K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是较为简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
K最近邻算法(k-nearest neighbors)是一种有监督分类的机器学习算法。顾名思义,其算法主体思想就是根据距离相近的邻居类别,
来判定自己的所属类别。算法的前提是需要有一个已被标记类别的训练数据集,具体的计算步骤分为一下三步:
1、计算测试对象与训练集中所有对象的距离,可以是欧式距离、余弦距离等,比较常用的是较为简单的欧式距离;
2、找出上步计算的距离中最近的K个对象,作为测试对象的邻居;
3、找出K个对象中出现频率最高的对象,其所属的类别就是该测试对象所属的类别。实现K最近邻算法
#! /usr/bin/env python
# -*- coding:utf-8 -*-
"""
k-NearestNeighbor
k近临算法的python实现
"""
import numpy as np
def classify(X, DATASET, LABELS, K):
# 大写参数表示常量,不可改变
distances = np.sqrt(np.sum(np.square(DATASET - X), axis=1))
# 计算距离矩阵
len_dis = len(distances)
# 得到distances数目
labels = []
# 存储标签
for i in range(0, K):
min_value = distances[i]
min_value_idx = i
for j in range(i + 1, len_dis):
if distances[j] < min_value:
min_value = distances[j]
min_value_idx = j
distances[i], distances[min_value_idx] = distances[min_value_idx], distances[i]
labels.append(LABELS[min_value_idx])
# 选择排序挑选出前k个最值
# 用labels存储前k个最小距离的标签
C = labels[0]
max_count = 0
for label in labels:
count = labels.count(label)
if count > max_count:
max_count = count
C = label
# 求前k个label中,重复次数最多的label,并返回
return C图像处理相关函数
#! /usr/bin/env python
# -*- coding:utf-8 -*-
"""
和图像操作有关函数
"""
import matplotlib.pyplot as plt
import numpy as np
def img2vector(filename):
# 将图像转向量
vector = np.zeros([1024], int)
# 定义返回的向量,大小为1*1024
lines = None
with open(filename, 'r') as f:
lines = f.readlines()
# 读取32*32数字文件
for i in range(32):
for j in range(32):
vector[i * 32 + j] = lines[i][j]
# 将信息存放在vector中
return vector
def img2mat(filename):
# 将图像转矩阵
mat = np.zeros([32, 32], int)
# 定义返回的矩阵,大小为32*32
lines = None
with open(filename, 'r') as f:
lines = f.readlines()
# 读取32*32数字文件
for i in range(32):
for j in range(32):
mat[i, j] = lines[i][j]
# 将信息存放在mat中
return mat
def show_img(mat):
# 显示图像
plt.imshow(mat)
# plt.axis('off')
plt.show()识别手写数字
#! /usr/bin/env python
# -*- coding:utf-8 -*-
"""
基于knn算法的手写数字识别
"""
from os import listdir
import matplotlib.pyplot as plt
import numpy as np
from img import img2mat, img2vector, show_img
from knn import classify
train_digits_path = '/home/user/digits/trainingDigits/'
test_digits_path = '/home/user/digits/testDigits/'
def read_dataSet(path):
file_list = listdir(path)
# 获取文件夹下的所有文件路径
num_files = len(file_list)
# 统计文件数目
dataset = np.zeros([num_files, 1024], int)
# 用于存放所有的数字文件
labels = np.zeros([num_files])
# 用于存放对应的标签
for i in range(num_files):
# 遍历所有的文件
file_path = file_list[i]
# 获取文件名称
digit = int(file_path.split('_')[0])
# 通过文件名获取标签
labels[i] = digit
# 存放标签
dataset[i] = img2vector(path + '/' + file_path)
# 存放数据
return dataset, labels
# 读取训练集
train_dataset, train_labels = read_dataSet(train_digits_path)
# 读取测试集
test_dataset, test_labels = read_dataSet(test_digits_path)
def classify_test_dataset(k):
# 对测试集进行识别
test_num = len(test_dataset)
# 测试集的数目
error_num = 0
# 错误数目
for data, label in zip(test_dataset, test_labels):
res = classify(data, train_dataset, train_labels, k)
# 对测试集进行预测
if res != label:
error_num += 1
# 若预测错误,则计数器加一
print("total:{},error num:{},error rate:{}".format(test_num, error_num, error_num / test_num))
def classify_test_data(filename):
# 对测试集合,单个文件进行识别
file_path = test_digits_path + filename
try:
data = img2vector(file_path)
res = classify(data, train_dataset, train_labels, 3)
return int(res)
except FileNotFoundError:
print("No such file.")
if __name__ == '__main__':
# 测试
'''
mats = []
vs = []
for idx in range(4):
filename = str(idx) + '_2.txt'
mat = img2mat(test_digits_path + filename)
mats.append(mat)
pv = classify_test_data(filename)
rv = int(filename.split('_')[0])
vs.append([pv,rv])
for i in range(len(mats)):
pv,rv = vs[i]
plt.subplot(2,2,i+1)
plt.xlabel("pv:"+str(pv)+",rv:"+str(rv))
plt.imshow(mats[i])
plt.show()
'''
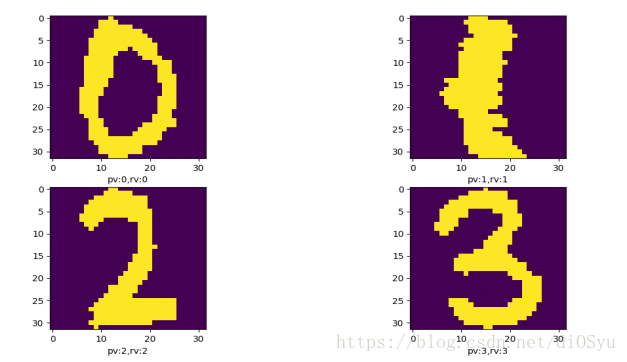
classify_test_dataset(3)运行结果示例:

参考文献
[1] Peter Harrington. Machine Learning in Action
[2] 维基百科 .K-nearest_neighbors_algorithm
[3] 百度百科 .k近邻算法
[4] New York University. data/digits