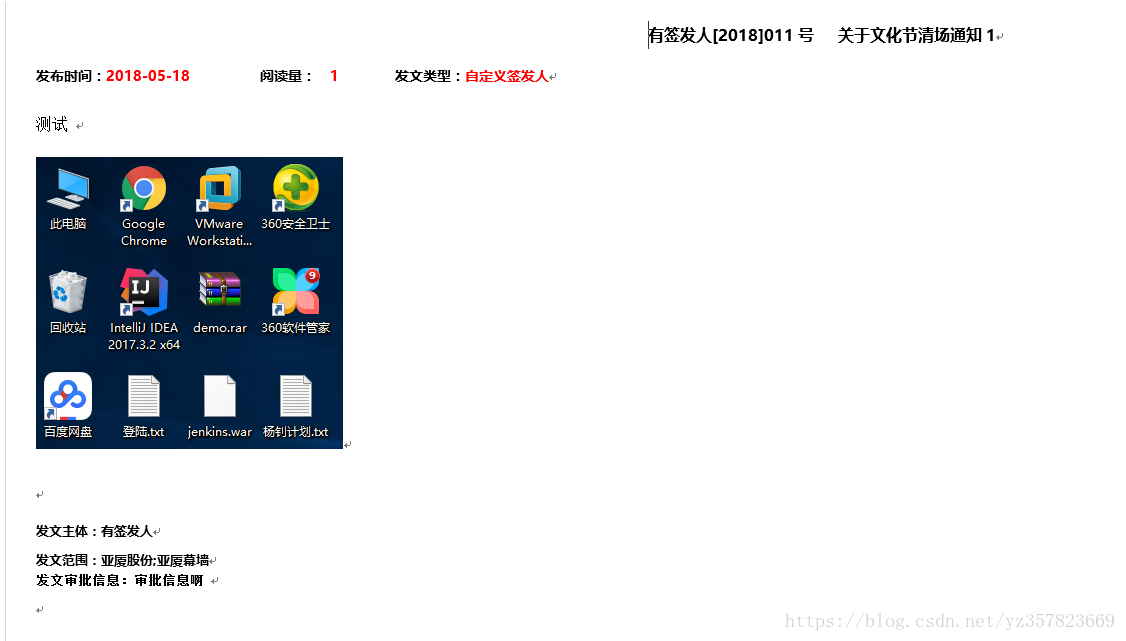
需求
批量将包含富文本的页面(含图片)导出为word的压缩包,并将每个页面的附件一同下载,下载的文件夹路径格式我就不展示了,具体页面如下
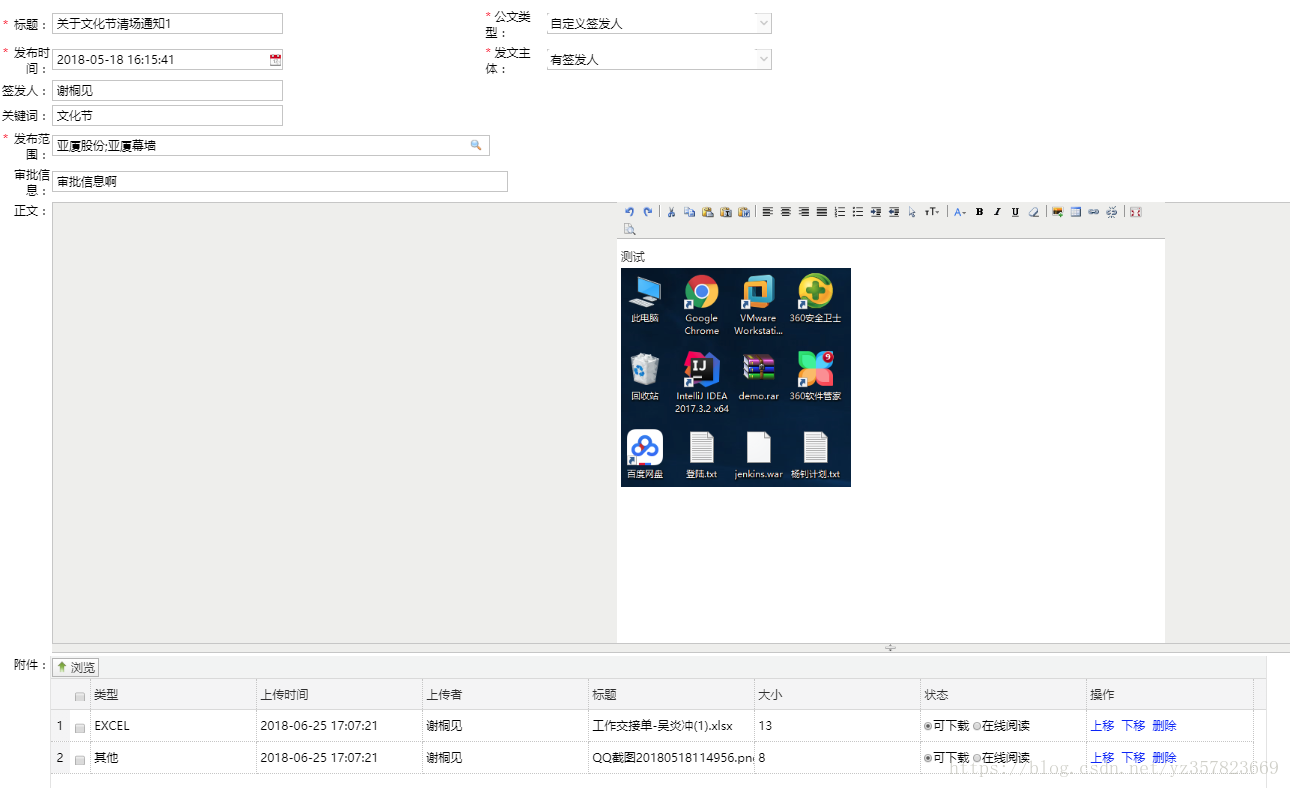
本次导出采用基于freemarker的word导出。大体上都是freemarker+xml方式。但是这种方式无法导出富文本,因为富文本字段包含html标签,他无法处理html元素(数据库字段存的值就是包含元素标签的)。导出后样式如下,

关于xml方式的导出以及包含图片的导出网上教程很多,这里我们就不多介绍了
所以xml这种方法不可取,最终在网上找到了这两篇文章恩人1 恩人2
经过我两天的琢磨与采坑,终于实现了功能,鉴于网上相关文章比较少并且记录学习的目的,写此博客并感谢恩人 哈哈~~~
(步骤我会写的细点图也会多点,当时看恩人的博客 看的我一愣一愣的)
基于freemarker方式导出包含富文本以及图片的word
其实基于freemarker方式的主要思想都是 在word中创建数据填充模板,并转化为另一个中间格式(xml,mht)并重命名为ftl,
所以我们的重点就是制作模板
1.首先第一步创建word文档(不要使用wps)

其中content 就是包含富文本的字段名称
接下来我们另存为mht 文件(注意:如果后期的ftl文件有乱码,我们此时要word设置为utf-8编码)

2.处理mht文件
打开我们的mht文件并处理(建议用sublime或者idea):
2.1处理模板字段
首先我们在mht文件中找到我们word中的表达式,例如publishTime 并他们修改为${publishTime!""}
因为mht文件有时候会自动换行,会在单词中间加上= 号 或者在{ 等符号与单词之间加上一些mht文件的样式,我们都要删掉
2.2处理富文本图片
我们首先找到
<?xml version=3D"1.0" encoding=3D"UTF-8" standalone=3D"yes"?>
<a:clrMap xmlns:a=3D"http://schemas.openxmlformats.org/drawingml/2006/main"=
bg1=3D"lt1" tx1=3D"dk1" bg2=3D"lt2" tx2=3D"dk2" accent1=3D"accent1" accent=
2=3D"accent2" accent3=3D"accent3" accent4=3D"accent4" accent5=3D"accent5" a=
ccent6=3D"accent6" hlink=3D"hlink" folHlink=3D"folHlink"/>
${imagesBase64String!""}
------=_NextPart_01D40A22.6DCACC80
Content-Location: file:///C:/D1745AB2/test2.files/header.htm
Content-Transfer-Encoding: quoted-printable
Content-Type: text/html; charset="utf-8"在中间加入${imagesBase64String!""} 作为占位符,并记录下file:///C:/D1745AB2/test2.files/header.htm 内容(后续会用到)
接下来找到
<xml xmlns:o=3D"urn:schemas-microsoft-com:office:office">
<o:MainFile HRef=3D"../test2.htm"/>
<o:File HRef=3D"themedata.thmx"/>
<o:File HRef=3D"colorschememapping.xml"/>
${imagesXmlHrefString!""}
<o:File HRef=3D"header.htm"/>
<o:File HRef=3D"filelist.xml"/>
</xml>
------=_NextPart_01D40A22.6DCACC80--加入${imagesXmlHrefString!""} 并记录下01D40A22.6DCACC80 后面会用到
2.3接下来我们修改编码
全文检索gb2312把他改成utf-8,同时需要加上3D前缀,对应着格式来改 一般就这两种:
