jpa是什么
Java Persistence API:用于对象持久化的 API Java EE 5.0
平台标准的 ORM 规范,使得应用程序以统一的方式访问持久层
JPA和Hibernate的关系
~JPA 是 hibernate 的一个抽象(就像JDBC和JDBC驱动的关系):
1. JPA 是规范:JPA 本质上就是一种 ORM 规范,不是ORM 框架 ——
因为 JPA 并未提供 ORM 实现,它只是制订了一些规范,提供了一些编程的 API 接口,但具体实现则由 ORM 厂商提供实现
2. Hibernate 是实现:Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现
~从功能上来说, JPA 是 Hibernate 功能的一个子集
JPA的优势
-
标准化: 提供相同的 API,这保证了基于JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
-
简单易用,集成方便: JPA 的主要目标之一就是提供更加简单的编程模型,在 JPA 框架下创建实体和创建 Java 类一样简单,只需要使用 javax.persistence.Entity 进行注释;JPA 的框架和接口也都非常简单,
-
可媲美JDBC的查询能力: JPA的查询语言是面向对象的,JPA定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
-
支持面向对象的高级特性: JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,最大限度的使用面向对象的模型
如何使用
-
新建JPA工程,配置persistence.xml文件,配置privider是HibernatePersistence,先是配置数据库连接属性(driver , url, username, password);
-
这里需要配置相应hiberate基本属性(format_sql,show_sql,hbm2ddl.auto)这三个属性;
-
在测试类中使用Persistence.创建实体管理工厂,通过工厂创建实体管理工具,通过实体工具EntityManager创建实体事务EntityTransaction,事务开启
persistence.xml:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistencehttp://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<!--
name: 属性用于定义持久化单元的名字, 必选
transaction-type:指定 JPA 的事务处理策略。RESOURCE_LOCAL:默认值,数据库级别的事务,只能针对一种数据库,不支持分布式事务。
如果需要支持分布式事务,使用JTA:transaction-type="JTA"
-->
<persistence-unit name="jpa-1" transaction-type="RESOURCE_LOCAL">
<!--
配置使用什么ORM产品来作为JPA的实现
【指定ORM框架的 javax.persistence.spi.PersistenceProvider 接口的实现类。若项目中只有一个实现可省略】
-->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<!-- 添加持久化類 -->
<class>com.wcg.jpa.helloworld.Customer</class>
<class>com.wcg.jpa.helloworld.Order</class>
<class>com.wcg.jpa.helloworld.Department</class>
<class>com.wcg.jpa.helloworld.Manager</class>
<class>com.wcg.jpa.helloworld.Item</class>
<class>com.wcg.jpa.helloworld.Category</class>
<!--
配置二级缓存的策略
ALL:所有的实体类都被缓存
NONE:所有的实体类都不被缓存.
ENABLE_SELECTIVE:标识 @Cacheable(true) 注解的实体类将被缓存
DISABLE_SELECTIVE:缓存除标识 @Cacheable(false) 以外的所有实体类
UNSPECIFIED:默认值,JPA 产品默认值将被使用
