本文主要参考:
Input Pipeline Performance Guide
本文结构:
- 一、TF输入方法现状
- 二、对Pipline的一些见解
- 三、使用tf.data API
- 1、Input Pipeline Structure
- 2、Optimizing Performance
- 改进1:使用pipline
- 改进2:Parallelize Data Transformation
- 改进3:Parallelize Data Extraction
- 3、Performance Considerations
一、TF输入方法现状:
在使用TF搭建深度学习网络进行训练时,如何优雅的把数据处理后送给模型是一个需要严肃考虑的事情,TF在这些年的发展过程中,大致形成了以下三种方法:
1.使用placeholder,然后定义feed_dict将数据feed进placeholder中,典型应用就是经典的2016Faster-RCNN_TF源码,这也是我们在入门tf的教程中广泛使用的。这个方法比较灵活,在训练数据比较小时,可以一次把所有数据读入内存,然后分batch进行feed;当数据量较大时,也可以建立一个generator,然后一个batch一个batch的从硬盘中读入并feed入placeholder。它的优点是灵活,它的缺点:
- in general feed_dict does not provide a scalable solution(不提供可扩展的解决方案?怎么理解?)
- 当只有一个GPU时,它与tf.data API的性能表现非常接近,当有多个GPU时就不如后者了。
官方建议:
Our recommendation is to avoid using feed_dict for all but trivial examples
(练练手玩玩就得了)
In particular, avoid using feed_dict with large inputs:
(在大数据量时,feed_dict往往导致次优的性能表现)
# feed_dict often results in suboptimal performance when using large inputs.
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
2、使用TensorFlow的queue_runner,这种方法是使用Python实现的,其性能受限于C++ multi-threading ,而tf.data API使用了C++ multi-threading ,大大降低了overhead。
3、tf.data API
The tf.data API is replacing queue_runner as the recommended API for building input pipelines
它正在取代queue_runner成为官方推荐的构建Pipeline的API,它经常与tf.estimator.Estimator一起使用,在2018tensorflow-deeplab-v3-plus中已经开始使用。
二、对Pipline的一些见解:
最初接触pipline实在FPGA中。数据从硬盘读取和预处理都余姚使用cpu处理与gpu无关,gpu的运行必须在cpu跑完所有程序之后才开始,gpu和cpu的状态如下图,在一个运行时,另一个处在空闲状态,非常浪费资源。
我们可以使用pipline技术,在GPU训练时,cpu去准备下一batch的数据。
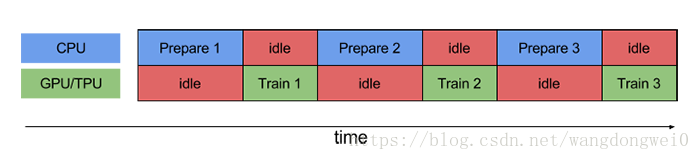

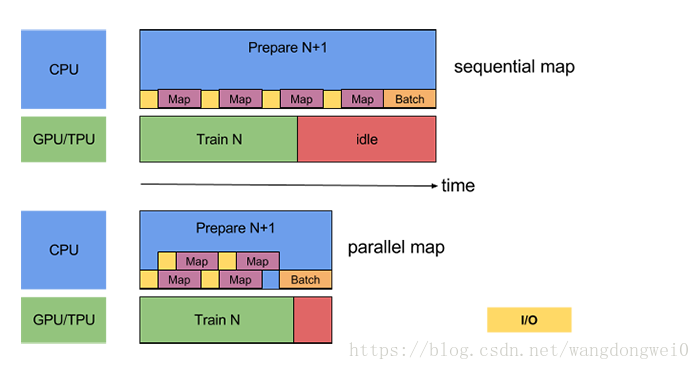
以现在CPU都是多核的,如果数据的读取、预处理1、预处理2等都跑在一个cpu上,那么其他cpu也是空闲的,所以把数据的读取、预处理1、预处理2都分别分配在不同的cpu上,可以最大限度的减少idle的时间。
那我们该如何使用pipline机制呢?