<meta http-equiv=3DContent-Type content=3D"text/html; charset=3Dutf-8">和Content-Type: text/html; charset=3D"utf-8"然后将后缀名保存为ftl 就可以了
3.使用工具类处理模板
if("content".equals(key)){//处理富文本
RichHtmlHandler handler = new RichHtmlHandler(val.toString());
handler.setDocSrcLocationPrex("file:///C:/D1745AB2");//用到前面mht文件中的值
handler.setDocSrcParent("test2.files");//用到前面mht文件中的值
handler.setNextPartId("01D40A22.6DCACC80");//用到前面mht文件中的值
handler.setShapeidPrex("_x56fe__x7247__x0020");
handler.setSpidPrex("_x0000_i");
handler.setTypeid("#_x0000_t75");
handler.handledHtml(false);
String bodyBlock = handler.getHandledDocBodyBlock();
System.out.println("bodyBlock:\n"+bodyBlock);
String handledBase64Block = "";
if (handler.getDocBase64BlockResults() != null
&& handler.getDocBase64BlockResults().size() > 0) {
for (String item : handler.getDocBase64BlockResults()) {
handledBase64Block += item + "\n";
}
}
if(StringUtils.isBlank(handledBase64Block)){
handledBase64Block = "";
}
res.put("imagesBase64String", handledBase64Block);
String xmlimaHref = "";
if (handler.getXmlImgRefs() != null
&& handler.getXmlImgRefs().size() > 0) {
for (String item : handler.getXmlImgRefs()) {
xmlimaHref += item + "\n";
}
}
if(StringUtils.isBlank(xmlimaHref)){
xmlimaHref = "";
}
res.put("imagesXmlHrefString", xmlimaHref);
res.put("content", bodyBlock);
}然后通过提供的三个工具类RichHtmlHandler WordHtmlGeneratorHelper WordImageConvertor 就可以了
包含富文本图片的word导出基本就可以了,接下来是我们批量导出word并带出附件并下载为压缩包功能
我们的大致步骤
- 遍历数据源,下载导出word到项目的临时文件夹
- 如果有附件则下载附件,并存放相应临时文件夹
- 将整个文件夹压缩
- 下载压缩包并删除临时文件
涉及的知识点主要有
- freemarker+mht导出含图片富文本word
- 文件遍历压缩
- 导出压缩包,URL下载附件
- 文件名特殊字符处理
- 删除临时文件
- 访问项目Resouce中的文件(模板位置),访问项目所在路径(针对多系统部署临时文件路径问题)
下面展示整个流程的导出方法,涉及的具体工具类请看源码
/**
* 基于freemarker导出包含富文本的word
* @param ids
* @param sessionId
* @param typeId
* @param nameSpace
* @param newsNoticeService
* @param newsFileService
* @param response
* @param readProperty
