继承体系中的作用域:
(1)当基类构造函数不带参数时, 派生类不一定需要定义构造面数, 系统会自动的调用基类的无参构造函数; 然而当基类的构造函数那怕只带有一个参数, 它所有的派生类都必须定义构造函数,
甚至所定义的派生类构造函数的函数体可能为空, 它仅仅起参数的传递作用, " Third(int x, int y)", 派生类 Third就不使用参数x和y, x和y只是被传递给了要调用的基类构造函数Second
(2)若基类使用默认构造函数或不带参数的构造函数, 则在派生类中定义构造函数时可略“:基类构造函数名(参数表)”, 此时若派生类也不需要构造函数, 则可不定义构造函数
(3)如果派生类的基类也是一个派生类, 每个派生类只需负责其直接基类数据成员的初始,依次上溯。
这篇博客写的较清楚继承机制:https://blog.csdn.net/dream_1996/article/details/68931347
继承内存分布
/** 普通继承(没有使用虚基类) */ // 基类A class A { public: int dataA; }; class B : public A { public: int dataB; }; class C : public A { public: int dataC; }; class D : public B, public C { public: int dataD; };
我们可以看到class D的内存布局如下:

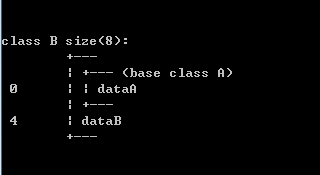
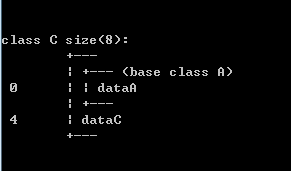
从类D的内存布局可以看到A派生出B和C,B和C中分别包含A的成员。再由B和C派生出D,此时D包含了B和C的成员。这样D中就总共出现了2个A成员。大家注意到左边的几个数字,这几个数字表明了D中各成员在D中排列的起始地址,D中的五个成员变量(B::dataA、dataB、C::dataA、dataC、dataD)各占用4个字节,sizeof(D) = 20。
为了跟后文加以比较,我们再来看看B和C的内存布局:
虚继承内存分布
/** 虚继承(虚基类) */ #include <iostream> // 基类A class A { public: int dataA; }; class B : virtual public A { public: int dataB; }; class C : virtual public A { public: int dataC; }; class D : public B, public C { public: int dataD; };
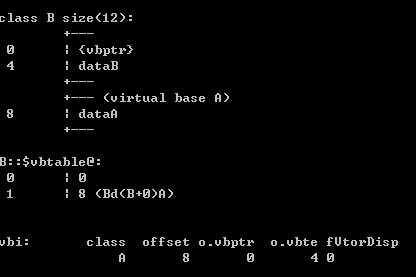
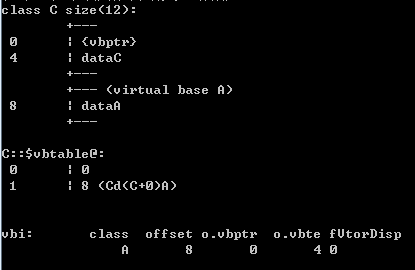

我们可以看到,菱形继承体系中的子类在内存布局上和普通多继承体系中的子类类有很大的不一样。对于类B和C,sizeof的值变成了12,除了包含类A的成员变量dataA外还多了一个指针vbptr,类D除了继承B、C各自的成员变量dataB、dataA和自己的成员变量外,还有两个分别属于B、C的指针。
那么类D对象的内存布局就变成如下的样子:
vbptr:继承自父类B中的指针
int dataB:继承自父类B的成员变量
vbptr:继承自父类C的指针
int dataC:继承自父类C的成员变量
int dataD:D自己的成员变量
int A:继承自父类A的成员变量
显然,虚继承之所以能够实现在多重派生子类中只保存一份共有基类的拷贝,关键在于vbptr指针。那vbptr到底指的是什么?又是如何实现虚继承的呢?其实上面的类D内存布局图中已经给出答案:
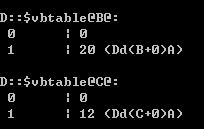
实际上,vbptr指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚表(virtual table),虚表中记录了vbptr与本类的偏移地址;第二项是vbptr到共有基类元素之间的偏移量。在这个例子中,类B中的vbptr指向了虚表D::$vbtable@B@,虚表表明公共基类A的成员变量dataA距离类B开始处的位移为20,这样就找到了成员变量dataA,而虚继承也不用像普通多继承那样维持着公共基类的两份同样的拷贝,节省了存储空间。
为了进一步确定上面的想法是否正确,我们可以写一个简单的程序加以验证:
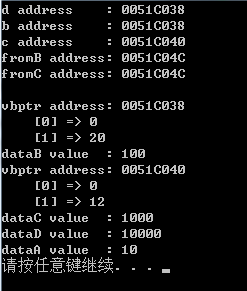
int main() { D* d = new D; d->dataA = 10; d->dataB = 100; d->dataC = 1000; d->dataD = 10000; B* b = d; // 转化为基类B C* c = d; // 转化为基类C A* fromB = (B*) d; A* fromC = (C*) d; std::cout << "d address : " << d << std::endl; std::cout << "b address : " << b << std::endl; std::cout << "c address : " << c << std::endl; std::cout << "fromB address: " << fromB << std::endl; std::cout << "fromC address: " << fromC << std::endl; std::cout << std::endl; std::cout << "vbptr address: " << (int*)d << std::endl; std::cout << " [0] => " << *(int*)(*(int*)d) << std::endl; std::cout << " [1] => " << *(((int*)(*(int*)d)) + 1)<< std::endl; // 偏移量20 std::cout << "dataB value : " << *((int*)d + 1) << std::endl; std::cout << "vbptr address: " << ((int*)d + 2) << std::endl; std::cout << " [0] => " << *(int*)(*((int*)d + 2)) << std::endl; std::cout << " [1] => " << *((int*)(*((int*)d + 2)) + 1) << std::endl; // 偏移量12 std::cout << "dataC value : " << *((int*)d + 3) << std::endl; std::cout << "dataD value : " << *((int*)d + 4) << std::endl; std::cout << "dataA value : " << *((int*)d + 5) << std::endl; }
结果为
转自:https://blog.csdn.net/xiejingfa/article/details/48028491