b, c, d
from t, t2
where t.a = t2.c
and t2.d > 1000;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
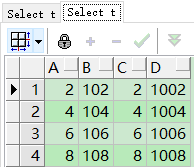
从结果集上看,这两条SQL是等价的,在这情况下,外连接其实是没有用的,是人为的在SQL里设定的限制。
不难发现t2.d>1000已经明确的指出,在结果集中,t2表的任何一行,c列都应该有值,也就是在这种情况下,根本不需要使用外连接,业务逻辑上讲,外连接在这里是多余的。 对数据库来讲,有时候在执行时可能会引起极大的性能差别。
CBO下优化器模式的选择
通常对已一种功能单一的数据库来讲,在实例设置一个优化器模式即可,比如OLAP系统,绝大多数的时候运行的是报表作业,执行的基本上是聚合类的SQL操作,比如group by ,这个时候把优化器模式设置为all_rows是恰当的。
而对于一些分页操作比较多的网站类数据库,设置成 first_rows会更好一些。
但是有些情况比较复杂,比如数据库上运行的基本是一个OLAP系统,所以优化器模式设置为ALL_ROWS,这样利于报表的快速完成。
同时,数据库上还有一些查询业务,查询的方式可以说是分页的,针对这种情况,在开发阶段就要考虑到这种情况,在SQL里通过Hint的方式将优化模式转换成FIRST_ROWS,这样既可以大大的提高数据的处理速度。
比如一次提取10条记录的分页查询:
select * from (
select /*+first_rows(10)*/
x.*, rownum rnum
from (select /* +first_rows(10)*/
a, b
from t
order by a) x
where rownum <= 10)
where rnum >= 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
尽管在SQL中认为的加入hint操作不是一个好主意,但是有的时候如果需要兼顾用户的其他操作,可以考虑这样的设定。 但前期要做一些测试工作,确保这样的优化能够带来性能上的提高,同时不会对数据库造成其他方面的影响。 这是系统设计阶段应该仔细考虑的一个问题。
没有绑定变量的SQL
对于这个话题,很多人存在一个误区,认为不使用绑定变量系统就要出问题一样,有时候绑定变量对性能的影响被夸大化了。
其实我们应该分析我们当前的系统的实际情况:比如数据库的用户连接用户很少,每个用户每天触发的查询操作也很少,同时我们的数据库主机8G内存,16个cpu, 硬解析对数据库的性能影响的微乎其微,完全可以忽略掉,因为我们的系统是一个OLAP系统。
实际上,至少对于OLAP系统(在线分析系统,通常是指这样的系统,数据库中存放着海量的数据,连接的用户很少,SQL基本上是用户生成报表的大查询)来说,即使没有绑定变量对数据库的影响也是有限的,甚至是完全没有必要的,因为只有少量的用户和少量的sql操作,数据库不需要花多少资源在SQL分析上面。
绑定变量的真正的用途是在OLTP系统,OLTP系统通常有这样的特点:
- 用户并发数很大,
- 用户的请求十分密集,
- 并且这些sql大多数是可以重复使用的。
试想一下,这些成千上万的SQL一遍又一遍的被数据库进行语法分析,予以分析,生成执行计划,数据库的压力该有多大?
如果一条SQL执行一遍之后就被缓存到数据库的内存(实际上是共享池里),后续所有的用户请求的同样的SQL,都是用共享池中的数据,biubiubiu~~~效率是不是提高很多?