* @param basePath
* @param newsNoticeProcessService
* @param newsPublishRangeService
*/
public static void ExportNoticeWord(String ids, String sessionId, String typeId, String nameSpace, INewsNoticeService newsNoticeService,
INewsFileService newsFileService, HttpServletResponse response, ReadProperty readProperty, String basePath, INewsNoticeProcessService newsNoticeProcessService, INewsPublishRangeService newsPublishRangeService){
try {
//basePath = request.getSession().getServletContext().getRealPath("/assets/exportTemp/");
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("UTF-8");
String idArr[] = ids.split(",");
String singlrNoticeName = "";
for(int i=0;i<idArr.length;i++){
//下载word
NewsNotice notice = newsNoticeService.getNoticeById(idArr[i]);
Map<String, Object> dataMap = ExportNoticeUtil.getData(notice,newsNoticeProcessService,newsPublishRangeService);
WordHtmlGeneratorHelper.handleAllObject(dataMap);
String filePath = ExportNoticeUtil.class.getClassLoader().getResource("noticeExportWord.ftl").getPath();
configuration.setDirectoryForTemplateLoading(new File(filePath).getParentFile());//模板文件所在路径
Template t = null;
t = configuration.getTemplate("noticeExportWord.ftl","UTF-8"); //获取模板文件
File outFile = null;
if(idArr.length == 1){
singlrNoticeName = notice.getArticleNo();
}
String formatTitle = StringUtils.isNotBlank(notice.getTitle())?FilePattern.matcher(notice.getTitle()).replaceAll("")
:"标题为空";
outFile = idArr.length == 1?new File(basePath+notice.getArticleNo(),formatTitle+".doc")
:new File(basePath+"公文批导"+getTime("yyyyMMdd")+"/"+notice.getArticleNo(),formatTitle+".doc");
if(!outFile.exists()){
outFile.getParentFile().mkdirs();
}
Writer out = null;
out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"UTF-8"));
t.process(dataMap, out); //将填充数据填入模板文件并输出到目标文件
out.close();
//下载附件
NewsFile newsFile = new NewsFile();
newsFile.setRefId(idArr[i]);