-->
<shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
<properties>
<!-- 连接数据库的基本信息 -->
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql:///jpa"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="root"/>
<!-- 配置 JPA 实现产品的基本属性. 配置 hibernate 的基本属性 -->
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<!-- 配置二级缓存相关 -->
<property name="hibernate.cache.use_second_level_cache" value="true"/>
<property name="hibernate.cache.region.factory_class" value="org.hibernate.cache.ehcache.EhCacheRegionFactory"/>
<property name="hibernate.cache.use_query_cache" value="true"/>
</properties>
</persistence-unit>
</persistence>test.java
public class JPATest {
private EntityManagerFactory entityManagerFactory;
private EntityManager entityManager;
private EntityTransaction transaction;
@Before
public void init() {
// 参数为持久化单元名
entityManagerFactory = Persistence.createEntityManagerFactory("jpa-1");
entityManager = entityManagerFactory.createEntityManager();
transaction = entityManager.getTransaction();
transaction.begin();
}
@After
public void destroy() {
transaction.commit();
entityManager.close();
entityManagerFactory.close();
}JPA的常用注解
@Entity :
*标注用于实体类声明语句之前,指出该Java 类为实体类,将映射到指定的数据库表。如声明一个实体类 Customer,它将映射到数据库中的 customer 表上。
@Table:
* 当实体类与其映射的数据库表名不同名时需要使用 @Table 标注说明,该标注与 @Entity 标注并列使用,置于实体类声明语句之前,可写于单独语句行,也可与声明语句同行。
* @Table 标注的常用选项是 name,用于指明数据库的表名
* @Table标注还有一个两个选项 catalog 和 schema 用于设置表所属的数据库目录或模式,通常为数据库名。uniqueConstraints 选项用于设置约束条件,通常不须设置。
@Id:
* @Id 标注用于声明一个实体类的属性映射为数据库的主键列。该属性通常置于属性声明语句之前,可与声明语句同行,也可写在单独行上。
* @Id标注也可置于属性的getter方法之前。
@GeneratedValue
* @GeneratedValue 用于标注主键的生成策略,通过 strategy 属性指定。默认情况下,JPA 自动选择一个最适合底层数据库的主键生成策略:SqlServer 对应 identity,MySQL 对应 auto increment。
* 在 javax.persistence.GenerationType 中定义了以下几种可供选择的策略:
* IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
* AUTO: JPA自动选择合适的策略,是默认选项;
* SEQUENCE:通过序列产生主键,通过 @SequenceGenerator 注解指定序列名,MySql 不支持这种方式
* TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。
