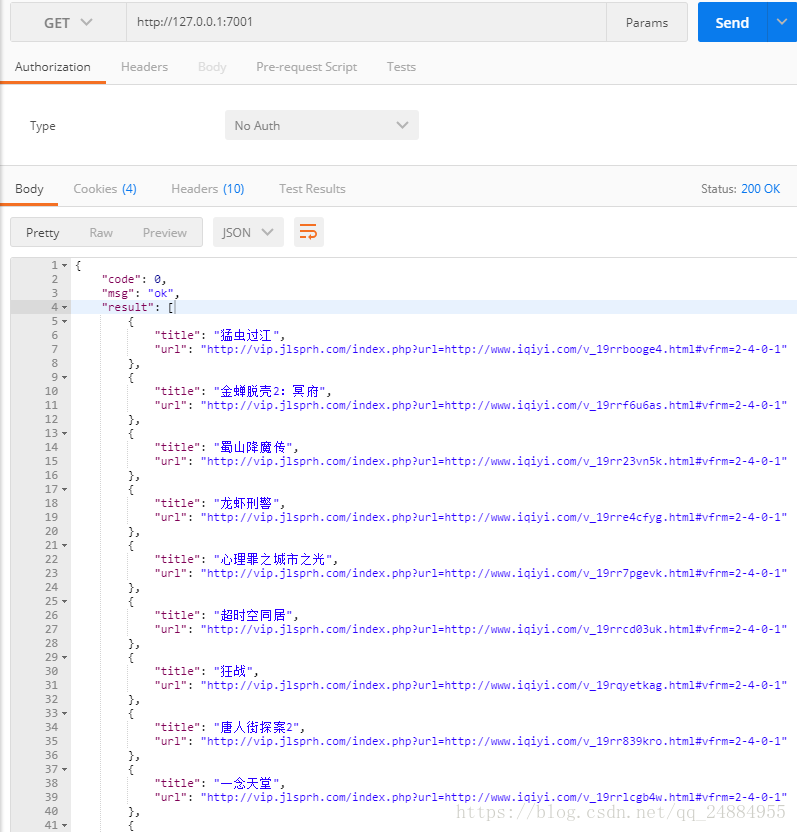
基于node egg框架下做的一个爱奇艺爬虫数据(会员的也可以观看)我们先看下最终的效果下图地址
第一步: 获取电影资源我们选择的 平台是爱奇艺
大部分的电影资源这些数据都在 html 页面上,这样的话就方便我们爬取数据,当然也有一些平台这些数据死动态获取的
这种的话就比在html的要麻烦一些当然也是可以爬的, 这次我们主要讲讲静态爬取
打开爱奇艺官网调试我们可以看到下面这两张图
1.
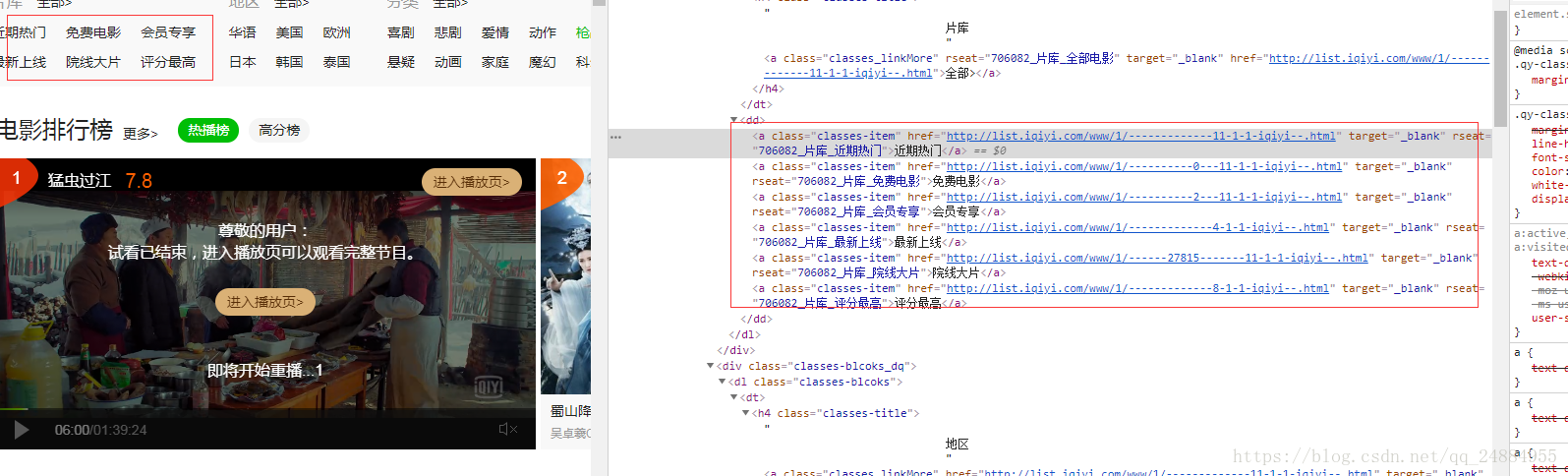
图1中的上面模块对应的都是一页地址
url: http://list.iqiyi.com/www/1/-------------11-1-1-iqiyi--.html
2.