PagerModel<NewsFile> pm = null;
if (StringUtils.isNotBlank(newsFile.getRefId())) {
pm = newsFileService.getPagerModelByQuery(newsFile, new Query());
}
List<NewsFile> files = pm.getRows();
for(NewsFile file:files){
File downLoadFile = idArr.length == 1?new File(basePath+notice.getArticleNo()+"/"+notice.getArticleNo()+"附件",file.getFileName())
:new File(basePath+"公文批导"+getTime("yyyyMMdd")+"/"+notice.getArticleNo()+"/"+notice.getArticleNo()+"附件",file.getFileName());
downLoadFile(file,readProperty,downLoadFile);
}
}
//压缩文件
String zipFileName = idArr.length == 1?basePath + singlrNoticeName+".zip":basePath+"公文批导"+getTime("yyyyMMdd")+".zip";
String FileName = idArr.length == 1?basePath + singlrNoticeName:basePath+"公文批导"+getTime("yyyyMMdd");
ZipCompressor zc = new ZipCompressor(zipFileName);
File[] srcfile = new File[1];
srcfile[0] = new File(FileName);
zc.compress(srcfile);
//导出压缩包
String title = idArr.length == 1?singlrNoticeName+".zip":"公文批导"+getTime("yyyyMMdd")+".zip";
OutputStream output = response.getOutputStream();
response.reset();
response.setHeader("Content-Disposition",
"attachment;filename=" + new String(title.getBytes("UTF-8"), "ISO8859-1"));
response.setContentType("application/octet-stream;charset=UTF-8");
FileInputStream inStream = new FileInputStream(idArr.length == 1?basePath+singlrNoticeName+".zip":basePath+"公文批导"+getTime("yyyyMMdd")+".zip");
byte[] buf = new byte[4096];
int readLength;
while (((readLength = inStream.read(buf)) != -1)) {
output.write(buf, 0, readLength);
}
inStream.close();
output.flush();
output.close();
String delDir= idArr.length == 1?basePath+singlrNoticeName
:basePath+"公文批导"+getTime("yyyyMMdd");
String delFile= idArr.length == 1?basePath+singlrNoticeName+".zip"
:basePath+"公文批导"+getTime("yyyyMMdd")+".zip";
// //删除临时文件
DeleteFileUtil.deleteDirectory(delDir);
DeleteFileUtil.delete(delFile);
} catch (Exception e) {
e.printStackTrace();
}
}导出word结果