所以,当你考察绑定变量对你的数据库的影响有多大时,先确定你的系统是OLAP还是OLTP系统。 当然现在很多数据库同事承担着这两种劫色,那么就需要分析数据库的性能情况了,比如做一个Statspack Report帮助你确定变量是否绑定,以及是否已对系统的性能构成了严重的影响。
PL/SQL包
如果你的程序里有PL/SQL包,请考虑使用存过来代替它 。
存过是经过成功编译后存放在数据库中的代码,执行起来的效率比程序代码中的PL/SQL包的效率高很多,因为它不需要做语法和语义的分析。
语法分析:数据库对sql进行检查,是否存在语法错误
语义分析:查看语句执行的对象是否存在,是否有操作权限等。
数据库的设计
除了一些必要的对象创建之外,还应该更多的考虑一些前瞻性的设计,以满足系统生命周期里的各方面的需求,不至于发生大的修改或者升级。
基本上看来,前期数据库的设计一个根基就是要弄清楚数据库的类型。
OLTP(在线事物处理系统) 数据库
OLTP更加强调数据库的内存效率,强调各种指标的命中率,强调绑定变量,强调并发。
OLTP用户并发数很多,数据库侧重对用户操作的快速响应,这是对数据库最重要的性能要求。
对于一个OLTP系统而言,数据库内存设计显得非常重要,如果数据都可以在内存中处理,无疑性能会提高很多, 有些对数据处理速度很高的系统,比如计费系统,已经差用了一些内存数据库,比如ORACLE的Times Ten.
内存设计通常是通过调整Oracle和内存相关的初始化参数实现的。
SGA的大小(Data Buffer ,Shared Pool),PGA的大小(排序区,Hash区等)
这些参数在OLTP的系统中显得至关重要。
OLTP数据块的变化非常频繁,SQL语句提交非常频发,
- 对于数据块来说,应该尽可能的让数据块保存在内存当中
- 对于SQL来说,尽可能的使用绑定变量来达到SQL的重用,减少物理IO和重复的SQL解析
关于初始化参数的设置,没有一个绝对的标准,先给出一个经验值 ,需要根据业务不断的测试和调整,已达到最佳的性能。
除了内存、没有绑定变量的SQL, 热块同样也会导致数据库性能的下降。
当一个块被多个用户同时读取的时候,oracle为了维护数据的一致性,需要使用latch来串行化用户的操作,当一个用户获取到了这个latch之后,其他的用户就需要被迫等待。 获取这个数据块的用户越多,等待就越明显,就造成了热块问题。
这种热块可能是数据块,也可能是回滚段。
对于数据块来讲,通常是数据块上的数据分部不均匀导致,如果是索引的数据块,可以考虑创建反向索引来达到重新分布数据的目的。
对于回滚段数据块,可以适当的增加几个回滚段来避免争用。
OLAP(在线分析系统)/DSS(决策支持系统) 数据库
OLAP着强调数据分析,强调SQL的执行时长,强调磁盘IO,强调分区等等
内存的优化对于OLAP的影响很小,因为海量的数据全部在内存中操作是很困难的,同时也是完全没必要的,因为这些数据块很少重用,缓存起来意义不大,倒是物理IO相当大,这种系统的瓶颈往往在磁盘IO上。
SQL优化
