在boosting中,集成分类器包含多个非常简单的成员分类器,这些分类器性能稍强于随机猜测(rough rules of thumb),被称为弱学习机。典型的弱分类器是单层决策树。
Adaboost使用整个训练集来训练弱学习机,训练样本在每次迭代中都会被赋予一个新的权重,在上一个学习机错误的基础上进行学习进而构建一个更加强大的分类器。
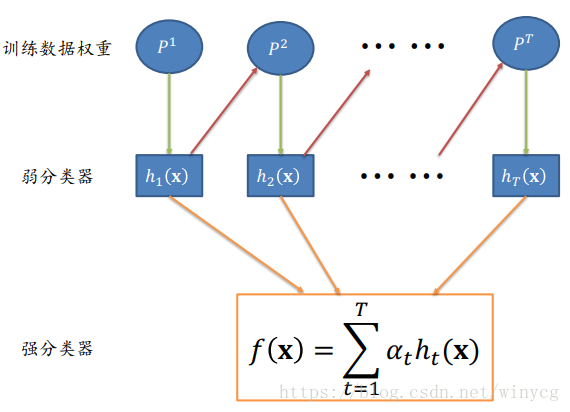
算法伪代码流程如下:
输入:训练数据
输出:分类模型
1.初始化训练数据的权重向量
,并满足
2.
3. --------基于
训练弱分类器
4. --------计算弱分类器错误率
5. --------计算弱分类器权重
,此时
越小,
越大,
是恒大于0.5的。
6. --------重新计算训练数据的权重向量
,此时判断错的样本权重将会增加,正确的权重将会减小。
7. --------归一化权重向量
8.
9. 最终决策:
初始的时候,所有的‘+’和‘-’都是等权重的。第一个分类器后,右边的‘+’分类错误,此时减小分类正确的权重,增大分类错误的权重。第二个分类器满足了此前分错具有较大权重的‘+’,此时左边的‘-’分错,所以增大左边‘-’的权重,同时分类正确的权重较小。最后将所有的分类器按分类器权重组合在一起。
如图3个分类器将决策区域最终划分为了6部分,从左到右,从上到下,分别标号1~6。其中1和6区域是3个分类器没有分歧。2区域蓝色,因为前两个分类器认为是蓝色,第3个认为是非蓝色,基于权重是0.42+0.65=1.07>0.92,所以此区域应该是蓝色。其他部分同理。


以下将使用葡萄酒数据集训练一个AdaBoost分类器,每个分类器都是一个单层的决策树。
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy', max_depth=1)
ada = AdaBoostClassifier(base_estimator=tree,
n_estimators=500,
learning_rate=0.1,
random_state=0)
tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
print('Decision tree train/test accuracies: %.3f/%.3f'
% (accuracy_score(y_train, y_train_pred), accuracy_score(y_test, y_test_pred)))
ada.fit(X_train, y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
print('Adaboost tree train/test accuracies: %.3f/%.3f'
% (accuracy_score(y_train, y_train_pred), accuracy_score(y_test, y_test_pred)))
Decision tree train/test accuracies: 0.604/0.563
Adaboost tree train/test accuracies: 0.887/0.845