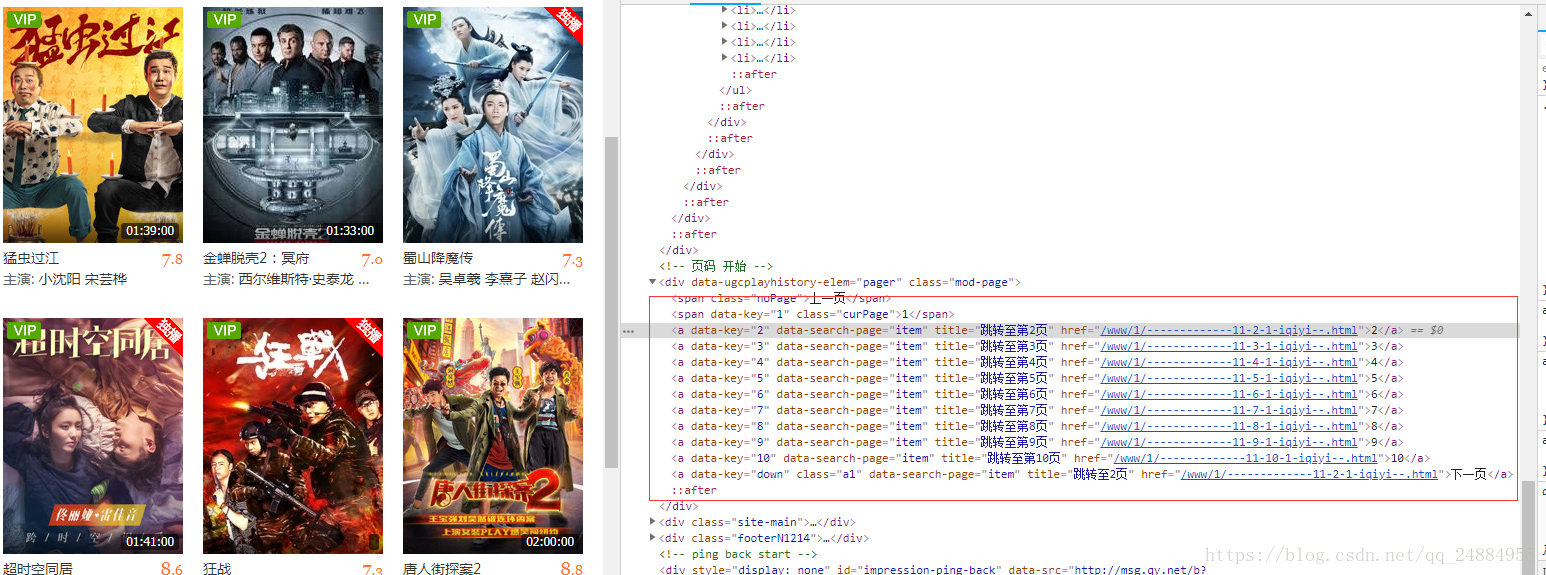
图2中的对应的模块对应的都是http://list.iqiyi.com/www/1/-------------11-1-1-iqiyi--.html的目标
最下面的点击下页可以看出每次加一 我们可以得出http://list.iqiyi.com/www/1/-------------11-‘这个值是累加的’-1-iqiyi--.html
我们知道了每页的对应关系后再出每页中找出每个电影直接的结构
下面看下图3:
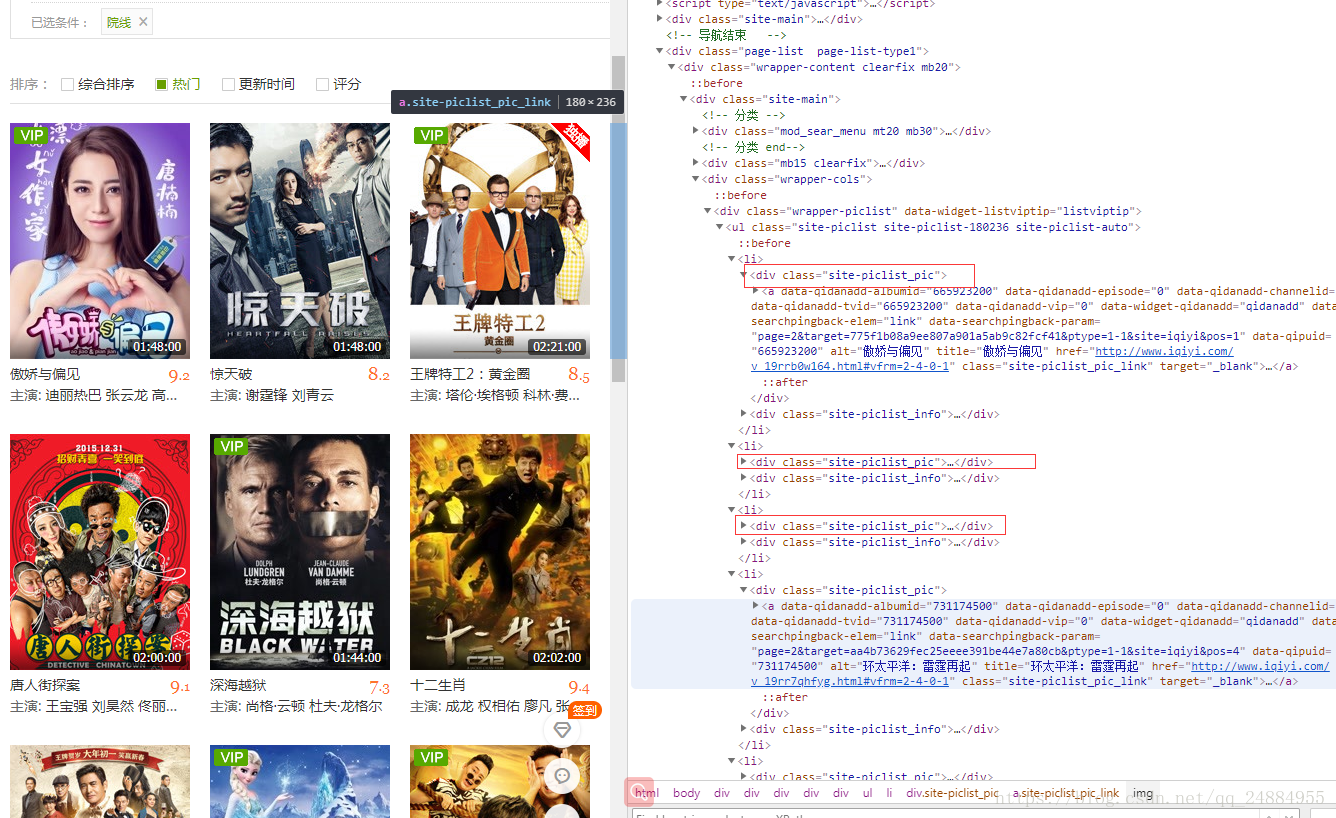
我们可以看出每个div盒子包裹着的url 都是 site-piclist_pic 下的a标签 :div.site-piclist_pic > a
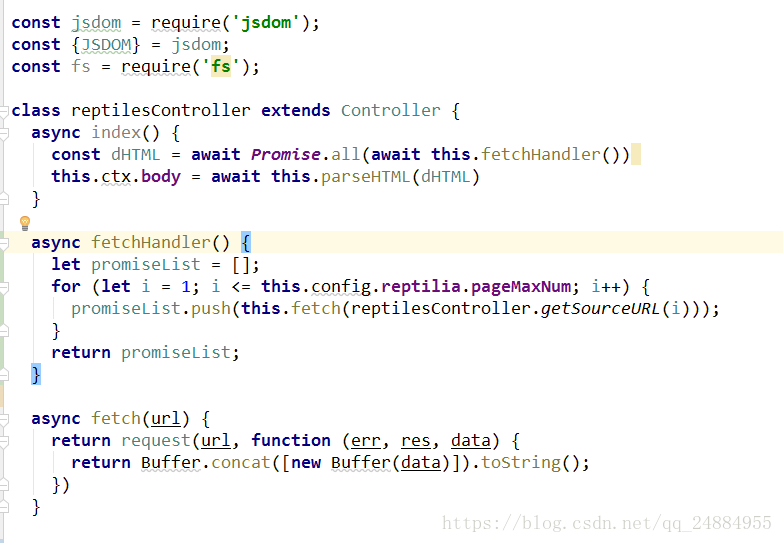