如果一个training step需要使用n个elements,那么设置tf.data.Dataset.prefetch(n),这个之后再说。
三、使用tf.data API
1、Input Pipeline Structure
一个典型的tf训练输入管道可以概括为ETL过程:
- Extract: Read data from persistent storage
- Transform: Use CPU cores to parse and perform preprocessing operations on the data
- Load: Load the transformed data onto the accelerator device(s)
当使用 tf.estimator.Estimator 时,前两个步骤在input_fn中实现,input_fn又被传入 tf.estimator.Estimator.train,我们先建立个简单的input_fn
def input_fn():
files = tf.data.Dataset.list_files("/path/to/dataset/train-*.tfrecord")
dataset = files.interleave(tf.data.TFRecordDataset)
dataset = dataset.shuffle(buffer_size=FLAGS.shuffle_buffer_size)
dataset = dataset.map(map_func=parse_fn)
dataset = dataset.batch(batch_size=FLAGS.batch_size)
return dataset
2、Optimizing Performance
我们已经建立了简单的input_fn,现在需要优化它。
注意上面的程序是没有使用pipline的,cpu和gpu的利用率不高,原因参考第二部分:对pipline的一些见解。
改进1:使用pipline
change:
dataset = dataset.batch(batch_size=FLAGS.batch_size)
return dataset
to:
dataset = dataset.batch(batch_size=FLAGS.batch_size)
return dataset
改进2:Parallelize Data Transformation
翻译过来就是在CPU上并行(多线程)与处理数据
将不同的预处理任务分配到不同的cpu上,实现并行加速的效果
change:
dataset = dataset.map(map_func=parse_fn)
to:
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)
num_parallel_calls一般设置为cpu内核数量,如果设置的太大反而会降低速度。
如果batch size成百上千的话,并行batch creation可以进一步提高pipline的速度,tf.data API
提供 tf.contrib.data.map_and_batch函数,可以把map和batch混在一起来并行处理。
change:
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)
dataset = dataset.batch(batch_size=FLAGS.batch_size)
to:
dataset = dataset.apply(tf.contrib.data.map_and_batch(
map_func=parse_fn, batch_size=FLAGS.batch_size))
改进3:Parallelize Data Extraction
单机时使用pipline可以取得很好的效果,但是在分布式训练时pipline则可能会成为bottleneck。
differences between local and remote storage:
- Time-to-first-byte: remote storage的延时较长。
- Read throughput: 虽然remote storage具有较大的带宽,但是读取一个文件时只能使用很小的一部分带宽。
除此之外,即使把远端的数据读到了本地,还是需要串并转换和解码(TCP/IP协议),这些都会增加overhead。相比本地存储的数据,如果不进行有效的prefetch分布式训练的overhead会更长。
为了减轻数据导出的overhead,tensorflow提供了tf.contrib.data.parallel_interleave(并行交错) ,The number of datasets to overlap(dataset的重叠) can be specified by the cycle_length argument.
cycle_length = 2
change:

dataset = files.interleave(tf.data.TFRecordDataset)
to:
dataset = files.apply(tf.contrib.data.parallel_interleave(
tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_readers))
3、Performance Considerations
在把数据传给网络前,我们进行一些预处理,比如map、batch、cache、prefetch、interleave、shuffle等等,这些操作的前后顺序也会影响处理速度。
-
map 和 batch
Invoking the user-defined function passed into the map transformation has overhead related to scheduling and executing the user-defined function. Normally, this overhead is small compared to the amount of computation performed by the function. However, if map does little work, this overhead can dominate the total cost. In such cases, we recommend vectorizing the user-defined function (that is, have it operate over a batch of inputs at once) and apply the batch transformation before the map transformation. -
Map and Cache
The tf.data.Dataset.cache transformation can cache a dataset, either in memory or on local storage. If the user-defined function passed into the map transformation is expensive, apply the cache transformation after the map transformation as long as the resulting dataset can still fit into memory or local storage. If the user-defined function increases the space required to store the dataset beyond the cache capacity, consider pre-processing your data before your training job to reduce resource usage. -
Map and Interleave / Prefetch / Shuffle
A number of transformations, including interleave, prefetch, and shuffle, maintain an internal buffer of elements. If the user-defined function passed into the map transformation changes the size of the elements, then the ordering of the map transformation and the transformations that buffer elements affects the memory usage. In general, we recommend choosing the order that results in lower memory footprint, unless different ordering is desirable for performance (for example, to enable fusing of the map and batch transformations). -
Repeat and Shuffle
The tf.data.Dataset.repeat transformation repeats the input data a finite (or infinite) number of times; each repetition of the data is typically referred to as an epoch. The tf.data.Dataset.shuffle transformation randomizes the order of the dataset’s examples.
If the repeat transformation is applied before the shuffle transformation, then the epoch boundaries are blurred. That is, certain elements can be repeated before other elements appear even once. On the other hand, if the shuffle transformation is applied before the repeat transformation, then performance might slow down at the beginning of each epoch related to initialization of the internal state of the shuffle transformation. In other words, the former (repeat before shuffle) provides better performance, while the latter (shuffle before repeat) provides stronger ordering guarantees.
When possible, we recommend using the fused tf.contrib.data.shuffle_and_repeat transformation, which combines the best of both worlds (good performance and strong ordering guarantees). Otherwise, we recommend shuffling before repeating.
四、Summary of Best Practices
Here is a summary of the best practices for designing input pipelines:
Use the prefetch transformation to overlap the work of a producer and consumer. In particular, we recommend adding prefetch(n) (where n is the number of elements / batches consumed by a training step) to the end of your input pipeline to overlap the transformations performed on the CPU with the training done on the accelerator.
Parallelize the map transformation by setting the num_parallel_calls argument. We recommend using the number of available CPU cores for its value.
If you are combining pre-processed elements into a batch using the batch transformation, we recommend using the fused map_and_batch transformation; especially if you are using large batch sizes.
If you are working with data stored remotely and / or requiring deserialization, we recommend using the parallel_interleave transformation to overlap the reading (and deserialization) of data from different files.
Vectorize cheap user-defined functions passed in to the map transformation to amortize the overhead associated with scheduling and executing the function.
If your data can fit into memory, use the cache transformation to cache it in memory during the first epoch, so that subsequent epochs can avoid the overhead associated with reading, parsing, and transforming it.
If your pre-processing increases the size of your data, we recommend applying the interleave, prefetch, and shuffle first (if possible) to reduce memory usage.
We recommend applying the shuffle transformation before the repeat transformation, ideally using the fused shuffle_and_repeat transformation.
参考文献:
1、https://www.jianshu.com/p/f580f4fc2ba0
2、https://www.tensorflow.org/performance/datasets_performance