@Basic
* @Basic 表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为@Basic
* fetch: 表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主支抓取和延迟加载,默认为 EAGER.
* optional:表示该属性是否允许为null,默认为true
@Column
* 当实体的属性与其映射的数据库表的列不同名时需要使用@Column 标注说明,该属性通常置于实体的属性声明语句之前,还可与 @Id 标注一起使用。
* @Column 标注的常用属性是 name,用于设置映射数据库表的列名。此外,该标注还包含其它多个属性,如:unique 、nullable、length 等。
* @Column 标注的 columnDefinition 属性: 表示该字段在数据库中的实际类型.通常 ORM 框架可以根据属性类型自动判断数据库中字段的类型,但是对于Date类型仍无法确定数据库中字段类型究竟是DATE,TIME还是TIMESTAMP.此外,String的默认映射类型为VARCHAR, 如果要将 String 类型映射到特定数据库的 BLOB 或TEXT 字段类型.
* @Column标注也可置于属性的getter方法之前
@Transient
* 表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性.
* 如果一个属性并非数据库表的字段映射,就务必将其表示为@Transient,否则,ORM框架默认其注解为@Basic
@Temporal
* 在核心的 Java API 中并没有定义 Date 类型的精度(temporal precision). 而在数据库中,表示 Date 类型的数据有 DATE, TIME, 和 TIMESTAMP 三种精度(即单纯的日期,时间,或者两者 兼备). 在进行属性映射时可使用@Temporal注解来调整精度.
@TableGenerator
* 将当前主键的值单独保存到一个数据库的表中,主键的值每次都是从指定的表中查询来获得
* 这种方法生成主键的策略可以适用于任何数据库,不必担心不同数据库不兼容造成的问题。
@TableGenerator(
name = "tableGeneratorName", //name 属性表示该主键生成策略的名称,它被引用在@GeneratedValue中设置的generator 值中
table = "JPA_ID_GENERATOR" , // table 属性表示表生成策略所持久化的表名
allocationSize = 1, // allocationSize 表示每次主键值增加的大小, 默认值为 50
initialValue = 1, // initialValue表示初始值
pkColumnName = "PK_NAME", //pkColumnName 属性的值表示在持久化表中,该主键生成策略所对应键值的名称
pkColumnValue = "PERSON_ID", //pkColumnValue 属性的值表示在持久化表中,该生成策略所对应的主键
valueColumnName="ID_VAL", //valueColumnName 属性的值表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加
)
@GeneratedValue(strategy=GenerationType.TABLE, //指定id生成策略
generator="ID_GENERATOR") //指定生成策略名称
JPA相关接口/类
Persistence:
* Persistence 类是用于获取 EntityManagerFactory 实例。该类包含一个名为 createEntityManagerFactory 的 静态方法 。
* createEntityManagerFactory 方法有如下两个重载版本。
* 带有一个参数的方法以 JPA 配置文件 persistence.xml 中的持久化单元名为参数
* 带有两个参数的方法:前一个参数含义相同,后一个参数 Map类型,用于设置 JPA 的相关属性,这时将忽略其它地方设置的属性。Map 对象的属性名必须是 JPA 实现库提供商的名字空间约定的属性名。
EntityManagerFactory:
* EntityManagerFactory 接口主要用来创建 EntityManager 实例。该接口约定了如下4个方法:
