语言模型
语言模型能够计算一段特定的字词组合出现的频率,
比如:”the cat is small” 和 “small the is cat”,
前者出现的频率高
同样的,根据前面所有的字词序列信息,
我们可以确定下一个位置某个特定词出现的频率,
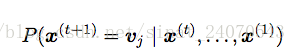
竖线左边表示下一个出现词是v的情况,右边表示前面所有词的组合,
P(…)表示出现这种情况的概率
信息与性能的矛盾
因为一个词前面的信息可能是巨大的,
以往的做法根据每个词前面的n个词来确定,
比如说:100个词,
但是如果关键信息在这n个词的前面,那就会漏掉,
也有人尝试把当前位置之前的所有词都拿出来纳入考虑,
但是这样操作所消耗的内存在实际生产中是不能承受的
为了解决这个问题,RNN就应运而生,
既能够把所有的词纳入考虑,
又有实际的可行性
RNN和隐藏层
RNN语言模型是如何表示出庞大的“前文”信息呢?
RNN创造了一个可以被传递的隐藏层来模拟和储存曾经的“历史“,
隐藏层是一个向量,
每次输入一个词,隐藏层就会把它“吸收”进自己的向量,更新自己,
然后再把这个新的隐藏层传递给下次的计算,
这样就把前文的信息保留在了隐藏层中
RNN的数学表达
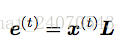
这里的x(t)是one-hot行向量,
L是词向量矩阵(embedding matrix),
所以它们的乘积e就代表当前词
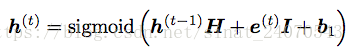
h是隐藏层(hidden layer)向量。
H是权重矩阵,乘以前一个隐藏层,输出一个和隐藏层长度一样的向量,行列都等于隐藏层向量h的长度。
I也是权重矩阵,乘以当前输入的词向量,也输出一个和隐藏层长度一样的向量,列=词向量长度,行=隐藏层的长度
然后把这两结果加起来,再加上一个偏置b,得到新的隐藏层h
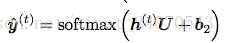
U,权重矩阵,乘以隐藏层,得到一个长度等于词库总数量(V)的向量,
所以U的列数等于隐藏层的长度,行数等于V,
再softmax一下,即得到所有词的概率分布y(t),从此可以预测出下一个最可能的词