写在前面:这里要感谢网易云课堂丘祐玮老师,本篇博文内容都是基于老师所讲内容而写,想要学习python学习爬虫的可以去看老师的课程
今天要分享的是使用python爬取拉勾网职位信息,这里只爬取python职位信息用做爬虫效果展示,想要深入的同学再看完本篇博文后可以继续研究
代码中用到的一些库不懂的同学可以看一下之前写的博文,里面有介绍,这里就不再重复说明了:
https://blog.csdn.net/qq_33722172/article/details/82469050
如下图,搜索python,按之前经验页面python职位信息是访问https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput= 获得的
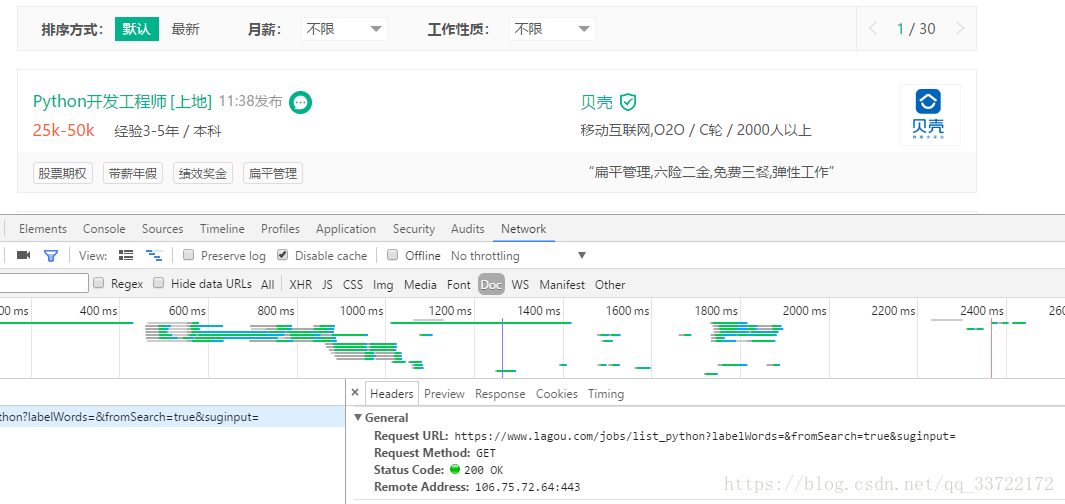
然而事实真是如此吗?
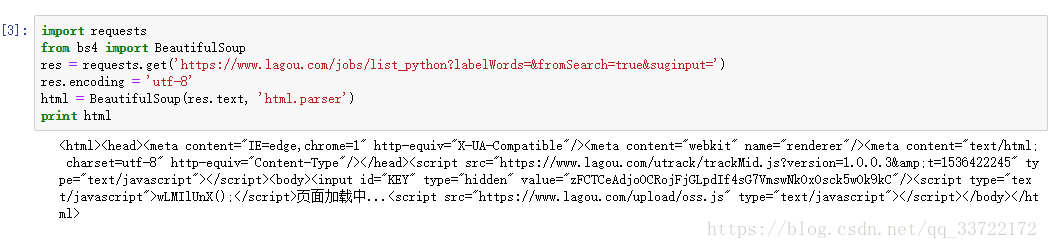
可以看到并没有获取到,那么有些web开发经验的应该就能想到python职位信息是不是通过ajax异步获取的呢?果不其然,再network-XHR中我找到了这个请求,返回的json数据中有python职位信息
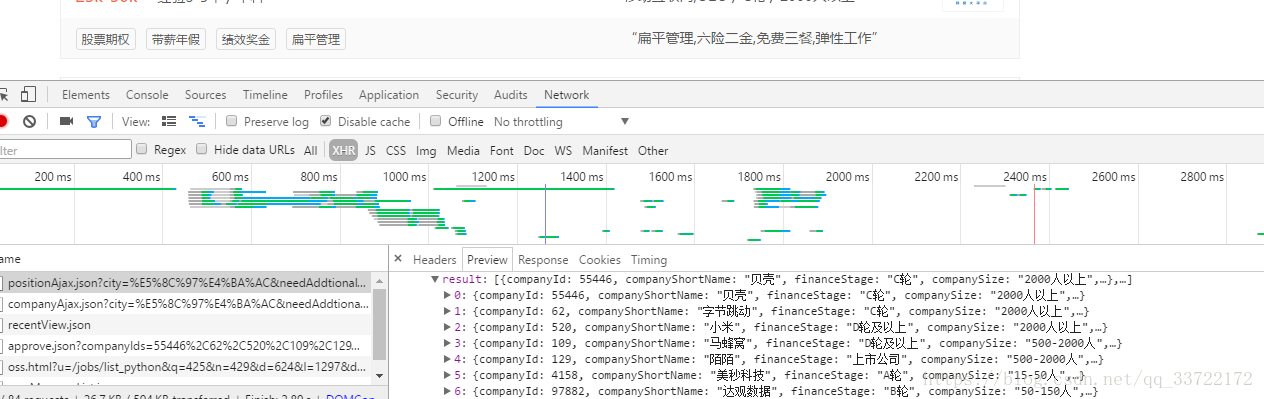
那么这里就可以请求这个链接应该就能获取到我们想要的数据了吧?是的,但是要注意这里还有个陷阱