* createEntityManager():用于创建实体管理器对象实例。
* createEntityManager(Map map):用于创建实体管理器对象实例的重载方法,Map 参数用于提供 EntityManager 的属性。
* isOpen():检查 EntityManagerFactory 是否处于打开状态。实体管理器工厂创建后一直处于打开状态,除非调用close()方法将其关闭。
* close():关闭 EntityManagerFactory 。 EntityManagerFactory 关闭后将释放所有资源,isOpen()方法测试将返回 false,其它方法将不能调用,否则将导致IllegalStateException异常。
EntityManager:
* 在 JPA 规范中, EntityManager 是完成持久化操作的核心对象。实体作为普通 Java 对象,只有在调用 EntityManager 将其持久化后才会变成持久化对象。EntityManager 对象在一组实体类与底层数据源之间进行 O/R 映射的管理。它可以用来管理和更新 Entity Bean, 根椐主键查找 Entity Bean, 还可以通过JPQL语句查询实体。
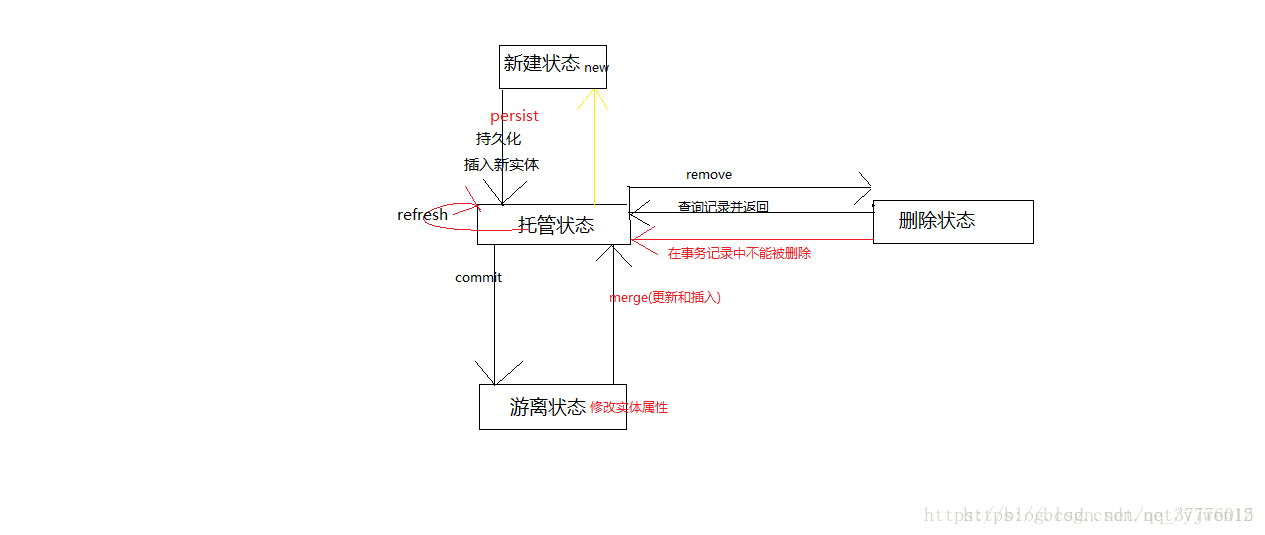
* 实体的状态:
* 新建状态: 新创建的对象,尚未拥有持久性主键。
* 持久化状态:已经拥有持久性主键并和持久化建立了上下文环境
* 游离状态:拥有持久化主键,但是没有与持久化建立上下文环境
* 删除状态: 拥有持久化主键,已经和持久化建立上下文环境,但是从数据库中删除。
* find (Class<T> entityClass,Object primaryKey):返回指定的 OID 对应的实体类对象,如果这个实体存在于当前的持久化环境,则返回一个被缓存的对象;否则会创建一个新的 Entity, 并加载数据库中相关信息;若 OID 不存在于数据库中,则返回一个 null。第一个参数为被查询的实体类类型,第二个参数为待查找实体的主键值。
* getReference (Class<T> entityClass,Object primaryKey):与find()方法类似,不同的是:如果缓存中不存在指定的 Entity, EntityManager 会创建一个 Entity 类的代理,但是不会立即加载数据库中的信息,只有第一次真正使用此 Entity 的属性才加载,所以如果此 OID 在数据库不存在,getReference() 不会返回 null 值, 而是抛出EntityNotFoundException
* persist (Object entity):用于将新创建的 Entity 纳入到 EntityManager 的管理。该方法执行后,传入 persist() 方法的 Entity 对象转换成持久化状态。
* 如果传入 persist() 方法的 Entity 对象已经处于持久化状态,则 persist() 方法什么都不做。
* 如果对删除状态的 Entity 进行 persist() 操作,会转换为持久化状态。
* 如果对游离状态的实体执行 persist() 操作,可能会在 persist() 方法抛出 EntityExistException(也有可能是在flush或事务提交后抛出)。
* remove (Object entity):删除实例。如果实例是被管理的,即与数据库实体记录关联,则同时会删除关联的数据库记录。
* merge (T entity):merge() 用于处理 Entity 的同步。即数据库的插入和更新操作
* flush ():同步持久上下文环境,即将持久上下文环境的所有未保存实体的状态信息保存到数据库中。
* setFlushMode (FlushModeType flushMode):设置持久上下文环境的Flush模式。参数可以取2个枚举
* FlushModeType.AUTO 为自动更新数据库实体,
* FlushModeType.COMMIT 为直到提交事务时才更新数据库记录。
* getFlushMode ():获取持久上下文环境的Flush模式。返回FlushModeType类的枚举值。
* refresh (Object entity):用数据库实体记录的值更新实体对象的状态,即更新实例的属性值。
* clear ():清除持久上下文环境,断开所有关联的实体。如果这时还有未提交的更新则会被撤消。
* contains (Object entity):判断一个实例是否属于当前持久上下文环境管理的实体。