第二步:知道了电影所在的 url,也有了通过 url 获取 html 页面数据的方法,接下来要解析出 html 内的电影数据(使用node.js实现)
这里我们用的是 jsdom
jsdom 是模拟足够的Web浏览器子集,以便测试和抓取Web应用程序(最新版本的jsdom需要Node.js v6或更新版本 )
使用 jsdom 库解析 html 获取所有的电影标签 返回需要的数据
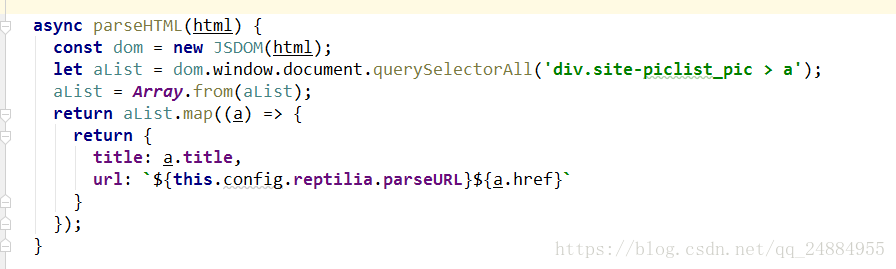
在config配置文件中有几个重要的配置

pageMaxNum:控制拉取的页码数和并发的数量
parseURL:这个接口是提供视频解析的
以上内容都是基于egg.js框架下实现的(代码中的中间件是为了规范统一的返回结果处理)
代码地址
https://github.com/xinjiewl/reptiles-aiqiyi
参考
-
http://www.iqiyi.com/
-
http://nodejs.cn/api/
-
蓝桥杯