对于OLAP,SQL优化显得非常重要,打个比方,一个表只有几千条数据,无论是全表扫描还是使用索引,对我们来讲差异其实很小。
但是当数据量达到几亿或者几十亿甚至更多的时候,全表扫索引可能导致极大的性能差异。因此SQL优化非常重要。
分区
同样的,分区技术在OLAP系统中也很重要。 这种重要性主要体现在数据的管理上。
至于分区在性能上的影响,不能一概而论,认为分区的性能始终好于非分区,这个结论也是不成立的。
当查询范围正好落在某个分区时候
这个时候,分区的效率自然是高于没有分区的,因为SQL咋有分区的表上只扫一个分区的数据,而对于没有分区的数据,需要扫描整个表。
当查询范围跨越几个分区时
这个时候分区可能并不绝对是最优的,分区索引并不一定比全局索引在任何时候都快,有时候反而会更慢
数据库的硬件设计
数据库的硬件设计在性能上主要体现在:
- CPU
- I/O
- 负载情况
存储容量
占用空间的对象可以在DBA_SEGMENTS视图中查找到,数据库的空间分配是以段的形式分配的,凡是段对象都要占用空间,包括表 视图 索引 物化视图 其他一些大对象等。
存储的物理设计
现在越来越多的数据库选择 SAN结构,这是一个扩展性非常好的存储设计。
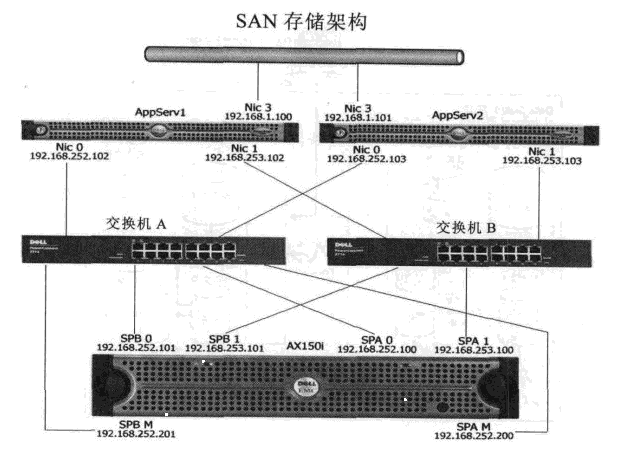
维护人员不仅要懂得磁盘阵列的技术,同时还要掌握SAN交换机的相关技术。
数据的安全
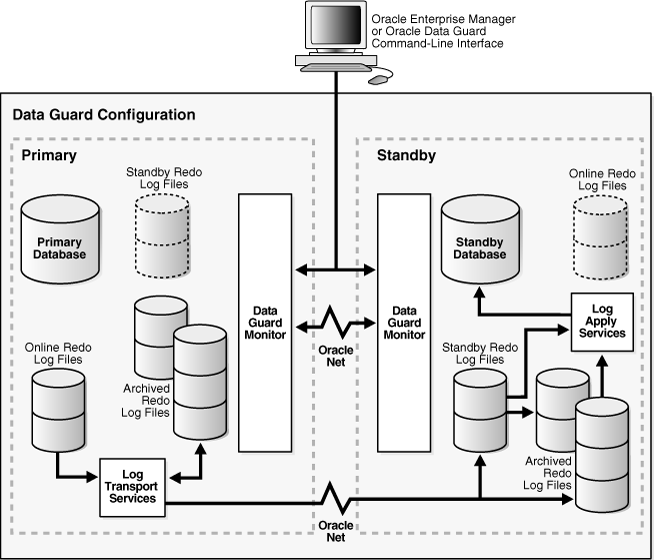
Data Guard 结构
https://docs.oracle.com/cd/B19306_01/server.102/b14239/toc.htm
如果用户对数据的安全性要求性非常高,并且对系统宕机的时间要求很高,可以考虑使用Data Guard设计结构。
当主数据库出现故障时,维护人员可以最短时间启用备用数据库,确保业务的正常进行。
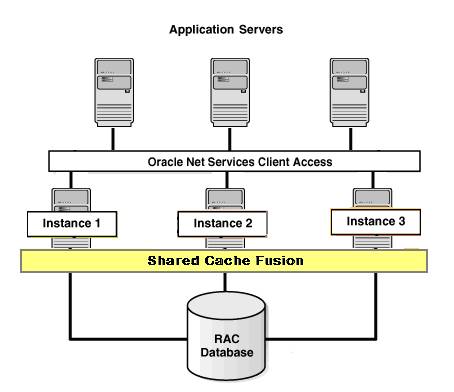
RAC结构
RAC结构和Data Guard结构分属于不同级别的安全设计,
Data Guard 能够保证数据不丢失或者尽可能少丢失,Data Guard 的数据库级别是一个冗余结构。
而RAC则是实例级的一个冗余结构,它能够保证数据库在一个实例出现故障后,用户可以无缝地由另外一个实例接管。
现在很多业务连续性很高的系统都采用RAC+Data Guard的 数据库结构设计。
Rman+归档方式
Rman+归档的备份方式,相对于RAC+Data Guard来看,
优势是成本低廉,并且能够保证数据的完整,当数据库损坏时,可以恢复到备份的时间点。
缺点是 需要较长的宕机时间。
exp/imp , expd/impdp
这两种方式更像是数据传递或者数据保存,它不能保证数据的安全。
总结
首先弄清楚系统是OLAP还是OLTP
系统并发量,OLTP作为一个重要的因素
高并发可能导致
- 系统资源严重被使用,系统过负荷运行
- 严重的等待事件,比如热块和锁定
SQL代码的编写,SQL优化的技巧
数据库的设计
存储的设计