* isOpen ():判断当前的实体管理器是否是打开状态。
* getTransaction ():返回资源层的事务对象。EntityTransaction实例可以用于开始和提交多个事务。
* close ():关闭实体管理器。之后若调用实体管理器实例的方法或其派生的查询对象的方法都将抛出 IllegalstateException 异常,除了getTransaction 和 isOpen方法(返回 false)。不过,当与实体管理器关联的事务处于活动状态时,调用 close 方法后持久上下文将仍处于被管理状态,直到事务完成。
* createQuery (String qlString):创建一个查询对象。
* createNamedQuery (String name):根据命名的查询语句块创建查询对象。参数为命名的查询语句。
* createNativeQuery (String sqlString):使用标准 SQL语句创建查询对象。参数为标准SQL语句字符串。
* createNativeQuery (String sqls, String resultSetMapping):使用标准SQL语句创建查询对象,并指定返回结果集 Map的名称。
* EntityTransaction 接口用来管理资源层实体管理器的事务操作。通过调用实体管理器的getTransaction方法 获得其实例。
merge() 方法:
①Merge()用于处理Entity的同步,主要用于在数据库的插入和更新
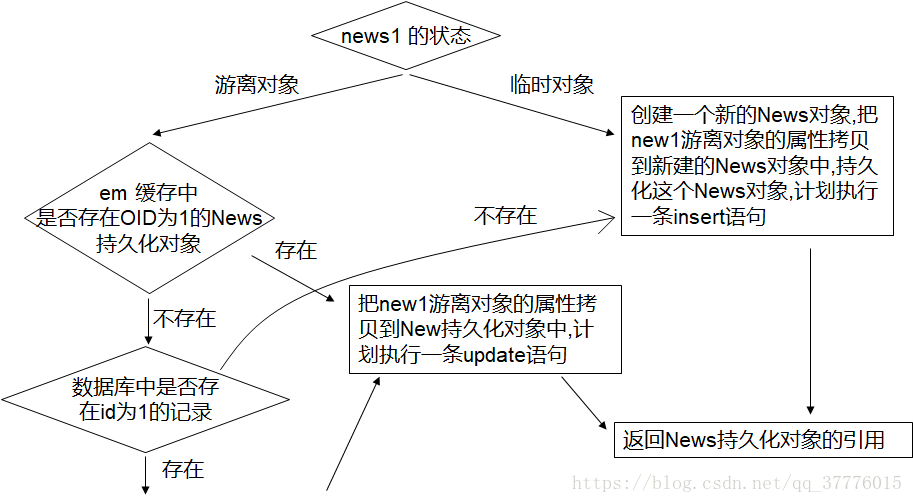

②游离对象和临时对象的区别:游离对象是有设置该对象的id值,而临时对象没有;所以在创建一个new对象并使为持久化对象,不需要向数据库发送一条查询语句,而是直接发送一条插入语句 entityManager.merge(对象引用);
③当游离对象有id值,而缓存和数据库均没有该id的记录,则也是insert;
④对游离对象需要先发送查找语句,后才能执行更新操作
JPA的映射关联关系
1.映射多对一的关联关系
可以在 one 方指定 @OneToMany 注释并设置 mappedBy 属性,以指定它是这一关联中的被维护端,many 为维护端。
在 many 方指定 @ManyToOne 注释,并使用 @JoinColumn 指定外键名称
//映射单向 1-n 的关联关系
//使用 @OneToMany 来映射 1-n 的关联关系
//使用 @JoinColumn 来映射外键列的名称
//可以使用 @OneToMany 的 fetch 属性来修改默认的加载策略
//可以通过 @OneToMany 的 cascade 属性来修改默认的删除策略.
//注意: 若在 1 的一端的 @OneToMany 中使用 mappedBy 属性, 则 @OneToMany 端就不能再使用 @JoinColumn 属性了.
//映射单向 n-1 的关联关系
//使用 @ManyToOne 来映射多对一的关联关系
//使用 @JoinColumn 来映射外键.
//可使用 @ManyToOne 的 fetch 属性来修改默认的关联属性的加载策略
2.映射一对一的关联关系
基于外键的 1-1 关联关系:在双向的一对一关联中,需要在关系被维护端(inverse side)中的 @OneToOne 注释中指定 mappedBy,以指定是这一关联中的被维护端。同时需要在关系维护端(owner side)建立外键列指向关系被维护端的主键列。
//使用 @OneToOne 来映射 1-1 关联关系。
//若需要在当前数据表中添加主键则需要使用 @JoinColumn 来进行映射. 注意, 1-1 关联关系, 所以需要添加 unique=true
//对于不维护关联关系, 没有外键的一方, 使用 @OneToOne 来进行映射, 建议设置 mappedBy=true
双向 1-1 不延迟加载的问题:
如果延迟加载要起作用, 就必须设置一个代理对象.
Manager 其实可以不关联一个 Department
如果有 Department 关联就设置为代理对象而延迟加载, 如果不存在关联的 Department 就设置 null, 因为外键字段是定义在 Department 表中的,Hibernate 在不读取 Department 表的情况是无法判断是否有关联有 Deparmtment, 因此无法判断设置 null 还是代理对象, 而统一设置为代理对象,也无法满足不关联的情况, 所以无法使用延迟加载,只 有显式读取 Department.