这里的请求用的是POST请求,那么POST请求我们应该能想到在请求时肯定给服务器传递了数据


在构造模拟请求时一定要带上form data中的数据,而且因为是通过ajax获取的数据,所以header头里的信息也要带上(特别是一些我们平常没见过的头信息,它很可能是网站自己设置的验证信息)如下:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':None,
'X-Requested-With':'XMLHttpRequest'
}
content = []
formdata = {
'first':'true',
'pn':1,
'kd':'python'
}
res = requests.post('https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false',headers=headers,data=formdata)
res.encoding = 'utf-8'
html = BeautifulSoup(res.text, 'html.parser')结果如下:

在线格式化一下,可以看到我们想要的职位信息

同样不难猜到form-data中的pn参数应该就是当前页数了,那么我们只需要改变pn就能够获取不同页的python职位数据了
有了列表信息,那么接下来就是获取详细信息了,随便打开一个职位,显示如下:

现在我们要获取职位描述,右键审查元素

通过观察,我们可以看到职位描述在dd标签中,class为job_bt
url = 'https://www.lagou.com/jobs/4938653.html'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36',
'Host':'www.lagou.com',
'Pragma':'no-cache',
'Referer':url,
'Upgrade-Insecure-Requests':'1'
}
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
info = BeautifulSoup(res.text, 'html.parser')
return info.select('.job_bt')[0].text结果如下:

同样我们可以看到https://www.lagou.com/jobs/4938653.html 中的49386553就是这个职位的唯一id了,从上面返回的职位列表json数据中也能证实这一点
到此我们已经能够获取每页的职位列表信息以及每个职位的详细描述
那么整合一下上述代码,一个完整的爬取拉勾网职位信息爬虫如下:
import requests
from bs4 import BeautifulSoup
import json
import time
def getpositioninfo(id):
url = 'https://www.lagou.com/jobs/%s.html' % id
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36',
'Host':'www.lagou.com',
'Pragma':'no-cache',
'Referer':url,
'Upgrade-Insecure-Requests':'1'
}
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
info = BeautifulSoup(res.text, 'html.parser')
return info.select('.job_bt')[0].text
def getpositionlist():
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36',
'Host':'www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':None,
'X-Requested-With':'XMLHttpRequest'
}
content = []
for i in range(1,6):
formdata = {
'first':'true',
'pn':i,
'kd':'python'
}
res = requests.post('https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false',headers=headers,data=formdata)
res.encoding = 'utf-8'
html = BeautifulSoup(res.text, 'html.parser')
jd = json.loads(html.text)
page_contents = jd['content']['positionResult']['result']
for v in page_contents:
position_dict = {
'position_name':v['positionName'],
'workyear':v['workYear'],
'salary':v['salary'],
'district':v['district'],
'company_name':v['companyFullName']
}
position_id = v['positionId']
position_detail = getpositioninfo(position_id)
position_dict['position_detail'] = position_detail
content.append(page_contents)
time.sleep(5)
line = json.dumps(content,ensure_ascii=False) #以json格式输出,不使用ascii编码
with open('lagou.json','w') as fp:
fp.write(line.encode('utf-8')) #写进文件以utf-8格式
if __name__=='__main__':
#getpositioninfo(5068139) #测试用