3.映射多对多的关联关系
在双向多对多关系中,我们必须指定一个关系维护端(owner side),可以通过 @ManyToMany 注释中指定 mappedBy 属性来标识其为关系维护端。
//使用 @ManyToMany 注解来映射多对多关联关系
//使用 @JoinTable 来映射中间表
//1. name 指向中间表的名字
//2. joinColumns 映射当前类所在的表在中间表中的外键
//2.1 name 指定外键列的列名
//2.2 referencedColumnName 指定外键列关联当前表的哪一列
//3. inverseJoinColumns 映射关联的类所在中间表的外键
@ManyToMany
@JoinTable(name="中间表名称",
joinColumns=@joinColumn(name="本类的外键",
referencedColumnName="本类与外键对应的主键"),
inversejoinColumns=@JoinColumn(name="对方类的外键",
referencedColunName="对方类与外键对应的主键")
)
JPA的二级缓存
在persistence.xml中配置相应的二级缓存信息,如上;
JPA的JPQL语言
* JPQL语言,即 Java Persistence Query Language 的简称。JPQL 是一种和 SQL 非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的 SQL 查询,从而屏蔽不同数据库的差异。
* JPQL语言的语句可以是 select 语句、update 语句或delete语句,它们都通过 Query 接口封装执行
* Query接口封装了执行数据库查询的相关方法。调用 EntityManager 的 createQuery、create NamedQuery 及 createNativeQuery 方法可以获得查询对象,进而可调用 Query 接口的相关方法来执行查询操作。
Query接口的主要方法:
* int executeUpdate()
* 用于执行update或delete语句。
* List getResultList()
* 用于执行select语句并返回结果集实体列表。
* Object getSingleResult()
* 用于执行只返回单个结果实体的select语句。
* Query setFirstResult(int startPosition)
* 用于设置从哪个实体记录开始返回查询结果。
* Query setMaxResults(int maxResult)
* 用于设置返回结果实体的最大数。与setFirstResult结合使用可实现分页查询。
* Query setFlushMode(FlushModeType flushMode)
* 设置查询对象的Flush模式。参数可以取2个枚举值:FlushModeType.AUTO 为自动更新数据库记录,FlushMode Type.COMMIT 为直到提交事务时才更新数据库记录。
* setHint(String hintName, Object value)
* 设置与查询对象相关的特定供应商参数或提示信息。参数名及其取值需要参考特定 JPA 实现库提供商的文档。如果第二个参数无效将抛出IllegalArgumentException异常。
* setParameter(int position, Object value)
* 为查询语句的指定位置参数赋值。Position 指定参数序号,value 为赋给参数的值。
* setParameter(int position, Date d, TemporalType type)
* 为查询语句的指定位置参数赋 Date 值。Position 指定参数序号,value 为赋给参数的值,temporalType 取 TemporalType 的枚举常量,包括 DATE、TIME 及 TIMESTAMP 三个,,用于将 Java 的 Date 型值临时转换为数据库支持的日期时间类型(java.sql.Date、java.sql.Time及java.sql.Timestamp)。
* setParameter(int position, Calendar c, TemporalType type)
* 为查询语句的指定位置参数赋 Calenda r值。position 指定参数序号,value 为赋给参数的值,temporalType 的含义及取舍同前。
* setParameter(String name, Object value)
* 为查询语句的指定名称参数赋值。
* setParameter(String name, Date d, TemporalType type)
* 为查询语句的指定名称参数赋 Date 值。用法同前。
* setParameter(String name, Calendar c, TemporalType type)
* 为查询语句的指定名称参数设置Calendar值。name为参数名,其它同前。该方法调用时如果参数位置或参数名不正确,或者所赋的参数值类型不匹配,将抛出 IllegalArgumentException 异常。
查询:
* from 子句是查询语句的必选子句。
* Select 用来指定查询返回的结果实体或实体的某些属性
* From 子句声明查询源实体类,并指定标识符变量(相当于SQL表的别名)。
* 如果不希望返回重复实体,可使用关键字 distinct 修饰。select、from 都是 JPQL 的关键字,通常全大写或全小写,建议不要大小写混用。
* where子句用于指定查询条件,where跟条件表达式。例:
* JPQL也支持包含参数的查询,例如:
select o from Orders o where o.id = 1
select o from Orders o where o.id > 3 and o.confirm = 'true'
select o from Orders o where o.address.streetNumber >= 123
select o from Orders o where o.id = :myId
select o from Orders o where o.id = :myId and o.customer = :customerName
注意:参数名前必须冠以冒号(:),执行查询前须使用Query.setParameter(name, value)方法给参数赋值。
* 也可以不使用参数名而使用参数的序号,例如:
select o from Order o where o.id = ?1 and o.customer = ?2
其中 ?1 代表第一个参数,?2 代表第一个参数。在执行查询之前需要使用重载方法Query.setParameter(pos, value) 提供参数值
* 如果只须查询实体的部分属性而不需要返回整个实体。例如:
* 执行该查询返回的不再是Orders实体集合,而是一个对象数组的集合(Object[]),集合的每个成员为一个对象数组,可通过数组元素访问各个属性。
select o.id, o.customerName, o.address.streetNumber from Order o order by o.id
更新与删除:
更新:
例:update Customers c set c.status = '未偿付' where c.balance <10000
删除
例:delete from Customers c where c.status = 'inactive' and c.orders is empty